大模型的架构,到了需要变革的时候?
不妨先问一个问题:当大语言模型(LLM)面对复杂推理任务时,当前的主流方案是什么?答案是思维链(CoT)。但这类方法并非没有短板——任务分解过程繁琐、对数据的需求巨大,而且在生成过程中延迟相当可观。那么,有没有更接近大脑运作机理的替代方案?
Sapient Intelligence 的研究者最近给出了一个思路:他们从人脑的分层结构和多时间尺度处理机制中汲取灵感,提出了一种全新的循环架构——分层推理模型(HRM)。这种架构的特别之处在于,它能在保持训练稳定性和效率的同时,实现颇高的计算深度。
具体来说,HRM 通过两个相互依赖的循环模块,在单次前向传递中完成顺序推理,整个过程不需要对中间步骤进行明确的监督。其中一个高级模块负责缓慢、抽象的规划,另一个低级模块则担纲快速、细致的计算。更令人眼前一亮的是,这个模型仅包含 2700 万个参数,并且只用了 1000 个训练样本,就完成了复杂的推理任务。
它既不需要预训练,也不需要任何 CoT 数据。在充满挑战性的数独谜题和大型迷宫的最优路径查找任务中,HRM 交出了近乎完美的答卷。在抽象与推理语料库(ARC)——这一衡量通用人工智能能力的关键基准上,它甚至胜过了上下文窗口明显更长的大模型。
从这些结果来看,HRM 确实有潜力推动通用计算层面上的变革性进步。

论文题目:Hierarchical Reasoning Model
论文链接:https://arxiv.org/abs/2506.21734
下图更直观地说明了它的性能:左图揭示了 HRM 的灵感来源——大脑的层级处理与时间分离机制,两个在不同时间尺度上运行的循环网络协同作战。右图则展示了,仅凭约 1000 个训练样本,HRM(约 2700 万个参数)就在归纳基准测试(ARC-AGI)和极具挑战性的符号树搜索谜题(Sudoku-Extreme、Maze-Hard)上超越了最先进的 CoT 模型——而那些 CoT 模型则在同样的任务上完全失败。HRM 采用随机初始化,无需思维链,直接根据输入完成任务。
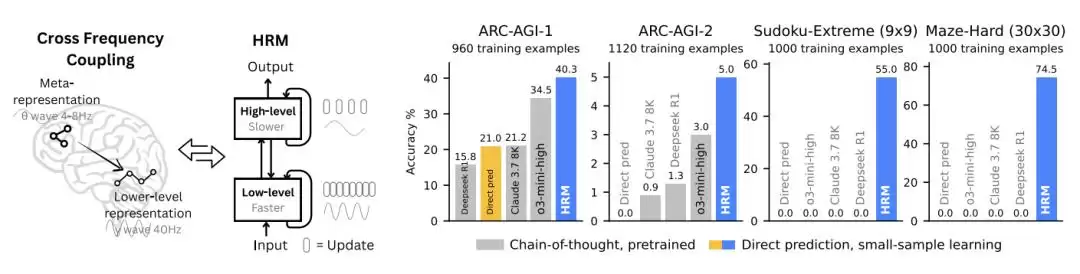
分层推理模型
为什么复杂推理需要深度?
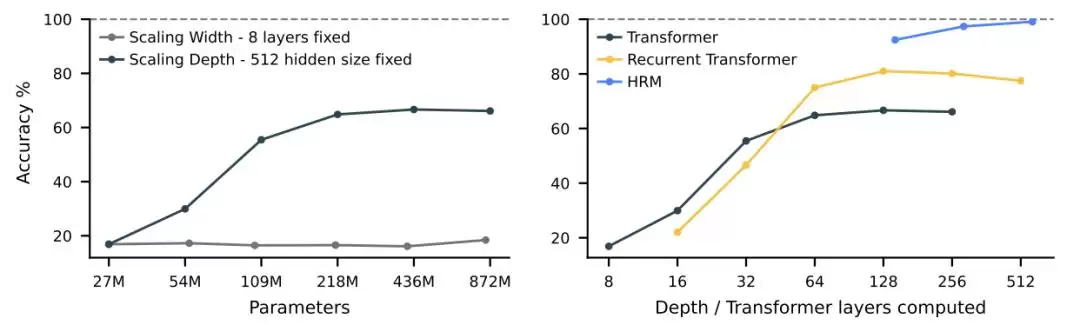
下图可以说明一些问题。左图显示,在需要大量树搜索和回溯的 Sudoku-Extreme Full 任务上,增加 Transformer 的宽度并不能带来性能提升,而深度才是关键。右图则揭示了一个更核心的问题:标准架构已经“饱和”了,它无法从进一步增加深度中获益。HRM 克服了这一根本性的限制,靠有效利用计算深度实现了近乎完美的准确率。
HRM 的核心设计灵感来自大脑的两个关键特征:分层结构和多时间尺度处理。具体说来包括:
- 分层处理机制: 大脑通过皮层区域的多级层次结构处理信息。高级脑区(如前额叶)在更长的时间尺度上整合信息并形成抽象表示,而低级脑区(如感觉皮层)则处理即时、具体的感知运动信息。
- 时间尺度分离: 这些层次结构的神经活动具有不同的内在时间节律,体现为特定的神经振荡模式。这种时间分离机制使得高级脑区能稳定地指导低级脑区的快速计算过程。
- 循环连接特性: 大脑拥有密集的循环神经网络连接。这种反馈回路通过迭代优化来提升表示的精确度和上下文适应性,但需要额外的处理时间。值得注意的是,这种机制能有效规避反向传播时间算法(BPTT)中存在的深层信用分配难题。
从组件上看,HRM 包含四个可学习的部分:输入网络 f_I (・; θ_I),低级循环模块 f_L (・; θ_L),高级循环模块 f_H (・; θ_H),以及输出网络 f_O (・; θ_O)。
HRM 将输入向量 x 映射到输出预测向量 y´。首先,输入 x 被网络投影成一个表示
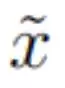
:
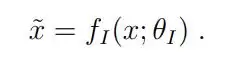
模块在一个周期结束时的最终状态为:
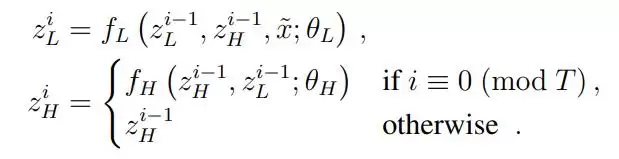
最后,在经过 N 个完整周期后,从 H 模块的隐藏状态中提取预测
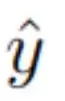
。
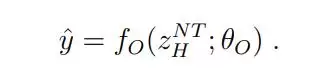
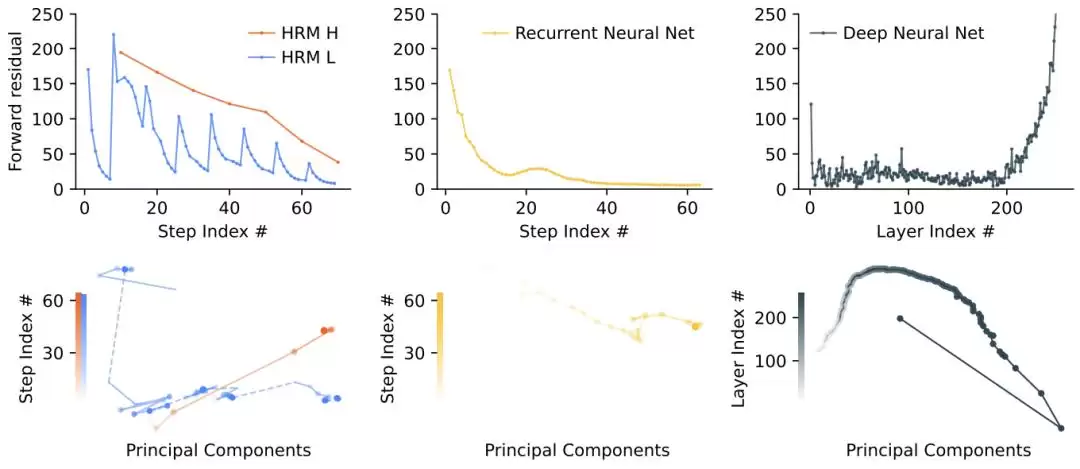
HRM 表现出一种层级收敛性:H 模块稳定收敛,而 L 模块在周期内反复收敛,然后被 H 重置,导致残差出现峰值。相比之下,循环神经网络收敛速度很快,残差迅速趋近于零;深度神经网络则经历梯度消失,显著的残差主要出现在初始层(输入层)和最终层。
HRM 引入了两项关键创新:
- 近似梯度: 循环模型通常依赖 BPTT 计算梯度。然而,BPTT 需要存储前向传播过程中的所有隐藏状态,并在反向传播时将其与梯度结合,这导致内存消耗与时间步长 T 呈线性关系(O (T))。HRM 设计了一种一步梯度近似法,核心思想是:使用每个模块最后状态的梯度,并将其他状态视为常数。这个方法内存开销仅为 O (1),不需要随时间展开,并且可以使用 PyTorch 等自动求导框架轻松实现(如图 4 所示)。

- 深度监督: 本文将深度监督机制融入 HRM。给定一个数据样本 (x, y),对 HRM 模型进行多次前向传递,每次传递称为一个段。令 M 表示终止前执行的段总数。对于每个段 m ∈ {1, …, M},令
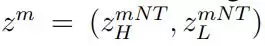
表示段 m 结束时的隐藏状态,包含高级状态分量和低级状态分量。图 4 展示了深度监督训练的伪代码。
- 自适应计算时间(ACT): 大脑在自动化思维(System 1)与审慎推理(System 2)之间动态切换。受此启发,本文将自适应停止策略融入 HRM,实现“快思考、慢思考”。图 5 展示了两种 HRM 变体的性能比较。结果表明,ACT 能够根据任务复杂性有效调整计算资源,显著节省计算开销,同时将性能损失降到最低。
- 推理时间扩展: 一个有效的神经模型理应能够在推理阶段动态利用额外计算资源来提升性能。如图 5-(c) 所示,HRM 模型只需要增加计算限制参数 Mmax,就能无缝实现推理计算的扩展,而无需重新训练或调整架构。
实验及结果
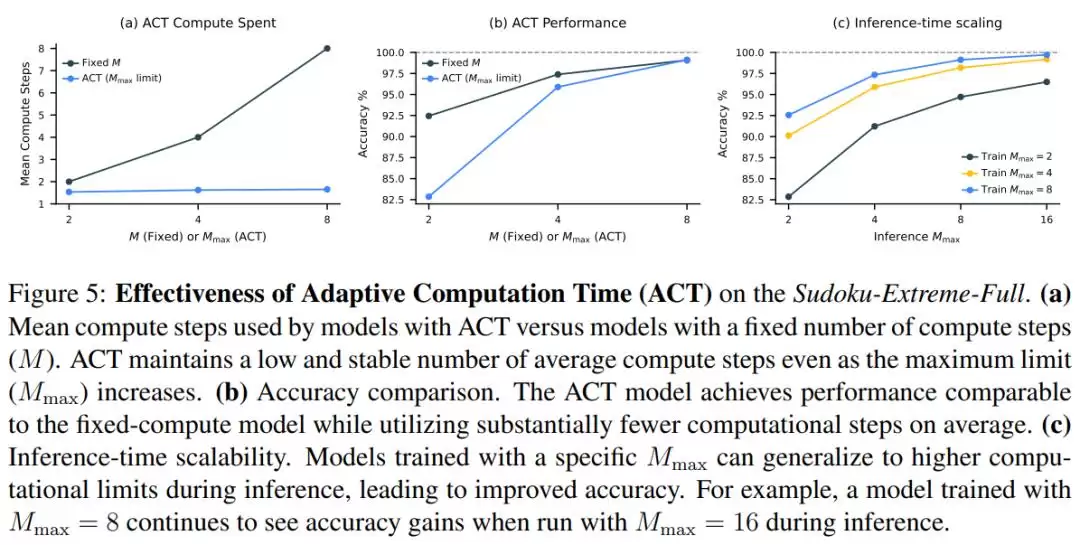
在该研究中,作者在 ARC-AGI、数独和迷宫基准测试上进行了测试,结果如图 1 所示:
HRM 在复杂推理任务上的表现令人印象深刻,但它引出了一个更耐人寻味的问题:HRM 的神经网络究竟实现了哪些底层推理算法?回答这个问题,对于增强模型的可解释性、加深对 HRM 解决方案空间的理解至关重要。
作者尝试对 HRM 的推理过程进行了可视化。在迷宫任务中,HRM 似乎会先同时探索多条潜在路径,随后排除那些阻塞或低效的路径,构建出一个初步的解决方案大纲,再进行多次优化迭代。在数独任务中,它采取的是一种类似深度优先搜索的方法:探索潜在解决方案,并在遇到死胡同时回溯。而在 ARC 任务上,HRM 采用了不同的策略,会对棋盘进行渐进式调整,并不断迭代改进,直至找到解决方案。与需要频繁回溯的数独不同,ARC 的解题路径更像是一种爬山优化,遵循一种更一致的渐进过程。
更重要的是,这个模型可以适应不同的推理方法,并可能为每个特定任务选择有效的策略。当然,作者也提到,还需要进一步的研究来更全面地了解这些解题策略。
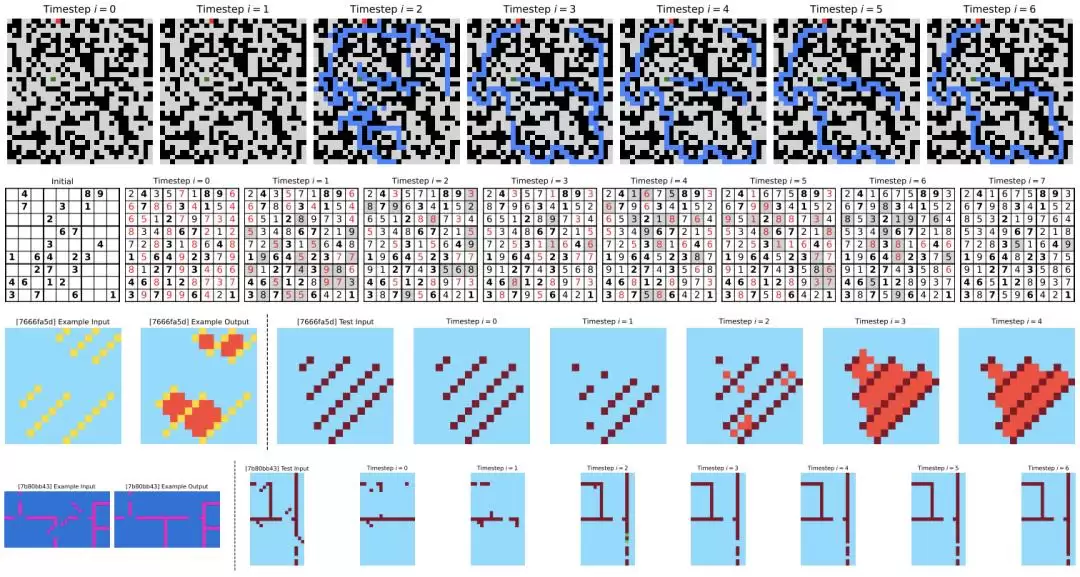
HRM 在基准任务中对中间预测结果的可视化。上图(MazeHard):蓝色单元格表示预测路径。中图(Sudoku-Extreme):粗体单元格表示初始给定值;红色突出显示违反数独约束的单元格;灰色阴影表示与上一时间步的变化。下图(ARC-AGI-2 任务):左侧为提供的示例输入输出对;右侧为求解测试输入的中间步骤。
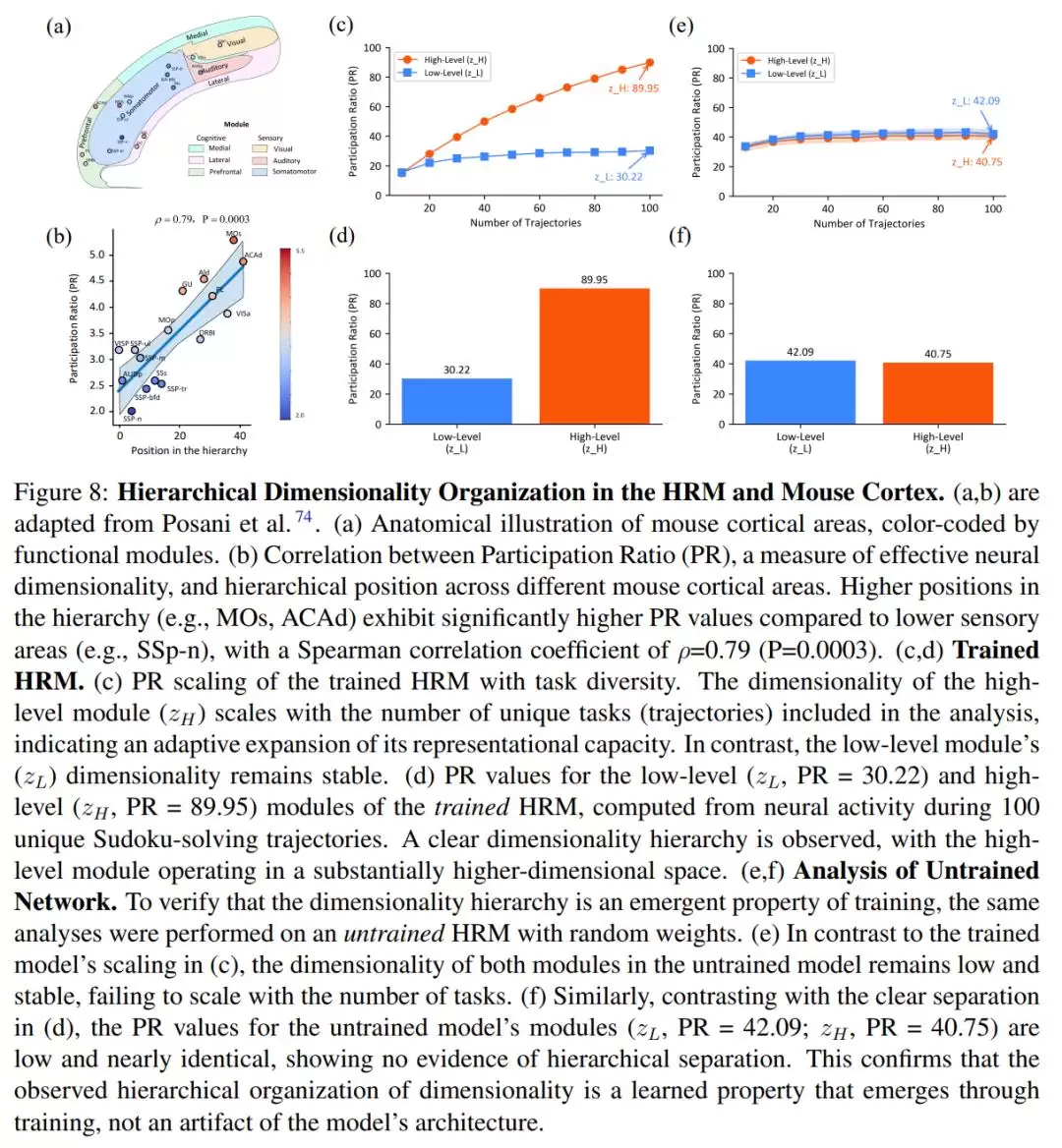
下图则将 HRM 模型与小鼠皮层的层级维度组织结构进行了对比。
例如,在小鼠皮层中可以观察到维度层次,其中群体活动的 PR(Participation Ratio)从低水平感觉区域到高水平关联区域单调增加,这表明了维度与功能复杂性之间的关联(图 8 a,b)。
图 8-(e,f) 的结果则呈现出鲜明对比:未经过训练的模型中,高层模块与低层模块没有表现出任何层级分化,它们的 PR 值都较低,且几乎没有差异。
这个对照实验有力地说明:维度层级结构是一种随着模型学习复杂推理任务而自然涌现的特性,它并非模型架构本身固有的属性。
在进一步的讨论里,作者指出,HRM 的图灵完备性与早期的神经推理算法(包括 Universal Transformer)类似。在给定足够的内存和时间约束的情况下,HRM 具有计算通用性。
换句话说,它克服了标准 Transformer 的计算限制,属于可以模拟任何图灵机的模型类别。再加上自适应计算能力,它可以在长推理过程中进行训练,解决需要密集深度优先搜索和回溯的复杂难题,从而更接近实用的图灵完备性。
除了 CoT 微调之外,强化学习(RL)是近期另一种被广泛采用的训练方法。但最近的证据表明,RL 更多是用来解锁现有的类似 CoT 的能力,而非探索全新的推理机制。而且,用 RL 进行 CoT 训练以其不稳定性和数据效率低而闻名,通常需要大量的探索和精心的奖励设计。相比之下,HRM 从基于梯度的密集监督中获取反馈,而非依赖稀疏的奖励信号。此外,HRM 在连续空间中自然运行,这在生物学上更合理,也避免了为每个 token 分配相同计算资源所导致的低效。




