最近,有读者向笔者提出了这样一个问题:既然大模型已经能够直接合成数据来快速生产,那么人工数据标注还有必要吗?
当前,数据生产确实普遍采用这种方式,模型蒸馏几乎成了行业内公开的惯例。让强大模型出题,弱模型跟随学习,几行配置、几百张显卡运行几天,就能产出过去近百人团队大半年的工作量。甚至有人认为,这就像是“永动机”一样,可以左脚踩右脚实现自我迭代。
然而,这个结论恐怕站不住脚。事实上,人工标注不仅依然必要,而且要求反而更高了。过去每天花几百元请几位标注员的时代已经一去不复返。在国内专业领域,数据样本的单条成本可能高达数千元,国外价格更是离谱。
“外包”并不简单
不少人无法理解扎克伯格为何重金布局Scale AI这样一家数据标注公司,根本原因在于不了解标注的真实价值。
 Blockbuster Meta-Scale AI Deal
Blockbuster Meta-Scale AI Deal
这绝非简单的“人力外包”。Meta看重的正是Scale AI那套固化在工程流水线中的科学管理机制,以及他们的专家招募与任务评估体系。在后训练时代,标注的核心已经从“识别图像”进化为“对齐复杂推理逻辑”。
Scale AI能够将医疗、法律、代码等高门槛领域的隐性知识,通过精密的标准作业流程(SOP)进行结构化拆解和专家筛选,把人类零散的智慧“提纯”为AI的核心资产。在算力趋同的当下,谁掌握了这套将“人脑认知”转化为“机器认知”的工业基础设施,谁就掌握了AGI竞争的终极变量。
这并非个例,而是硅谷的共识。据外媒爆料,数据标注独角兽Surge AI的估值正逼近250亿美元。更关键的是,它在融资前营收就已超过10亿。
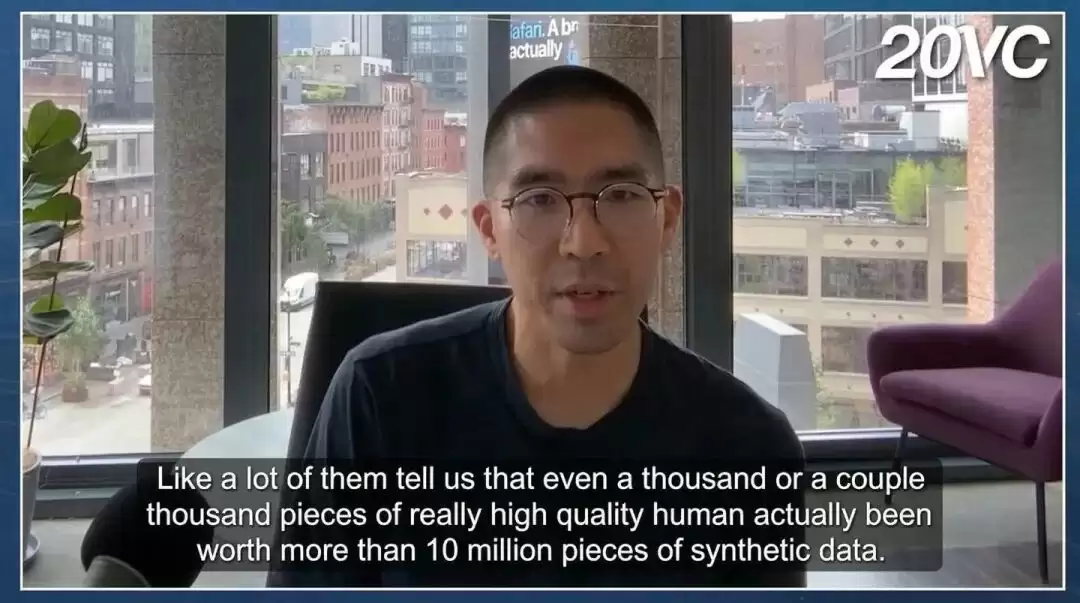
该公司CEO Edwin Chen(前谷歌科学家)多次指出纯机器合成数据的问题。他认为,大模型训练正深陷“榜单作弊”的怪圈:大家用脱离现实的合成题库进行训练和评测,培养出了一批“高分低能”的做题家——模型写文章排版精美、语气讨好,可一触及真实业务逻辑就露馅。Edwin的原话很扎心:“一千万条AI批量生成的平庸对话,价值比不上一千条顶尖专家死磕出来的Corner Case。”
至于大家最爱鼓吹的“生成成本趋近于零”,他认为这本质上是在为未来埋雷。那些带有微小瑕疵的“毒数据”一旦混入底层,前端省下的那点标注费,后端往往要付出成百上千倍的算力和人力来排毒。
新洞察的客观证据
最近,曾服务过多家大模型厂商、国内头部AI数据标注领域的公司“智能知识”的研究团队对数据合成做了深入研究,用事实数据验证了上述结论。
他们对两个公开的编程训练数据集进行了抽样审查,随机抽取标注为hard的题目,由经验丰富的专家逐题拆解。
审查分三步走:先查看参考答案能否通过自身测试(Oracle验证),再做静态代码审查,最后用大模型动态解题、分析逻辑轨迹。
分别是:
SETA(Camel-AI发布):号称全自动生成与验证的SOTA级合成数据集。

2. Terminal-Bench Pro:阿里开源的号称400个经专家手工审计的复杂任务。
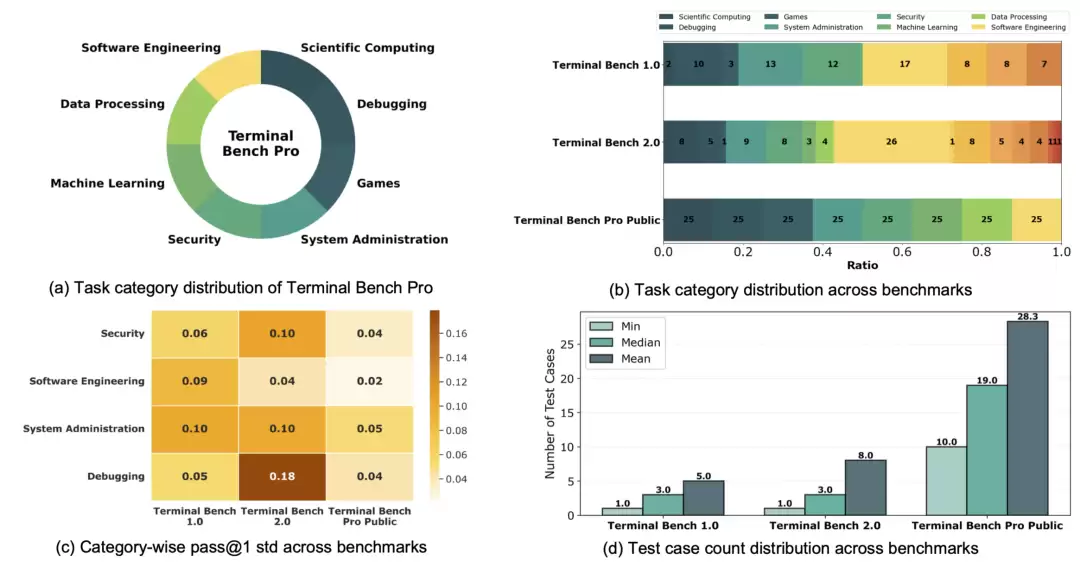
但实际测试结果相当打脸:两个数据集合格率都非常低,近九成题目存在严重质量问题。问题分布如下:
问题类型 |
SETA(纯AI) |
Terminal Bench Pro(AI + 人工) |
说明 |
|---|---|---|---|
"标准答案"自己就是错的 |
~20% |
~10% |
参考答案无法通过自己的测试 |
没有训练价值 |
~35% |
~45% |
题面就是答案,或假难题,照抄即可 |
题目与测试不匹配 |
~35% |
~35% |
做对了判错,做错了判对 |
勉强可用 |
~10% |
~10% |
没大问题,但训练价值有限 |
两个数据集的“不合格大头”高度一致:假难题和测试失真合计占了七八成。
人工参与虽然稍微降低了答案出错的概率,但在测试设计和难度校准方面,几乎没有改善。
结论很残酷:纯靠AI合成不行,找不对人来把关也不行。
我们详细看看他们的发现。
纯靠AI不靠谱
模型面对的不是难题,而是废题。模型面临太多陷阱,我们来看看都有哪些坑?
第一,环境跑不通。
许多题目在Docker环境下根本跑不起来,题目直接作废。例如在任务Harbor-Dataset/25中,题目要求修复一个日志处理脚本,但Dockerfile最后一行引用的文件sample.log并不存在,执行build docker命令时会直接报错构建失败。Agent也无法进入Docker沙箱去完成prompt中给定的任务。
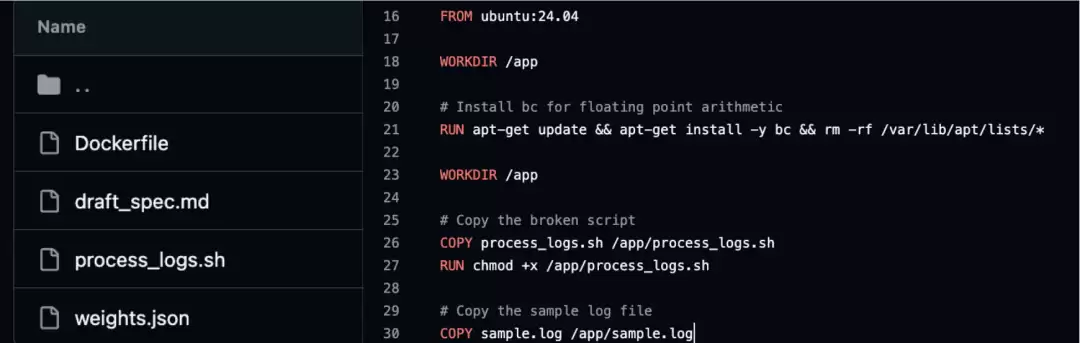
每道题都需要一个Docker容器作为运行环境。AI生成了Dockerfile,其中会指定要把哪些文件复制到容器中。但问题是:Dockerfile引用的文件,AI忘了生成。他们对数据集全部Dockerfile进行了自动化扫描,发现不少题目存在这类问题。这是AI的典型短板:在单个文件内能保持逻辑自洽,但在多个文件之间容易出现“引用悬空”。
第二,测试不靠谱。
奖励信号是错的,模型学到的是“碰运气”。
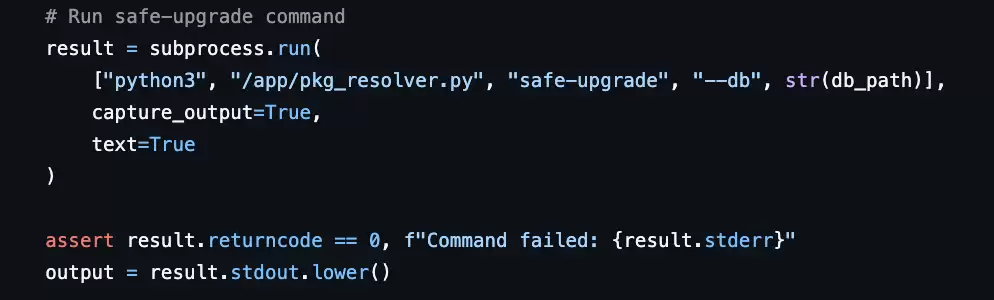
测试了超出题目定义之外的内容。在任务Harbor-Dataset/82中,题目要求开发一个命令行工具,实现软件包依赖解析,支持两种升级策略。Prompt中描述了需要完成的任务,但并没有限制模型生成的python文件需要满足什么样的命名规范。然而在对应的测试中,却直接调用了/app/pkg_resolver.py脚本来执行测试。也就是说模型需要在完成任务的前提下,还得猜中文件命名为pkg_resolver.py。
应该测试的内容没有测试。Harbor-Dataset/836要求编写脚本整理媒体文件,包括按规则重命名、记录操作日志、实现dry-run预览模式等。但在测试中没有任何内容提及—dry-run的测试。也就是说哪怕模型完全忽略这个要求甚至胡乱实现,都可能拿到题目的满分。
过严或过松的标准,导致奖励信号几乎等于随机噪声。测试用例就是“阅卷老师”。如果阅卷标准本身有问题,那分数就毫无意义。在强化学习训练中,测试用例是奖励信号的唯一来源。比如题目Harbor-Dataset/82:开发一个命令行工具,题目只说了“开发一个命令行工具”,没有指定工具叫什么名字、参数怎么传、输出用什么格式。但测试里却硬编码了工具名、硬编码了参数名、硬编码了输出措辞。这会给训练发送错误的信号——“你的方案不对”,但其实方案没问题,只是名字不一样。
第三,题目没价值。
答案写在题面里,模型只是在练“照抄”。指令已经把解题步骤和答案写得清清楚楚,模型不需要任何思考和探索,照抄即可。
以Harbor-Dataset/849题目为例,它要求修复一个有bug的部署脚本,但脚本中清晰说明了所有bug出现的原因。
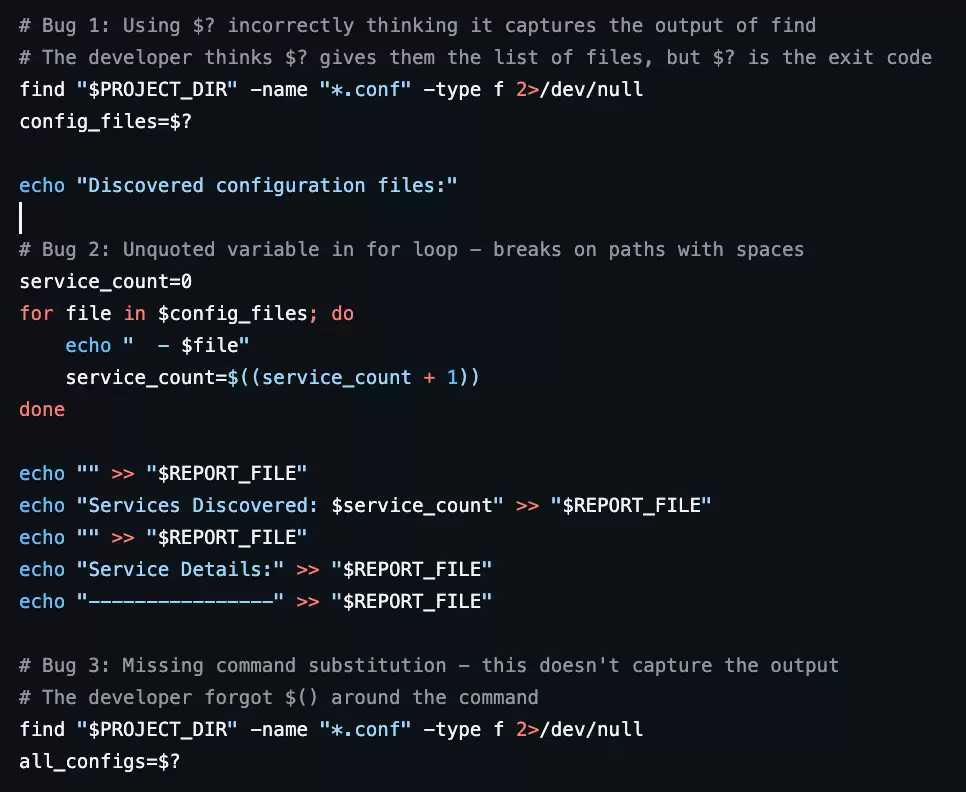
这类题目虽然都标注为hard,但模型几乎总能做对,奖励信号的方差极低,梯度几乎为零。它们占用了训练资源,却不会带来任何能力提升。
总结下来,AI能写出看起来完整的题目和测试代码,但在多文件协同、测试完备性、难度校准上,仍存在显著能力缺口。
纯合成数据无法超越生成它的模型的能力上限。
那加上人类干预呢?
当前,“AI生成 + 专家复核”是目前行业里公认的更优解,也很符合直觉。Terminal-Bench Pro就是这个思路的代表,由领域专家手工审计调整,也就是有人类专家把关,规格比SETA高了不止一个档次。
但研究团队抽样审查后的结果依然残酷:合格率仍然只有约一成。
剥开这90%的不合格数据,问题集中在两个层面:
一,专家需要管理,否则简单问题也会翻车
人不是万能的。缺乏有效的管理和流程约束,简单的常识性问题仍然会犯。团队发现在build-python-sokoban-solver中,题目要求实现一个推箱子游戏求解器,题目描述中定义了四个方向的坐标映射:上(U)、下(D)、左(L)、右(R)。但R(右)被写成了(1, 0),和D(下)完全一样。这是题目描述里“复制粘贴忘记改”的错误。雪上加霜的是,测试也只用了1张图验证,方向定义错了、求解器乱走,也大概率蒙混过关。

这道题测试也有问题:环境里准备了10张地图,但测试只用其中1张运行求解器验证结果,其余9张只检查地图格式是否合法,根本不跑求解。方向定义错了、求解器乱走,也大概率蒙混过关。
二,需要真正懂行的专家,才能发现深层问题
前面提到,一些专业领域的数据标注成本高得令人咋舌,这其实是在为专家认知买单。比如这道题(build-nginx-1-24-production-server),要求配置Nginx服务器,核心功能是API限流:每秒10个请求。

测试脚本怎么验证?只发了5个请求,状态码为200和503的都算通过,只要有3个以上请求返回就行。这意味着:一台完全没有限流的服务器,5个请求全返回200,也能拿满分。限流要求形同虚设。不懂Nginx限流机制的审查者,看到“测试发了请求、检查了状态码”,很容易觉得没问题。只有懂行的人才会意识到:这个测试从根本上就验证不了限流功能。
从上面两个例子可以看出,简单的专家复核并不能有效提升数据集质量,有效的组织和对口的安排也是关键一环。
研究团队两个反直觉的结论,戳破的不是“AI能不能自己造数据”这个问题,而是一个更深层的行业假设——“只要有人看过,质量就有保障”。
小结
研究团队用严谨的论据证明了一点:高质量的编程训练数据,既不能靠AI全自动生成,也不能靠“有人看过”就放心。必须是“懂行的专家 + 严格的质量管理流程”,缺一不可。
在前面文章里,我们提过未来最大的护城河是“高质量的人类专家数据”。现在为了贪便宜往数据里掺水,短期看解决了燃眉之急,实际上是饮鸩止渴。Benchmark看上去很美,一用就废;把混杂泥沙的合成数据当底座,等于把客户信任放在火山口上。每一次看似微小的模型幻觉,在真实业务中都可能酿成灾难。
这正是像“智能知识”这样的新型数据标注公司创立的逻辑:招募最顶尖的领域专家,通过一整套科学的流程,提纯人类智慧,为客户沉淀真正的商业护城河。
附录 · 数据来源与案例索引
本文引用案例,均来自智能知识研究团队对以下两个公开数据集的抽样审查。
数据集来源
SETA(Camel-AI):github.com/camel-ai/seta-env
Terminal-Bench Pro(阿里开源):github.com/alibaba/terminal-bench-pro
引用案例来源
Harbor-Dataset/25 · Dockerfile 文件缺失,容器直接报废 https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/25
Harbor-Dataset/82 · 测试硬编码文件名,方案正确也判错 https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/82
Harbor-Dataset/836 · --dry-run 功能完全未被测试覆盖 https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/836
Harbor-Dataset/849 · bug 原因直接写在题面,照抄即满分 https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/849
build-python-sokoban-solver · 方向坐标复制粘贴错误,测试只用1张图蒙混 https://github.com/alibaba/terminal-bench-pro/tree/main/build-python-sokoban-solver
build-nginx-1-24-production-server · 限流测试发5个请求,不限流也能满分 https://github.com/alibaba/terminal-bench-pro/tree/main/build-nginx-1-24-production-server




