一行代码,让你的SFT模型泛化能力飙升,效果直逼PPO
最近,在使用 llama-factory 进行模型微调时,除了常规的监督微调(SFT),许多同行也投入了大量时间尝试DPO、PPO等强化学习算法。
大家普遍的感受是:RLHF(尤其是PPO)调优后的模型,在指令遵循能力和泛化性能上,确实比单纯的SFT高出不少。但它的训练成本和不稳定性也出了名的“劝退”——每次看着那波动的奖励曲线和漫长的训练周期,一个自然的问题就浮现出来:难道就没有一种方法,能让我们用SFT的成本,达到接近强化学习的泛化效果吗?
直到一篇来自东南大学、UCLA、伯克利等机构的最新研究给出了答案——《ON THE GENERALIZATION OF SFT: A REINFORCEMENT LEARNING PERSPECTIVE WITH REWARD RECTIFICATION》。他们提出了一种名为动态微调(Dynamic Fine-Tuning, DFT)的方法,声称仅需一行代码的改动,就能显著提升SFT的泛化能力。

SFT的“病根”:一个隐藏在梯度中的“魔鬼”
要理解DFT为何如此有效,得先换个视角——用强化学习(RL)的“X光”去透视SFT,看看它的本质到底是什么。
我们都知道SFT的目标是让模型模仿专家数据,最小化交叉熵损失。它的梯度更新公式看起来平淡无奇:
∇L_SFT(θ) = E(x,y*)~D [ -∇log π_θ(y*"x) ]
但论文作者做了一个非常精妙的数学推导,通过重要性采样,把这个公式“翻译”成了RL策略梯度的语言:
∇L_SFT(θ) = -E(x,y*)~D [ (1/π_θ(y|x)) * ∇log π_θ(y|x) * r(x,y) ]
这个“翻译”后的版本信息量巨大:
- SFT可以看作一种RL,它的奖励
r(x,y)极其苛刻:只有当模型输出与专家答案完全一致时,奖励为1,否则为0。 - 梯度中隐藏了一个“魔鬼细节”:权重项
1/π_θ(y|x)。该权重与模型对专家行为的预测概率π_θ成反比。
这意味着什么?当模型遇到一个它认为“可能性很低”(low probability)的专家样本时,1/π_θ 会变成一个巨大的数值,导致梯度瞬间爆炸。
这好比一个学生在做题,SFT这个“老师”会不成比例地、极其严厉地惩罚那些学生认为最难、最不可能做对的题目。这种“高压政策”使得模型在优化时剧烈震荡,被迫去过度拟合那些罕见的、甚至可能是噪声的样本,而忽略了学习普遍规律。
这就是SFT泛化能力受限的“病根”:其梯度中隐藏了一个与模型置信度成反比的、病态的奖励结构。
DFT的“解药”:以子之矛,攻子之盾
找到了病根,开药方就简单了。既然问题出在那个捣乱的 1/π_θ 权重上,那直接把它去掉不就行了?
DFT的核心思想就是这么直接。它在计算SFT损失时,动态地给每个样本的损失 log π_θ 前面,乘上一个“矫正因子” π_θ(技术上通过 stop_gradient 来阻止对这个因子求导)。
最终,DFT的损失函数变成了这样:
L_DFT(θ) = E(x,y*)~D [ -Σ sg(π_θ(y_t|...)) * log π_θ(y_t|...) ]
这个改动堪称神来之笔,起到了“以子之矛,攻子之盾”的效果:
π_θ完美抵消了梯度中那个病态的1/π_θ权重。- 修正后的隐式奖励,在所有专家数据上都变成了稳定且均匀的1。
- 优化过程变得极其稳定,模型不再“偏科”,而是平等地从所有专家知识中学习。
这使得模型能够摆脱对罕见样本的过度拟合,转而学习更具鲁棒性和泛化能力的通用策略。而实现这一切,真的只需要一行代码的修改。
效果有多炸裂?直接看数据
理论说得再好,不如实验数据来得有力。论文在一系列高难度的数学推理任务上,把DFT和各种方法进行了全面对比。
1. SFT被“吊打”
从表1可以清楚看到,在Qwen、LLaMA等多个模型上,DFT带来的性能提升是标准SFT的好几倍。例如在Qwen2.5-Math-1.5B上,DFT的平均分提升是SFT的5.9倍。更关键的是,在Olympiad Bench这类奥数级难题上,标准SFT因过拟合甚至出现了性能倒退,而DFT依然能稳定地大幅提升模型表现。

表1:在五个数学基准上,DFT(加粗行)相比标准SFT和基础模型,在所有模型上都取得了显著的平均性能提升。
2. 收敛又快又好
从图1的学习曲线来看,DFT(蓝线)不仅最终性能天花板更高,而且起步就领先。往往在训练刚开始的几十步内,它的性能就已经超过了SFT跑完整个训练周期的最终结果。这说明DFT的梯度更新效率极高,每一步都学在了“刀刃上”。
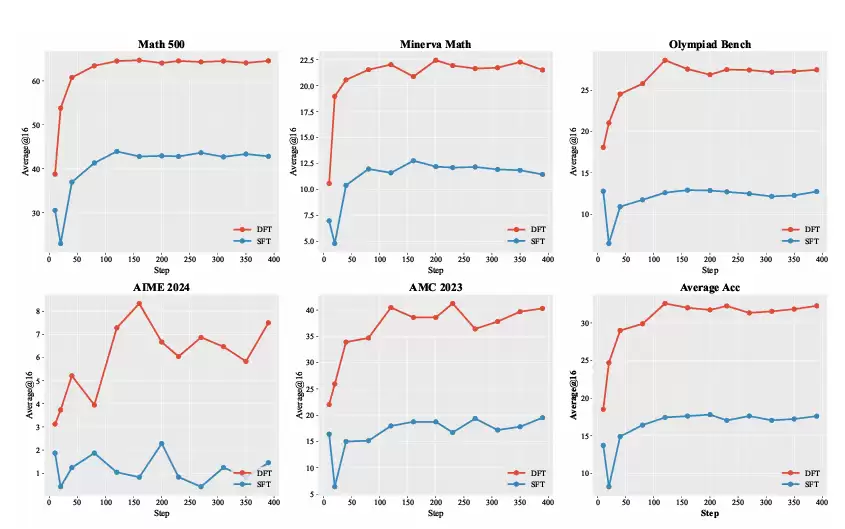
图1:在Qwen2.5-MATH-1.5B模型上,DFT(蓝色曲线)在所有基准测试中都比SFT(橙色曲线)表现出更快的收敛速度和更优的性能。
3. 硬刚RL算法也不虚
最令人惊喜的是,当把DFT应用于有奖励信号的离线RL场景时,它的表现甚至超越了DPO、PPO这些复杂的RL算法。
如表3所示,DFT的平均分(35.43)不仅远超DPO(23.20),甚至比强大的在线RL算法GRPO(32.00)还要高。这简直是在说,一个“魔改”后的SFT,在某些场景下比正经的RL还好用。
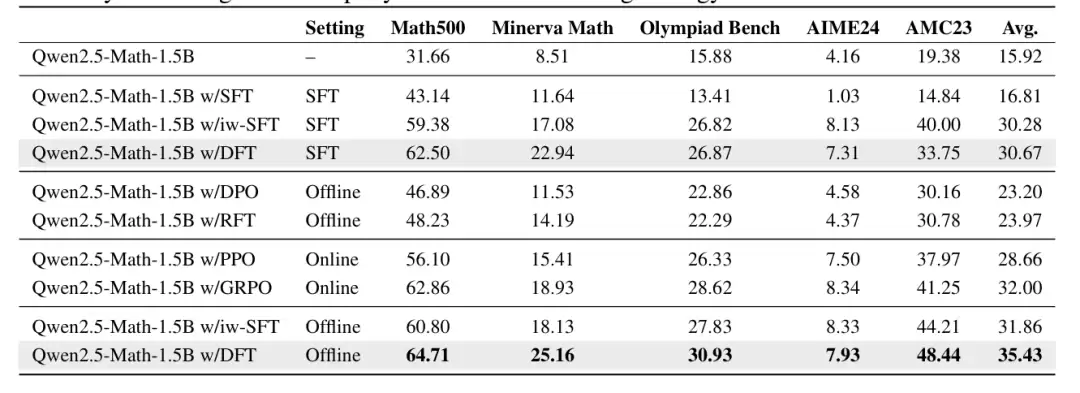
在离线RL设定下,DFT的表现超越了包括DPO、RFT在内的离线方法,甚至优于PPO、GRPO等在线RL方法。
为什么DFT能让模型更“聪明”?
DFT到底对模型做了什么,让它变得如此“通人性”?作者通过分析训练后模型的Token概率分布,给出了一个直观的解释。
图2:不同方法训练后,模型在训练集上的Token预测概率分布。
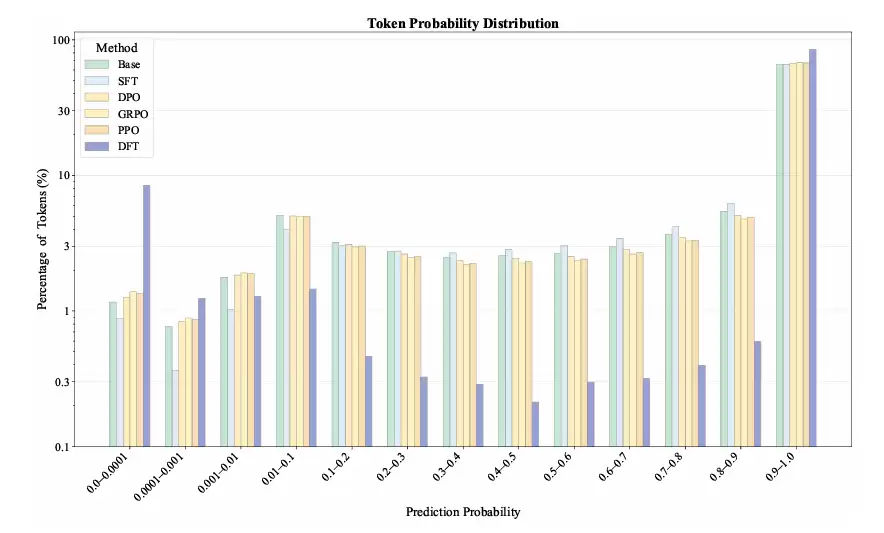
如图2所示,SFT(橙色)试图把所有词的概率都往右边(高概率区)推,试图做到“雨露均沾”。而DFT(深蓝色)和其他RL方法则表现出一种“抓大放小”的智慧:它们会把模型的信心集中在少数关键Token上(概率推向1.0),同时主动放弃对另一些Token的拟合(概率压向0)。
被放弃的是哪些词呢?作者发现,主要是"the', 'let', ',', '.'这类语法功能词或标点。
这背后是一个非常深刻的道理:一个真正聪明的模型,不应该试图完美记住每一个字,而应该学会区分“核心语义”和“语法结构”。
DFT正是通过其独特的重加权机制,教会了模型如何将宝贵的注意力资源聚焦在那些真正重要的内容上,这和我们人类学习时抓重点、忽略次要信息的思维模式高度一致。
这篇论文的工作,对于奋战在微调一线的人来说,价值巨大。它不仅提供了一个即插即用、效果拔群的工具,更重要的是,提供了一种全新的视角来理解SFT和RL的关系,让我们在“炼丹”的道路上,多了一份理论的支撑和优雅的选择。下次再有人抱怨SFT泛化不行时,可以把DFT甩给他试试。




