Kimi K2 技术报告解读:Agentic AI 时代的万亿参数开源模型,究竟强在何处?
在当前大模型技术日新月异的浪潮中,仅仅依靠参数规模的膨胀或在各类基准测试中拔得头筹,已不足以定义一个模型的真正价值。业界同仁的目光,正从被动的“能力”展示,转向更为主动、更具生命力的“智能”探索——我们称之为“智能体智能”(Agentic Intelligence)。
这意味着模型不再是简单的文本生成器,而是能够自主感知环境、精妙规划、深度推理,并与复杂动态世界进行交互以完成任务的“活”智能体。
正是在这样的背景下,月之暗面(Moonshot AI)团队携其最新力作——万亿参数开源模型 Kimi K2 震撼登场。
这份技术报告不仅以一系列令人瞩目的基准测试数据证明了其卓越性能,更重要的是,它系统而深入地揭示了团队在模型预训练、后训练以及 Agentic AI 实现路径上的一系列独到见解与创新实践。

核心突破:稳定高效的万亿 MoE 模型训练
任何致力于训练万亿级模型的团队,首先要面对的便是训练的稳定性和效率这座大山。当模型规模跃升至万亿参数的混合专家(MoE)架构时,训练过程中的不稳定性,尤其是注意力 logits 的爆炸问题,会变得异常棘手,如同在钢丝上跳舞。
传统的 AdamW 优化器虽然稳健可靠,但在 token 效率上略显不足;而像 Muon 这样以提升 token 效率为目标的优化器,在模型规模急剧扩大后,又极易出现训练崩溃的“滑铁卢”。Kimi K2 团队在此展现了其深厚的工程积淀与算法洞察力,独辟蹊径地提出了一种名为 MuonClip 的新型优化器。
MuonClip 的核心思想精妙绝伦,它并非简单粗暴地在注意力 logits 计算后进行硬性裁剪(logit soft-cap),因为这种治标不治本的方式,无法从根本上解决 Query 和 Key 点积结果可能已然庞大无比的问题。
Kimi K2 团队提出的 QK-Clip 技术,直接将“手术刀”伸向了注意力机制的权重矩阵(Query 和 Key 的投影矩阵 Wq, Wk)。它通过在每次更新后对这些权重进行巧妙的重新缩放,从源头上遏制了注意力 logits 的无序增长。
更令人称道的是,这种缩放并非一刀切,而是有条件地、逐头(per-head)进行的——只有当某个注意力头的最大 logit(max logit)超越预设阈值 τ 时,才会触发对该头权重的缩放。这种“精准制导”式的干预,最大限度地降低了对模型正常训练动态的干扰,确保了训练的平稳进行。
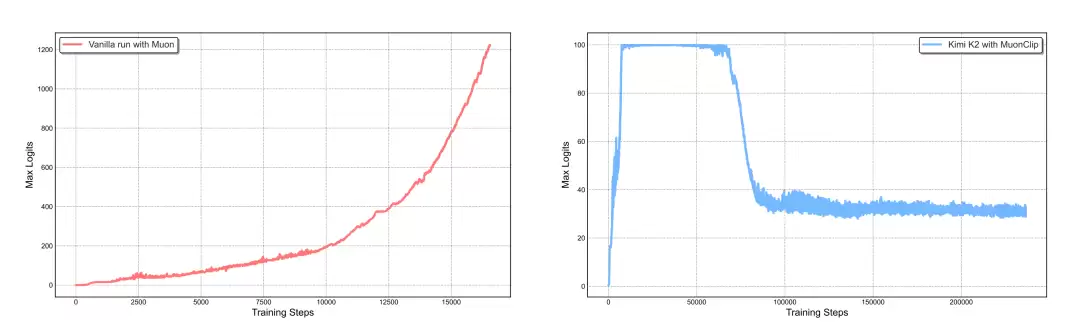
从论文的图2中,我们可以清晰地洞察 MuonClip 的非凡效果。左图描绘了使用原生 Muon 优化器训练时,最大注意力 logits 如何在短时间内飙升至1000以上,这无疑是数值不稳定和训练发散的“定时冲击波”。
而右图则生动地展示了,在 MuonClip 的保驾护航下,Kimi K2 训练过程中的最大 logits 被牢牢地控制在阈值100附近,并在训练进行约30%后,逐渐收敛到一个更低的区间,整个过程如行云流水般平滑,未曾出现任何损失尖峰(loss spike)。
这铁一般的事实充分证明了 MuonClip 在保障大规模 MoE 模型训练稳定性上的卓越成效。最终,Kimi K2 在高达15.5万亿 tokens 的海量数据上完成了预训练,并且全程无一次损失尖峰,这在万亿参数模型的训练史中,无疑是一项里程碑式的成就。
数据的深度挖掘:从“喂数据”到“造数据”
当高质量的人类语料日益成为稀缺资源时,如何从有限的数据中“压榨”出更多知识,从而显著提升模型的“学习效率”(即 token 效率),便成为了摆在所有研究者面前的核心难题。
Kimi K2 团队并未止步于传统的数据清洗和去重,而是匠心独运地引入了一套精心设计的合成数据生成策略。其目标是在不引入过拟合风险的前提下,有效扩充高质量的训练语料,为模型注入源源不断的“养分”。
他们提出了一种名为“知识数据重述”(Knowledge Data Rephrasing)的创新框架。其核心逻辑在于,对于一份蕴含丰富知识的文本(例如维基百科条目),仅仅进行单次训练(single epoch)不足以让模型完全消化吸收其全部知识;而如果简单地进行多轮重复训练(multi-epoch),则不仅会增加过拟合的风险,还会导致学习收益的递减。
为此,他们巧妙地利用一个强大的语言模型,通过多样化的提示(style- and perspective-diverse prompting),对原始文本进行多种风格和角度的忠实重写。
为了妥善处理长文本,他们还采用了分块自回归生成(Chunk-wise autoregressive generation)的策略,将长文智能地切片、逐片重写后再无缝拼接,从而确保了全局信息的一致性和连贯性。
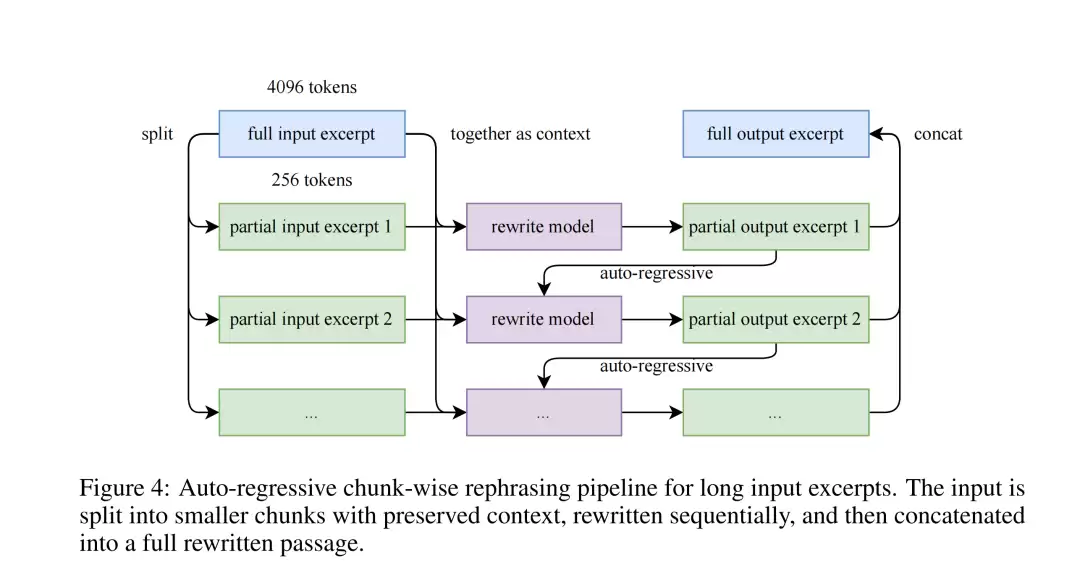
论文的图4直观地勾勒出这一流程的全貌。更值得强调的是,所有重写后的内容都必须经过严苛的忠实度验证(Fidelity verification),以确保其与原文在事实层面保持高度一致,杜绝任何“跑偏”的可能。
实验结果(论文表1)也无可辩驳地证明了这一方法的有效性:与将原始数据简单重复训练10次相比,将数据重述10次后再进行单次训练,模型在 SimpleQA 任务上的准确率反而更高。
这有力地说明,通过高质量的“换一种说法”,模型能够更深入、更泛化地学习知识,而非仅仅停留在表层记忆。
这种深刻的洞察同样被巧妙地应用于数学数据的处理上:他们将高质量的数学文档重写为更易于理解的“学习笔记”风格,并积极翻译其他语言的优质数学资料,从而极大地丰富了训练数据的多样性和深度,为模型构建了一个更为坚实的知识基础。
Agentic AI 的基石:规模化的工具使用数据合成与闭环强化学习
如果说稳定的训练和高效的数据利用构筑了 Kimi K2 坚实的“骨架”,那么其为实现 Agentic AI 所精心打造的一整套后训练流程,无疑是赋予其生命与智慧的“灵魂”所在。
这套流程由两大关键部分组成:大规模的工具使用数据合成(SFT阶段)和基于自评判的通用强化学习框架(RL阶段),二者相辅相成,共同推动模型向真正的智能体迈进。
在工具使用能力的培养上,团队敏锐地意识到真实世界的 API 调用数据难以大规模获取的困境。为此,他们独具匠心地构建了一个强大而高效的数据合成流水线。这个流水线如同一个精密的工厂,分为三个环环相扣的阶段:
工具库构建:他们巧妙地结合了从 GitHub 上精心抓取的3000多个真实世界工具(MCP tools),以及通过“领域演化”方法系统性生成的超过20000个合成工具。这种“真假结合”的策略,确保了工具库的全面性和多样性,为模型提供了广阔的“操作空间”。
智能体与任务生成:基于这个庞大而丰富的工具库,他们进一步生成了数千个拥有不同能力和行为模式的智能体,并为这些智能体量身定制了从简单到复杂的各类任务。这就像为学生设计了不同难度的课程和考试,以全面考察其能力。
轨迹生成与筛选:通过一个多智能体系统——其中包括模拟用户、负责调用工具的智能体,以及一个基于规则评估轨迹质量的裁判智能体——来生成海量的工具调用交互轨迹。这些交互在一个高度复杂的工具模拟器中执行,该模拟器能够逼真地模拟成功、失败以及各种边界情况,为模型提供了近乎真实的“实战演练”机会。
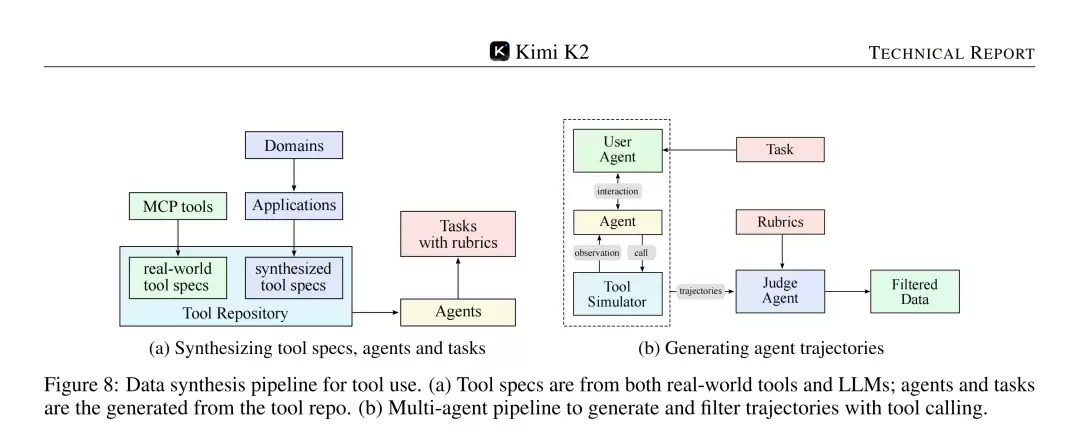
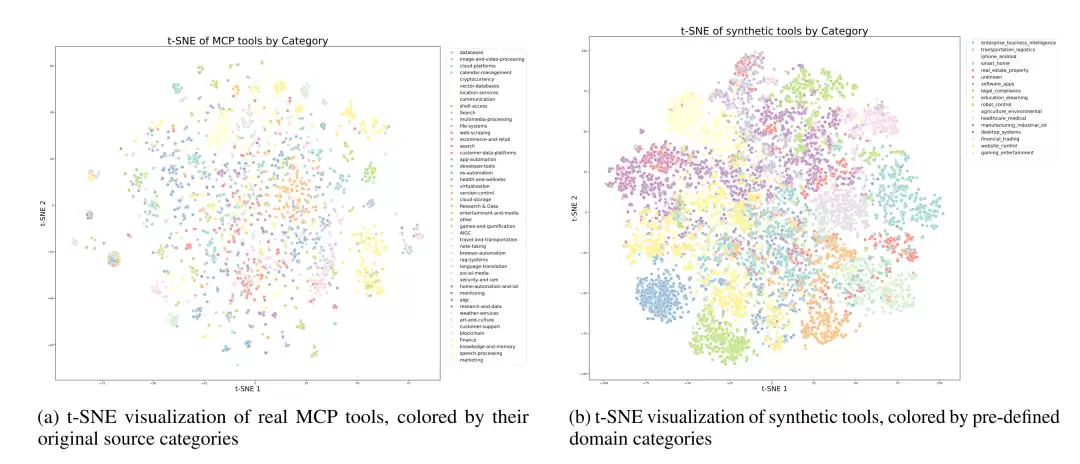
图8清晰地勾勒出整个数据合成的宏观流程,而图9则通过 t-SNE 可视化技术,直观地展现了真实工具和合成工具如何在功能空间中形成了完美的互补覆盖,共同构建了一个全面而多样的工具生态。
值得特别指出的是,他们还采用了混合方法,将这种可扩展的模拟环境与真实的沙箱执行环境(尤其是在编码和软件工程任务中)巧妙地结合起来。
这一策略确保了模型既能从模拟数据中学习到广泛的多样性,又能从真实环境中汲取到那些微妙而关键的实践经验,从而实现理论与实践的完美融合。
而在强化学习(RL)阶段,Kimi K2 的设计更是淋漓尽致地体现了对 Agentic AI 的深刻洞察。
他们并未将自己局限于那些拥有明确可验证奖励(verifiable rewards)的任务(如数学问题求解、代码通过单元测试),而是大胆引入了一个名为“自评判规则奖励”(Self-Critique Rubric Reward)的创新机制。
这一机制使得模型的能力得以泛化到更具主观性、更开放的领域,突破了传统强化学习的边界。这个框架的核心是一个闭环的、持续优化的系统,其运作模式如同一个不断自我完善的智能生命体:
策略优化:K2 的“演员”(actor)模型,如同一个初出茅庐的学徒,针对各种通用提示生成初步的回答。它尝试着给出自己的理解和解决方案。
自评判:紧接着,K2 的“评论家”(critic)模型便会登场。它如同一个经验丰富的导师,基于一套精心设计的核心价值观和任务指令(例如:回答的清晰度、相关性、对话的流畅度等),对“演员”的输出进行细致入微的成对比较和打分。这个“评论家”本身并非凭空而来,它在 SFT 阶段通过大量的偏好数据进行了初始化,使其具备了初步的“审美”和“判断力”。
评论家模型的持续对齐:这正是整个闭环中最精妙的一环。在 RL 训练过程中,那些来自可验证奖励任务(例如:代码成功通过了所有单元测试)的“客观”反馈信号,会被巧妙地用来持续更新和校准“评论家”模型。这相当于用“客观真理”去不断地校准和修正“主观判断”,从而确保“评论家”在评估开放式问题时,其判断标准能够与模型在解决客观问题时所展现出的实际能力保持高度一致,并随着模型的进步而不断演进。这是一种“以客观促主观,以主观反哺客观”的精妙平衡。
这个闭环设计,赋予了 K2 超越传统 RLHF 的能力。它不仅能从外部奖励中汲取经验,更能通过这种独特的“自我反思”机制,逐步对齐那些难以简单量化的人类偏好,例如创造力、有用性、深度等。这为模型在开放域中实现更高级别的对齐,开辟了一条充满潜力的可行路径。
创新与启示
细致研读 Kimi K2 的技术报告,我们能够清晰地看到一条从底层工程基石到顶层智能设计、逻辑严谨、环环相扣的技术演进路线。这份报告所呈现的,远不止是一个在各项榜单上表现优异的模型,更重要的是,它为整个业界提供了诸多弥足珍贵的启示:
基础模型研发是系统工程的巅峰之作:Kimi K2 的成功绝非单一算法的昙花一现,而是从优化器创新(MuonClip)、数据工程(Knowledge Data Rephrasing)、模型架构选择(更高稀疏度的 MoE),到后训练框架(大规模合成数据与闭环强化学习)等一系列环环相扣、协同并进的成果。这无疑在提醒我们,未来大模型的竞争,将是一场对全栈技术能力的综合性大考,任何短板都可能成为制约发展的瓶颈。
效率,才是核心竞争力之所在:无论是旨在大幅提升 token 效率的 MuonClip 优化器,还是为了从有限数据中“榨取”最大价值的知识数据重述策略,其背后都指向了一个颠扑不破的核心理念——在计算资源和数据资源日益成为瓶颈的现实世界中,如何将效率发挥到极致。
通往 Agentic AI 的康庄大道,在于高质量的交互数据与精妙的闭环对齐:Kimi K2 在后训练阶段倾注了巨大的精力,构建了数据合成与强化学习的闭环系统。这清晰地昭示我们,要让模型从一个仅仅“理解和生成语言”的工具,真正蜕变为一个能够自主行动的“智能体”,其关键在于让它在模拟和真实环境中进行海量的、带有明确反馈的交互式学习。其提出的“自评判规则奖励”和“闭环评论家对齐”机制,无疑为解决开放域中模型与人类偏好对齐的难题,提供了一个极具启发性和前瞻性的思路。
Kimi K2 不仅是一款性能卓越的开源模型,更是一份内容详实的技术蓝图。它向我们生动地展示了,在通往 Agentic Intelligence 的征途上,如何通过扎实的工程实践、富有创意的算法设计,以及对智能本质的深刻洞察,一步步将宏伟的理论构想变为触手可及的现实。
彩蛋: 值得一提的是,在这份技术报告的贡献部分(Appendix A Contributions),Kimi K2 团队在列出所有贡献者姓名之后,还特别列出了“Kimi K2”本身。
这无疑是 AI 领域一种独特的“自我致敬”,也从侧面展现了其在辅助科研工作中的强大能力和团队对自身技术的信心,暗示了模型在研发过程中可能也扮演了某种角色。





