最近,出行行业掀起了一股新潮流——越来越多企业开始将自动驾驶领域积累的AI数据能力,跨界应用于快速崛起的具身智能赛道。6月22日,如祺出行旗下数据业务板块正式发布了面向具身智能的专业数据平台。简单来说,就是将自身在AI数据服务方面的深厚积累,延伸至高速增长的具身智能数据处理场景中。
今年以来,全国多地密集出台政策,明确支持具身智能加速发展。6月9日,工信部和国资委联合启动了“2026年度人形机器人与具身智能实景实训专项行动”,计划到年底推动人形机器人等重点产品在代表性场景中真正“上岗工作”,目标是形成“万台级规模落地能力”。市场普遍预期,在政策持续推动下,具身智能将很快进入大规模预训练阶段。而数据——这个当前制约具身智能发展的核心瓶颈——相关的服务需求也将迎来爆发式增长。
眼下,具身智能的竞争焦点已从本体硬件转移到可供训练的高质量物理数据上。一组公开数据足以说明问题:全球高质量真实物理交互数据总量大约只有50万小时,而训练一个具身智能通用模型,起步就需要千万小时级别的数据量。国泰海通证券在最新研报中指出,“数据饥荒”已成为突破具身智能泛化能力的主要瓶颈。
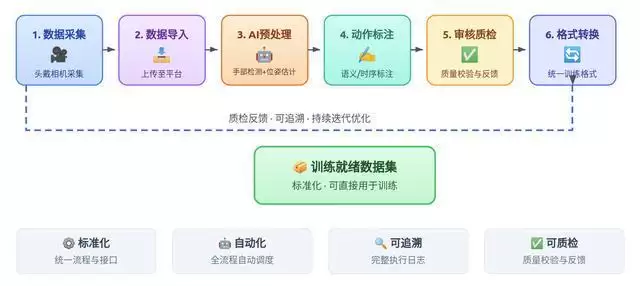
具身智能训练所需的多模态数据覆盖视觉、力觉、关节轨迹、语言指令等多个维度,对时空对齐和因果对齐的精度要求极高。然而,传统数据服务商提供的数据工具链往往功能分散,采集、标注、质检、格式转换、训练对接等环节常常散落在不同的工具与流程中。如祺数据此次发布的具身智能数据平台,搭建了一套面向Ego-centric数据的自动化处理流水线,覆盖数据导入、AI预处理、动作标注、多级质检到标准化格式导出的全流程。核心目标只有一个:降低Ego-centric数据从采集到训练的边际成本,真正突破“最后一公里”的困境。
这一做法打破了传统“数据工具链零散、标准不一”的局面,使数据处理流程更加标准化、自动化和可追溯。从原始视频到训练就绪数据之间的工程门槛被大幅降低,高质量数据可以开箱即用,模型训练团队的数据利用效率也得到显著优化。
“具身智能与自动驾驶本质上都是物理AI,两个领域的数据服务能力在底层逻辑上相通,存在可迁移的经验。”一位业内人士分析说。出行平台的全链路AI数据能力已在自动驾驶领域得到充分验证,这正是其向具身智能扩展的底气所在。




