AI答非所问的根源:它根本不了解你的业务
时间:2026-06-23 15:37
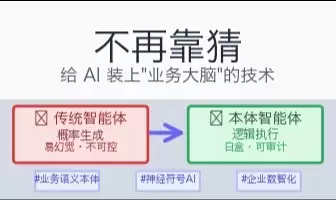
传统智能体在企业管理中因缺乏业务知识常答非所问,本体智能体通过构建包含实体、属性、关系、逻辑与行动的结构化业务语义本体,使AI从通用对话升级为专业业务执行者,实现语义统一、白盒推演及规则与执行解耦,满足精细化管理对精准、可审计和快速适配的需求。
在企业管理中引入大模型,效率提升有目共睹,但“踩坑”的声音也日益显现:用它做人才盘点,它套用通用理论,完全忽略企业个性;用它跑数据,结论看似头头是道,复核才发现依据不足。传统智能体的“表面智能”,已无法满足企业精细化管理的真实需求。**本体智能体(Ontology-Driven Agent)**,正是针对这一痛点而生。
一、为什么“会聊天”的AI,做不好企业的事?
举一个真实的场景。
HR问智能体:“华东区要不要新增门店编制?”
一个传统智能体会怎么回答?大概率是检索到一堆文档片段和统计数据,然后生成一段看起来“很专业”的分析,最后给出一个模糊结论:“建议综合考虑营收和人力成本……”——听着像那么回事,但你没法直接拿去做决策。为什么?
- 它**不知道**“门店编制”在你公司的精确定义,也不清楚编制和营收、人效、薪酬预算之间到底是什么关系;
- 它的结论是**概率生成**的,说不出依据,无法审计;
- 业务规则一变(比如人效标准调整),它又开始胡说八道。
这个问题的根源在于:**大模型懂语言,但不懂你的业务。**
大模型的能力来自海量通用语料,它擅长“像人一样说话”,但对某个企业**特定的业务概念、规则、逻辑**一无所知。它的回答本质是“下一个词最可能是什么”的概率预测——这正是所谓“幻觉”的根源:它不是在执行逻辑,而是在生成一段看起来合理的文字。在闲聊、写文案这类场景中,概率生成够用了;但在企业管理这种**要求精确、可追溯、可审计**的场景,概率生成根本不可靠。
二、什么是本体智能体?
> 本体智能体的核心,是在**大模型**与**企业业务数据、规则**之间,搭建一套标准化的“**业务语义本体**”。这套本体不是简单的知识库,而是一个包含**实体、属性、关系、业务逻辑、行动**的结构化体系。
通俗地说,**本体就是智能体的“业务操作手册+决策指南”**。它的本质是让AI从「通用对话者」升级为「专业业务执行者」——传统智能体的核心是“执行指令”,本体智能体的核心是“**理解业务**”。
本体的五个要素(以HR为例)
用一张Excel表来类比最直观:
::: center
{ width=300px }
:::
|要素|是什么|Excel类比|HR例子|
|:-:|:-:|:-:|:-:|
|**实体**|业务中的核心对象|表头(列名)|岗位、候选人、员工、部门|
|**属性**|实体的具体信息|表格里的数值|员工的“工龄”“绩效分”“技能标签”|
|**关系**|实体之间的连接|表与表的关联|“岗位隶属于部门”“员工任职于岗位”|
|**业务逻辑**|判断标准与规则|公式/IF条件|“连续3年绩效A→具备晋升资格”|
|**行动**|触发的具体操作|按钮/动作|“进入面试池”“获得晋升推荐”|
有了这套本体,智能体处理业务时**无需人工编写复杂脚本、反复给提示词**,只要依托提前搭好的本体,就能精准理解需求、自主规划并推进行动。
三、本体智能体凭什么更强?三个本质差异

差异一:语义统一 —— 让所有系统“说同一种语言”
传统智能体靠**向量匹配+关键词检索**,常出现理解偏差——分不清“苹果”是手机还是水果。本体智能体通过统一的业务语义体系,给每个业务术语**下准定义**,让招聘、薪酬、绩效等系统用同一套“语言”沟通,彻底避免“各说各话”。这是消除“数据孤岛”和“逻辑割裂”的关键——同一个“人效”指标,在不同模块里不再有不同算法。
差异二:白盒推演 —— 每个结论都“有迹可循、可审计”
传统智能体的决策是“数据统计+泛化推测”,只能给“可能适配”的模糊建议。本体智能体依托预设的业务规则与因果关系,不仅能给出“优先安排面试”“开展专项培训”等**具体结论**,还能**说清决策逻辑**——这就是“白盒推演”。对企业管理而言,“可解释、可审计”不是锦上添花,而是合规和信任的底线。
差异三:规则与执行解耦 —— “业务变,模型不用变”
传统智能体的规则与脚本深度绑定,业务规则一变(比如年假标准、招聘维度调整),就得让技术人员重写脚本、重训模型,适配速度跟不上。本体智能体把**规则与执行解耦**:业务人员只需在本体里**直接更新规则**,智能体就能快速适配。这完美匹配了企业政策频繁调整的现实——改的是“手册”,不是“大脑”。
四、技术架构:本体作为“语义中间层”
本体智能体的架构,本质是把“**懂语言的大模型**”和“**懂业务的本体**”结合起来,业界称之为**神经符号AI**——连接主义(神经网络)+符号主义(逻辑规则)的融合。
::: center
{ width=350px }
:::
- **大模型层**:负责自然语言理解与交互——听懂人话、生成回复;
- **本体语义层(核心)**:存放结构化的业务知识——实体、属性、关系、规则、行动。它是大模型和数据之间的“翻译官+裁判员”;
- **业务数据层**:打通分散的异构系统(招聘、薪酬、绩效、ERP……),统一数据治理。
大模型不再“凭感觉”回答,而是**在本体的约束和指引下**完成理解、推理、决策、执行。
工程视角:完整的技术组件栈
如果把上面的“三层”再往下拆到工程实现,本体智能体的技术栈大致是这样五层。其中**本体引擎层**是真正的核心,它由本体建模器、规则引擎、推理引擎、任务规划器四个组件构成:

- **交互层**:意图理解(NLU)+回复生成(NLG),负责听懂人话、把结果讲清楚;
- **大模型层**:基座大模型提供通用语言能力,通过Function Call发起工具调用;
- **本体引擎层(核心)**:
- 本体建模器 —— 定义实体/属性/关系,把业务知识结构化;
- 规则引擎 —— 承载业务逻辑、约束和触发条件;
- 推理引擎 —— 做多跳推理,且全程白盒可解释;
- 任务规划器 —— 编排行动路径;
- **知识与存储层**:知识图谱(Schema+实例)、向量库(语义检索)、本体元数据(OWL/RDF等标准格式);
- **数据接入层**:异构连接器统一打通招聘、薪酬、绩效、ERP等系统并做数据治理。
关键数据流:大模型与本体引擎之间是**语义对齐+规则校验**(大模型负责“说”,本体负责“判对不对”);本体引擎与存储层之间**读写知识**;推理结果**回填**到回复生成,最终返回给用户。
五、本体智能体是怎么工作的?
一次完整的业务处理,大致是这样一条链路:

以“华东区要不要新增门店编制?”为例:
1. **理解需求**:大模型听懂问题,定位到“编制规划本体”;
2. **关联本体**:自主拉通华东区营收数据、现有门店人均效能、薪酬预算上限、行业人员密度标准等多维度信息;
3. **逻辑推演**:依据本体内置的因果规则做综合分析(白盒,每步可查);
4. **输出决策**:“建议新增3家门店,配置15名员工,其中含2名储备店长”,并同步给出招聘时间表和薪酬成本预估。
整个过程,智能体不再局限于人力模块的孤立数据,而是真正实现“**业人融合**”——把人力决策嵌入业务增长、区域扩张、成本管控的经营场景。
六、落地场景:以人力资源为例
人力资源的招聘、薪酬、绩效、人才发展等模块,存在大量分散数据和复杂规则,正是本体智能体的用武之地。

1. 招聘全流程:精准匹配+主动洞察
构建“招聘域本体”,整合岗位需求、简历、组织架构、业务规划。它不仅能匹配“Ja va开发”“3年经验”等显性条件,还能识别“电商经验”与“零售数字化转型项目”的**关联性**,挖掘潜在适配人才。更进阶的是**主动招聘**:结合门店营收、扩张计划提前预判人才需求,从内部人才库识别可转岗/晋升员工,实现“不招聘而得人”。
2. 人才发展:数据驱动的“精准滴灌”
构建“人效分析本体”,形成“人效影响因素图谱”。它不仅算出“某员工人效低于团队均值20%”,还能分析原因(技能短板?职责不合理?激励不足?),并自动推荐对应方案。员工完成培训通过考核后,本体**自动更新其能力属性**,触发下阶段发展建议。
3. 人力决策:从“模块孤岛”到“业人融合”
拉通异构系统,构建覆盖全人力领域的“本体语言”,让业务数据和人力数据在同一逻辑框架下对话——就是前面那个“门店编制”的例子。
4. 合规风控:隐形风险的智能预警
把分散在各文件里的合规规则结构化进“人力合规本体”。当出现“连续加班3天未调休”“合同到期前30天未续签”等情况时**自动预警**;面对复杂考勤规则(不同工龄的年假天数、审批节点),也能准确判断请假是否合规。
七、关键认知:本体智能体不是“装个软件”
最后,有一个认知必须点明:
> **本体智能体的价值,终究取决于它承载的业务知识深度。**
它更像一个“**乐高平台**”——企业可以自主搭建和使用,但搭得好不好,取决于你往里面放了多少真正的业务智慧。这意味着,落地本体智能体**不是简单的技术部署**,而是需要**业务专家与技术人员共同梳理业务规则、构建合理的本体结构**:
- 从定义“什么是优秀员工”的逻辑,
- 到明确“人效影响因素的关联关系”,
- 每一步都需要业务经验的沉淀。
一旦构建完成,它就会成为企业的“**业务智能大脑**”,让管理从繁琐的事务性工作中解放出来,聚焦于战略与发展的核心价值。