音频编辑领域长期被认为是技术门槛较高的任务。专业工具的学习曲线往往非常陡峭,繁杂的参数设置常令人望而却步,普通用户要制作出高质量的音频内容,面临着不小的挑战。
近期,StepFun AI 开源了一款名为 Step-Audio-EditX 的模型,被其称为“全球首个”专注于音频编辑的模型。其核心理念十分直观:通过文字指令操控音频内容。想要AI说话时带有特定情绪?只需输入相应的提示词。想要加入呼吸声或笑声?同样通过文字指令即可完成。用户无需再与复杂的波形图、频率曲线和无数旋钮参数打交道,人机沟通的效率得到了显著提升。

具体具备哪些能力?情感控制方面,支持愤怒、开心、悲伤、兴奋等十余种情绪状态;说话风格则可调整为撒娇、老人、小孩、耳语等多种模式。副语言元素的控制更加精细化——呼吸声、笑声、叹气、疑问语气等共计10种类型均可精准操控。如果需要四川话或粤语方言,只需在文本前添加相应标签即可。
从技术层面来看,该模型采用了3B参数的统一架构,支持中英文及多种方言的零样本语音合成。所谓零样本,即无需预先录制特定人的声音样本,模型能够直接根据文字内容生成或编辑语音。模型采用Apache 2.0开源协议,单张GPU即可运行,12GB显存即可满足基本需求。
 Step-Audio-EditX技术架构图
Step-Audio-EditX技术架构图
模型的架构由三个主要模块组成:双码本音频分词器负责将音频转换为离散token,音频LLM则负责生成token序列,音频解码器最终将这些token还原为音频波形。整个训练流程采用了SFT(监督微调)和PPO(近端策略优化),并支持迭代式编辑——用户可以首先调整语调,随后补充呼吸声,若效果不满意还可回退重新修改。
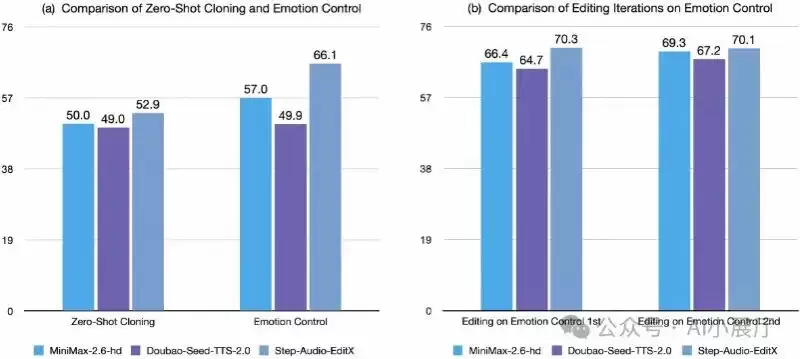
从对比评测数据来看,在零样本语音克隆和情感控制方面,Step-Audio-EditX 的表现优于 MinV2-nd、Double TTS 2.0 等模型。尽管指标数据颇为亮眼,但真正的考验仍在于实际应用场景中的稳定性与最终效果。
部署过程也较为简便。环境要求Python 3.10及以上版本、PyTorch 2.4.1以及CUDA支持。官方提供了Docker镜像,同时附带Web演示界面和命令行工具。若显存资源紧张,还支持INT8和INT4量化,进一步降低了硬件门槛。
“vibe一切”的趋势正在各个领域蔓延。图像生成领域如此,视频生成领域如此,如今轮到了音频。传统的模块化流水线正被统一模型所替代,复杂的参数调节被自然语言指令所取代。技术门槛不断降低,而真正拉开差距的,只剩下“创意”这一核心要素。




