 Transformer模型流程图
Transformer模型流程图
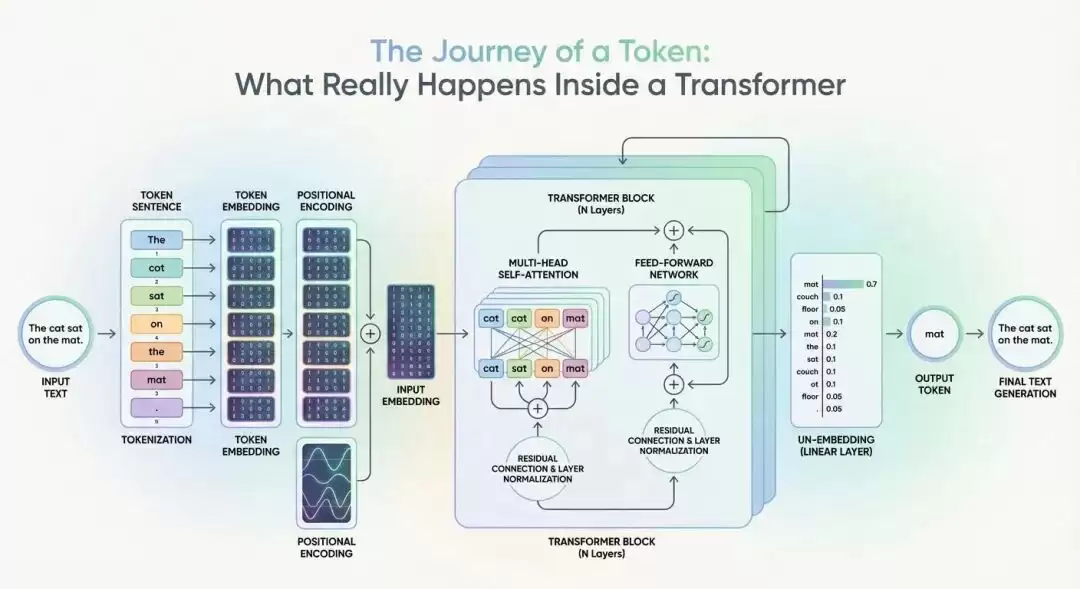
想象一下,你向模型输入“the cat sat on the mat”这句话,希望它能准确预测下一个单词。这个看似简单的动作,实际上完整呈现了Transformer模型内部各组件精密协作的全过程。每个词(即token)在这趟“旅程”中,都会依次经过多个设计巧妙的模块。接下来,我们就沿着数据流动的路径,一步步拆解其中的运作机制。
进入模型前的数据准备
原始文本进入模型的第一步,是将其切分为标准化的token单元,这一步称为分词。现代分词器通常不采用完整的单词切割方式,而是使用更细粒度的子词单元。例如,“cat”可能对应token ID 537,“sat”对应1024。这些分词器内部维护着一个词汇表,规模通常在5万到10万个token之间。
分词完成后,每个token ID需要通过嵌入表查询,转换为高维向量,即词嵌入。假设模型采用768维的嵌入维度,那么“cat”将被表示为一个包含768个浮点数的向量。值得关注的是,经过充分训练后,语义相近的词(如“cat”与“kitten”)在向量空间中的距离会非常接近。
然而,纯词嵌入存在一个本质缺陷:它无法区分“cat sat on mat”和“mat sat on cat”这类语序差异。为了解决顺序信息缺失的问题,模型为每个位置引入了“位置编码”。它利用正弦和余弦函数为每个位置生成独特的向量,并直接叠加到词嵌入上。这样一来,虽然第一个位置的“the”和第二个位置的“cat”是同一个词,但它们当前的向量表示完全不同。
位置编码的数学公式如下:PE(pos, 2i) = sin(pos/10000^(2i/d_model)),以及PE(pos, 2i+1) = cos(pos/10000^(2i/d_model))。经过位置编码后,每个token的768维向量不仅携带了“它是什么词”的语义信息,还包含了“它在句子中的位置”这一结构信息。
Transformer层的内部工作原理
大语言模型通常由12到96个这样的Transformer块堆叠而成。每一层内部都包含两个核心组件。
首先是多头注意力机制,这也是Transformer最具革命性的创新。假设模型配置了12个注意力头,每个头会专注于不同的语言模式:例如第1头可能侧重主谓关系,捕捉“cat”与“sat”之间的关联;第3头可能处理介词短语,识别“on the mat”的结构;而第8头则负责捕获长距离依赖,将句首与句尾的元素联系起来。
注意力的计算逻辑并不复杂:每个token会生成Query、Key、Value三个向量;随后Query与所有其他token的Key进行相似度计算,得到注意力分数;这些分数经过softmax归一化转换为权重,最后用权重对Value向量进行加权求和。最终结果是,例如“cat”这个token的Query向量在与句中所有token的Key向量计算相似度后,如果发现与“sat”的相似度最高,那么“cat”的新表示就会更多地融入“sat”的信息。
多头机制的巧妙之处在于,它使模型能够同时关注多种语言关系。12个头并行工作,每个头输出一个64维的向量(因为768/12=64),最后拼接成一个完整的768维输出。
第二个核心组件是前馈神经网络。注意力机制主要负责信息交换,而FFN负责信息加工。它是一个两层的全连接网络:第一层将768维扩展到3072维(通常是4倍),并使用ReLU激活函数;第二层再将3072维压缩回768维。FFN对每个token独立处理,可以将其理解为对注意力层输出的“深度加工”,它擅长识别复杂的特征组合,例如“动物+动作”这样的语义模式。
最后不能忽略残差连接与层归一化。每个子层(注意力和FFN)都配备残差连接,即输出 = 子层输出 + 输入。这能有效防止信息在深层网络中丢失。层归一化则负责稳定训练过程,避免激活值过大或过小。这两项设计是保证模型能够堆叠至很深层次的关键因素。
多层堆叠的实际效果
12层Transformer的处理过程是逐层递进的。前几层主要聚焦局部语法结构,例如词性、短语边界;中间层开始处理句法关系,如主谓宾结构;后几层则整合语义信息,理解整句话的真实含义。随着层数增加,token的表示也越来越抽象。例如“cat”的向量表示,在第1层后可能仅包含“名词”信息;到了第6层后,可能已经包含了“句子主语”信息;而到第12层后,它已经演化为“执行坐这个动作的猫”这样一个完整的语义概念。
最终预测输出
经过所有Transformer层的处理,每个token都获得了一个极为丰富的768维表示。对于生成任务而言,模型会重点关注最后一个token(这里即“mat”)的表示。
最后一步,线性投影层将该768维向量投影到词汇表大小。假设词汇表包含50257个词,那么这一步的输出就是一个50257维的向量,每个维度对应一个可能的下一个token。此处的权重矩阵,就是词汇表中每个词对应的“解码”向量。
随后,使用Softmax函数对原始分数(也称为logits)进行归一化,将其转换为概率分布。所有概率之和恰好为1。最终的结果可能呈现为:“purred”概率0.15、“meowed”概率0.12、“jumped”概率0.08、“exploded”概率0.0001……模型通常会选择概率最高的token,但有时也会采用采样策略,以增加输出结果的多样性。
整个过程的精妙之处在于,模型学会了将离散的语言符号映射到一个连续的向量空间,在这个空间中执行复杂的几何变换以捕捉语言规律,最后再映射回离散的词汇空间,产生最终的输出。每一个数字、每一次矩阵乘法,背后承载的都是对语言结构深刻而精准的理解。




