李飞飞如今把目光锁定在空间智能领域——这可以说是人工智能最难啃的骨头之一。
在她看来,3D世界建模是实现通用智能不可或缺的一环。她放话说:目标是打造一个能超越平面像素、跨越语言障碍、真正捕捉三维世界结构和空间智能的世界模型。

在这次对话中,她从ImageNet的起源讲起,一路聊到AI范式的转变与关键突破,还谈到了3D建模的挑战和空间智能领域的数据缺失问题。
以下是这场对话的核心内容整理——都是李飞飞近期的思考结晶。
ImageNet为现代计算机视觉搭建数据骨架
Q:你最早的项目之一是2009年的ImageNet,距今已经16年了。那篇文章引用超过8万次,真正抓住了AI的一个关键问题——数据。讲讲这个项目是怎么产生的吧,在当时那绝对是开创性的工作。
李飞飞:其实构思ImageNet,已经是近18年前的事了。那时我在普林斯顿当助理教授,AI和机器学习的世界跟现在完全不一样。数据少得可怜,至少计算机视觉领域是这样,算法根本跑不动——也谈不上什么产业。你知道的,就大众认知而言,“AI”这个词基本不存在。

但我们这群人——从AI的创始人开始算起,然后是John McCarthy、Geoffrey Hinton这帮人——一直都在做一个人工智能的梦:让机器能思考、能行动。而我个人的梦想,就是让机器能够看见。因为看见是所有智能的基础。
视觉智能不只是感知,它的核心是理解世界并在世界中行动。我痴迷于让机器看见这件事。当时我拼命地开发机器学习算法,试过神经网络,没成功,然后又转向支持向量机。
但有个问题始终困扰着我:泛化。如果你做机器学习,你必须知道,泛化是机器学习的数学基础和终极目标。要实现泛化,算法需要数据。可当时计算机视觉领域根本没有数据可用。而我算是第一批开始接触数据的研究生,因为正好赶上了互联网和物联网爆发的时代。
时间快进到21世纪,大概2007年前后,我和我的学生决定,必须赌一把大的:赌机器学习需要一次范式转变,而这个转变必须由数据驱动。但问题在于,当时根本没有数据。
于是我们就想:好,那就去互联网上下载十亿张图片——那是当时能搞到的最大数量——然后构建一个覆盖整个世界的视觉分类体系,用这些数据来训练和评估机器学习算法。这就是ImageNet诞生背后的逻辑。
自然语言与视觉信号的融合,让智能体能够讲述世界的故事
Q:后来过了挺长时间,才慢慢出现有前景的算法,直到2012年AlexNet出现,这才凑齐了通往AI的第二个关键要素——计算能力,以及足够的资源投入。跟我们说说,你是什么时候意识到“用数据播种”这招开始见效的?就是那个你发现整个AI社区在这个基础上开始取得突破的时刻。
李飞飞:2009年,我们发了一篇很小的CVPR海报。从2009到2012年那三年里,我们虽然坚信数据能驱动AI,但几乎没收到什么正面信号。所以我们做了一些事。其中一件就是开源。从一开始我们就被信这条:必须把这个项目开源,让整个研究圈都能参与进来。
另一件事,是搞了一个挑战赛。我们想让全世界最聪明的学生和研究者都来解决问题。这就是ImageNet挑战赛。每年发布一个测试数据集,公开邀请所有人来参与。头几年其实是在建基线——当时识别错误率在30%左右徘徊,虽然不是完全乱猜,但也确实不太行。

到了第三年,也就是2012年——我在自己的一本书里写到过这个——记得那会儿夏天快结束了,我们正在处理挑战赛的所有结果。有一天深夜,我收到研究生的消息,说有个结果特别离谱,让我赶紧去看。我们仔细一查,是卷积神经网络之类的东西。
当时Geoffrey Hinton的团队,还不叫AlexNet,他们给这个东西取名叫“SuperVision”——既是“超级视觉”的意思,也暗指“监督学习”,挺有巧思的一个双关。
我们仔细研究了一下,那其实是个老算法——卷积神经网络80年代就有了,但他们在算法上做了些改进。看到这种飞越式的变化,说实话还挺让人吃惊的。后来在佛罗伦萨的ICCV挑战研讨会上,我们展示了这个结果,Alex Krizhevsky和很多研究者都来了。
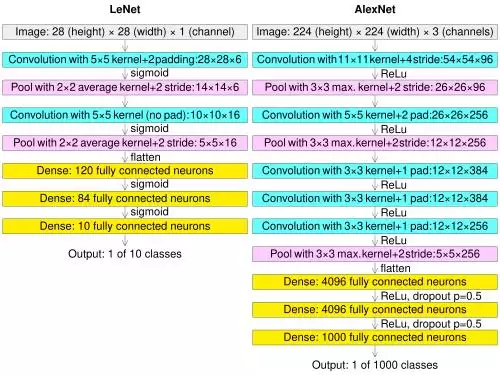
如今这个时刻已经被写进历史了,被称为“ImageNet挑战赛的AlexNet时刻”——这不只是卷积神经网络的一次应用,更是Alex团队首次将两块GPU并联用于深度学习计算。所以说,数据、GPU和神经网络,第一次在这一刻合体了。
Q:顺着计算机视觉智能的发展路径,ImageNet成了解决物体识别问题的关键。紧接着,AI也开始能够解析视觉场景了。你和你的学生,比如Andrej Kaparthy,做了很多重要工作,让AI第一次实现了场景描述能力。聊聊从物体到场景这一步的转变吧。
李飞飞:ImageNet解决的核心问题是:当系统收到一张图像,能准确识别出里面的东西——比如“这里有只猫”“那是把椅子”。这是视觉识别中的一个基础问题。
从我研究生进入AI领域开始,我就有一个梦想——我认为这是个长达一百年的梦想:让智能体能够讲述世界的故事。当你走进一个房间睁开眼睛,你看到的不是一个个孤立的“人、椅子、椅子、椅子”,而是整个会议室——有屏幕、有舞台、有人、有观众、还有摄像机……你能描述自己看到的整个场景。这是人类视觉智能的基本能力,对我们的日常生活至关重要。
所以我觉得这个问题会困扰我一辈子。字面意义上的。我研究生毕业时告诉自己:如果能在闭眼之前创造一个能描述场景故事的算法,我的人生就圆满了。

随着AlexNet时刻的到来,深度学习爆发了。Andrej和后来的Justin Johnson进入我的实验室后,我们开始观察到自然语言和视觉信号融合的苗头。后来我和Andrej提出了给图像加字幕或者讲故事的问题。长话短说,2015年左右,Andrej和我发了一系列论文,同时期也有一批类似的研究——关于制造一台可以为图像加字幕的计算机。那时我的感受是:天啊,我这辈子还能干嘛?那曾是我一生的目标。对我们两个人来说,那都是难以置信的时刻。
去年我做了一个TED演讲,还引用了Andrej几年前完成图像字幕工作时发的推文。我跟他开玩笑说:“嘿Andrej,我们反其道而行之,拿一句话生成一张图怎么样?”他当然知道我在开玩笑,说:“哈哈,我撤了~这个世界还没准备好。”快进到今天,大家都知道生成式AI了,现在一句话就能生成漂亮的图片。所以说,AI的发展速度不可思议。
个人觉得我是世界上最幸运的人——我的整个职业生涯,正好始于AI寒冬末期,也就是AI开始起飞的时候。而我自己的工作,自己的职业生涯,很大一部分都参与了这场变革,或者为它助了一把力。很幸运,也很自豪。
没有空间智能,通用智能就不完整
Q:我觉得最疯狂的是,即便你已经实现了毕生梦想——描述场景,甚至用扩散模型生成它们——你竟然还在梦想更大的事。计算机视觉的演进,从物体到场景,现在这个概念变成了整个世界。而你决定从学术界出来,从教授变成World Labs的创始人和CEO。说说吧,有什么比识别物体更难?
李飞飞:要总结过去五六年的经历真的很难。我们正活在一个文明级的科技爆发时刻。作为计算机视觉科学家,我们见证了从图像识别到图像描述、再到用扩散技术生成图像的惊人发展,这一切都在以一种令人振奋的方式发生。

还有一个同样令人兴奋的领域是语言——大语言模型。2022年11月,ChatGPT打开了那扇真正能通过图灵测试的生成模型的大门。这个进展非常鼓舞人心。就算像我这种年纪的人,也会大胆地思考未来会怎样。
作为一个计算机视觉科学家,我有一个习惯——很多灵感来自进化论和脑科学。在我的职业生涯中,我经常寻找下一个要解决的目标。我问自己:进化论做了什么?大脑发育做了什么?有一点很值得关注:宽泛地说,人类语言的进化发展大约花了3到5亿年,还没到十亿年。而且基本上只有人类拥有复杂的语言。当然,你可以争论动物有没有语言,但就语言作为交流、推理、抽象的工具而言,真正拥有它的是人类,这花了不到5亿年。
但再想想视觉,想想理解三维世界的能力:弄明白在这个三维世界里该做什么、怎么导航、怎么互动、怎么理解、怎么交流……这个进化持续了5.4亿年。5.4亿年前,最早的的三叶虫在水下进化出了视觉感知能力。正是视觉的出现,引爆了这场进化的军备竞赛。在视觉诞生前的五亿年里,地球上的生物都极其简单。而在随后的5.4亿年里——正是因为生物获得了观察世界、理解世界的能力——进化竞赛正式开打,动物智能开始相互竞争。

所以对我来说,解决空间智能的问题——如何理解三维世界、生成三维世界、推理三维世界、在三维世界里做事——是人工智能的基本问题。没有空间智能,通用人工智能就不完整。我要解决这个问题:创造一个超越平面像素、超越语言的创造性世界模型,一个真正能捕捉三维世界结构和空间智能的世界模型。
我这辈子最幸运的事,就是不管多大年纪,总能和最优秀的年轻人共事。所以,我和三位了不起的年轻世界级技术专家——Justin Johnson、Ben Mildenhall和Christoph Lassner——共同创立了一家科技公司。我们准备去解决当下AI领域里最困难的问题。
Q:这几个人的天赋令人难以置信。Chris是Pulsar的创造者,Pulsar又是Gosh和Splats的雏形,能做大量可微渲染;你的前学生Justin Johnson工程思维超级强,实现了实时神经风格迁移;Ben是Nerf的作者。这绝对是一支超级精锐团队,而你正需要这样的团队。我们之前简单聊过——实际上,视觉任务在某些方面比大语言模型更难。当然,这话说出来可能有争议。毕竟大语言模型基本上是一维的,而你要做的是理解三维世界的结构。为什么这件事这么难,而且进展比语言研究慢很多?
李飞飞:谢谢你能体会我们这个问题有多难。哈哈。语言本质上是一维的,对吧?音节按顺序排列,所以序列到序列、序列建模才那么经典。语言还有一些人们没意识到的东西:语言纯粹是生成性的。自然界不存在语言,你摸不到也看不见它。语言来自每个人的大脑,是一种纯粹的生成信号——当然,你把它写在纸上,它就有了实体。
但语言的生成、构建和效用非常具有创造性。现实世界比这复杂太多了。首先,现实世界是3D的。如果加上时间,那就是4D了。但先局限于空间吧——世界本质上是3D的,这本身就是一个组合复杂得多的问题。
其次,视觉对世界的感知和接收是一种投射:不管是你的眼睛、视网膜还是相机,它总是把3D转换成2D。你得明白这有多难——从数学角度说,这根本上就是个不可能完美解决的问题。这就是为什么人类和动物需要多个传感器。
第三,世界并不完全是生成性的。我们可以生成虚拟的3D世界,但它仍然得遵守物理规律等。但外面同样存在一个真实的世界。现在虚拟世界突然以一种非常流畅的方式在生成和重建之间切换,而且用户行为、实用性、使用场景也大不相同。如果你把时间拨到当代,我们可以聊聊游戏、元宇宙之类的话题;如果你一路拨入现实世界,就会发现我们在谈论具身智能等东西。但这一切都处在一个世界建模和空间智能的连续体上。

一个显而易见却常被回避的问题是:互联网上充斥着海量的语言数据。但空间智能的数据在哪里呢?当然,这些信息都存在于人类的大脑中,但它的获取不像语言那么容易。这些都是它如此困难的原因。但坦白说,这让我兴奋——如果它很容易,别人早就解决了。我整个职业生涯都在追逐那些极其困难、近乎疯狂的问题。我觉得,这恰好就是我接下来要解决的那个疯狂问题。
Q:即使从最基本的原理来思考,人类大脑视觉皮层处理数据的神经元数量也远多于处理语言的神经元数量。人脑的这种架构和当前的大语言模型有本质区别,你也在逐渐意识到这一点,对吧?
李飞飞:这其实是个非常好的问题。现在仍然有很多不同的观点。我们在大语言模型中看到的很多内容,实际上是一种写作行为——通过写作技巧,将故事拓展到完美的结局,你几乎可以一路通过暴力手段实现自监督学习。
而建设性的世界模型可能会更复杂一些。世界更结构化,可能需要我们提供一些更精细的引导信号——你可以把它看成一种先验形式,或某种数据监督。
我认为这些都是我们必须解决的一些开放性难题。而且,我们甚至都还没完全理解人类的所有感知。我们还没有解决“3D在人类视觉中如何运作”这个问题。虽然从机械原理上,我们用眼睛对物体进行三维测量,但在此之后,真正的数学模型又在哪里呢?
人类并不像一些动物那样天生擅长3D处理。所以还有很多问题有待解答。我只指望一件事:期待最聪明的人来解决它。

Q:那是否可以说,你们World Labs正在构建的是一个全新的基础模型,它的输出是3D世界?你们设想的应用场景有哪些?你已经列出了从感知到生成的所有内容,但生成模型和判别模型之间始终存在张力。那么,这些输出的3D世界到底能用来做什么?
李飞飞:在空间智能这个领域,它和语言模型一样,从创作的角度来看,应用前景非常广泛。比如,可以当设计师、建筑师、工业设计师,也可以是艺术家。再拓展到创作、游戏开发、机器人、机器人学习等方面,空间智能模型或者说世界模型的实用性非常大。
实际上,我对元宇宙非常感兴趣。我知道很多人觉得它不管用,我也知道它目前确实还无法正常工作。但我认为硬件和软件的融合正在到来,这是未来另一个绝佳的使用场景。
Q:我个人对你正在解决元宇宙的问题感到非常兴奋,因为我在之前的公司也尝试过这个方向。
李飞飞:我认为硬件是目前元宇宙障碍的一部分。在元宇宙中需要内容生成,而内容生成需要世界模型。
思想上要有无畏精神
Q:对一些观众来说,你从学术界到创始人兼CEO的转变可能看起来很突然。但实际上你一生有着非凡的经历,这也不是你第一次从0到1了。当年移民到美国时,还是个青少年,不会说英语,却开了好几年洗衣店。跟我们讲讲这些经历如何塑造了现在的你。
李飞飞:我当时19岁,需要去普林斯顿学物理,但要养家糊口,于是开了一家还不错的干洗店。用硅谷的话说,我开始筹集资金了。
我做过创始人、CEO,也做过收银员。但无论如何,我看着你们觉得特别激动——你们的年龄差不多只有我的一半,甚至只有30%,却又如此优秀。你们放手去做想做的事就好了。
我刚当教授的时候,也是不顾很多人的反对,去了那些我是第一个计算机视觉教授的学院。虽然我知道,作为一名年轻教授,我本应该去那些有学术氛围和资深导师的地方。当然,我也希望有资深导师。如果没有,我就自己开路,闯出一片天。我不害怕。
后来我去了谷歌,学到了很多企业层面的东西。然后在斯坦福创办了一家初创公司。大约2018年,AI成了全人类的问题。人类不断推动科技进步,但我们不能丢掉人性。我很在意AI发展进程中的积极导向——我想让AI以人为中心,造福人类。
于是我回到斯坦福创立了以人为本AI研究院(HAI),运营了5年。可能有些人不理解,但我很自豪。某种程度上,我觉得自己就是喜欢做“企业家”这件事。
我喜欢那种一切归零的感觉——就像站在零点,忘掉过去做过的一切,不在乎别人对你的看法,埋头苦干,努力建设。那是我的舒适区。
Q:除了做了那么多令人赞叹的事情之外,你还有一个非常了不起的地方:你指导了很多传奇般的研究人员——比如Andrej Kaparthy、英伟达的Jim Fan、和你一起做ImageNet的邓嘉——他们在后来都取得了非凡的职业生涯。他们当学生的时候,最突出的特质是什么?
李飞飞:首先,我是个幸运的人。对我来说,学生的意义甚至更大——他们真的让我变成了更好的人、更好的老师、更好的研究者。如你所说,能和这么多传奇般的学生共事,是我一生的荣幸。
他们每个人都很不一样。有些是纯粹的科学家,埋头解决科学问题;有些是行业领袖;有些则是最伟大的AI知识传播者。但我觉得,有一件事可以把他们统一起来。
我鼓励他们每个人都思考一下这个问题——这也是我给正在招聘的创始人的建议,包括我自己的招聘标准:我寻找的是思想上的无畏精神。
我觉得不管你来自哪里、不管我们要解决什么问题,都不重要。那种勇于接受困难之事、全力以赴、想尽办法解决问题的勇气和无畏精神,是成功人士的核心特质。我从他们身上学到了这一点。现在作为World Labs的CEO,我在招聘时也会寻找具备这种特质的人。
Q:所以你们也在为World Labs大量招人。
李飞飞:是的。我们正在招工程人才、产品人才、3D人才、生成模型人才。如果你觉得自己无所畏惧,而且对解决空间智能问题充满热情,那就来找我聊聊,或者访问我们的网站。
通过梯度下降法找到生活最优解
观众1:嗨,飞飞,我是你的超级粉丝。我的问题是:二十多年前,你从事过视觉识别方面的工作。如果我现在想开始攻读博士学位,应该选什么方向,才能像你一样成为传奇人物?
李飞飞:虽然我可以说“做任何让你兴奋的事”,但我更想给你一个深思熟虑的回答。首先,AI研究已经变了——学术界不再是AI资源的主要占有者,这和我那个时候大不一样。芯片、算力、数据这些资源,在学术界确实非常匮乏。
作为一名博士生,我建议你去找那些不需要靠更好计算、更好数据就能更好解决的问题的团队。在学术界,我们仍然可以发现一些非常根本性的问题——不管你有多少芯片,都能取得很大进展。
其次,跨学科AI是学术界一个非常令人兴奋的领域,尤其是在科学发现方面。太多学科可以和AI交叉了,我认为这是理论研究方面一个大有可为的方向。

有意思的是,AI能力已经100%超越了理论——我们不知道怎么做、缺乏可解释性、不知道如何找出因果关系、有太多事情无法理解……所以人们可以继续往前推。
这个清单可以一直列下去。在计算机视觉领域,仍然有一些我们尚未解决的表征问题。另外,小数据也是个非常有趣的领域。这些都是可能性。
观众2:再次祝贺你拿到耶鲁大学的荣誉博士学位。一个月前,我有幸在那里见证了这个时刻。我的问题是:在你看来,AGI更有可能以统一模型的形式出现,还是作为多智能体系统?
李飞飞:你提问的方式本身就已经给出了两种定义。一种定义更理论性——如果存在一个智商测试,通过测试就可以定义为AGI;另一个定义则更具功能性——如果它基于智能体,它有哪些功能?能执行哪些任务?
老实说,我对AGI的定义也很困惑。1956年在达特茅斯聚会的那群AI先驱——John McCarthy、Marvin Minsky这些人——他们想要解决的是机器思考的问题。而这是图灵早在10年前就提出的问题。在那个语境里,它不叫“狭义AI”,就是一种关于智能的表述。
所以我也不太清楚如何区分“AI”和这个新词“AGI”的定义。对我来说,它们是一回事。但我理解,现在的行业喜欢把AGI称为超越AI的东西。我对此挺困惑的,因为我不知道AGI和AI到底有什么区别。
如果说现在的AGI系统比80年代、70年代、90年代或其他时期的狭义AI系统表现更好,那我认为这只是这个领域在进步。但从根本上说,我认为AI的规模就是智能的规模——我们要创造的是能像人类一样智能、甚至比人类更智能地思考和做事的机器。
我不知道怎么定义AGI,不定义它,我也不知道它到底是单一的还是一个系统。你可以把大脑看作一个整体,但它确实有不同的功能——有专门的语言区域、视觉皮层、运动皮层。所以这个这个问题我真的不知道怎么回答。
观众3:看到一位女性在这个领域发挥主导作用真的很鼓舞人心。我想问:在AI迅速崛起的当下,你作为一名研究者、教育者和企业家,觉得什么样的人应该去读研究生?
李飞飞:这是个很棒的问题。连家长都经常来问我。我认为研究生阶段是一段有着强烈好奇心的4到5年。你被好奇心引领着。那种好奇心非常强烈,以至于没有比这更好的时期来满足它。
读研究生和创业不同——创业不能仅仅靠好奇心引领,否则你的投资者会生气的。一家有明确商业目标的创业公司,一部分动力来自好奇心,但不止是好奇心。
但对基层人员来说,解决问题的好奇心、提出正确问题的好奇心,是很重要的。我认为那些带着强烈好奇心投身其中的人,会享受这段研究生时光。即使外界在以光速变化,你仍会感到快乐,因为你在那里追寻着那份好奇心。
观众4:你提到开源是ImageNet发展的重要组成部分。而现在,随着大语言模型的最新发布,我们看到各个组织在开源方面采取了不同的做法。有些完全闭源,有些完全公开整个研究栈,有些则卡在中间——开放权重或用限制性许可。你怎么看这些不同的开源方法?你认为作为AI公司,正确的开源方式应该是什么?
李飞飞:我并不是那种拘泥于“必须开源”或“必须闭源”教条的人。这完全取决于公司的业务战略。
比如,Facebook和Meta选择开源,原因很明显:他们目前的商业模式并不是通过卖模型来盈利。他们是在利用开源发展生态系统,让人们来到他们的平台。所以开源很有意义。
其他公司通过开源或闭源赚钱。所以我对这个问题挺开放的。我认为开源应该受到保护。如果公共部门(比如学术界)和私营部门都有开源,那对创业生态系统非常重要。
观众4:我还有一个关于数据的问题:你现在在研究世界模型。你之前指出了机器学习向以ImageNet为代表的数据驱动方法的转变,并且提到互联网上没有空间数据,它只存在于我们的大脑里。那么你是怎么解决这个问题的?是从现实世界收集数据?用合成数据?还是相信那些古老的先验知识?谢谢。
李飞飞:你应该加入World Labs,我会告诉你的。
作为一家公司,我没办法透露太多。但我承认我们正在采取混合方式。有大量数据当然重要,但拥有大量高质量数据同样重要。说到底,如果不注意数据质量,还是会出现“输入垃圾,输出垃圾”的情况。
观众5:在你的书《我看见的世界》中,你提到了作为移民女孩和女性在STEM领域面临的挑战。我很好奇,你是否有过在工作场所感觉自己是个少数群体的时刻?如果有,你是怎么克服这种情况或者说服他人的?

李飞飞:谢谢你的问题。我想非常谨慎地回答你,因为我们来自不同的背景,每个人的感受都很独特。其实,我们是什么人并不重要——每个人都曾有过感觉自己是个“少数人”的时刻。
有时候这取决于我是谁,有时候基于我的想法,有时只是因为衬衫的颜色之类的。但这也是我想鼓励大家的地方——从小来到这个国家,我已经检验了这件事的本质。作为一名移民女性,我几乎培养出了一种不过度关注此事的能力。和你们每个人一样,我来这里是为了学习、做事或创造。
在访谈的最后,李飞飞给所有年轻人送上了美好的祝愿:
你们即将踏上征程,或者已经在路上了。你们会有脆弱的时刻,也会遇到奇怪的事。在创业过程中,我每天都有这样的感受——有时候我会想:“天哪,我不知道自己在做什么。”但没关系,只管专注去做,通过梯度下降法找到最优解。




