我们先从每天都会遇到的一个场景说起。
无论是企业内部的Wiki,还是对外官网的帮助中心,亦或是云厂商的产品文档,用户寻找具体答案时,绝大多数情况下,面对的只是一个搜索框。

这个搜索框的本质其实是“找页面”,而非直接“给答案”。当你搜索“人脸识别计费方式”,它返回十几篇标题包含“人脸识别”和“计费”关键词的文档。至于哪一篇、哪一段才是你需要的,你得逐一点开阅读,再自行拼凑答案。它将“理解问题、定位答案、归纳表述”这三项最耗费精力的环节,全部交给了用户。
近两年,许多文档中心开始接入AI智能客服,方向是正确的。但在实际体验中,我反复遇到两个工程层面的硬伤:
最令人困扰的,一是响应速度慢。很多AI客服默认开启了“深度思考”模式,你提问后,它先是转圈,“正在为您解答,请稍等片刻……”,等待数秒甚至十几秒才输出第一段话。对于一个只想快速确认某个配置项的用户来说,这种等待足以劝退。
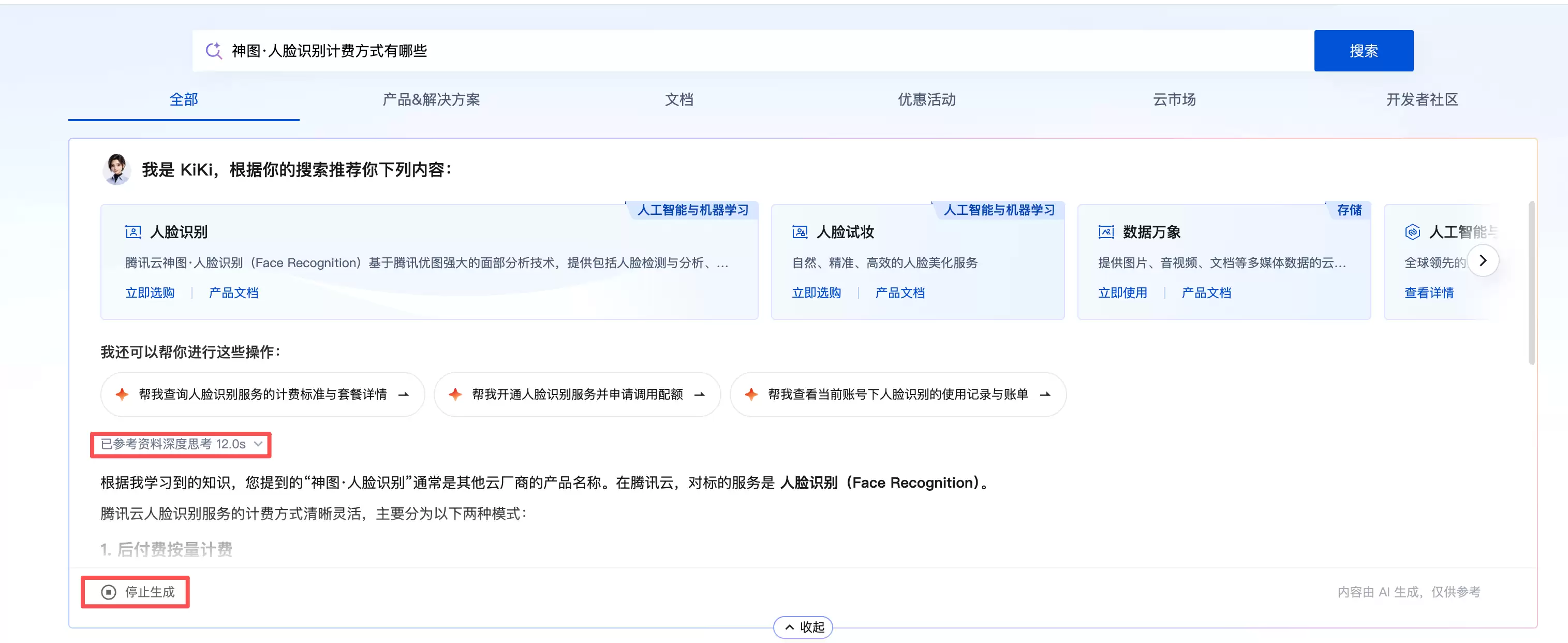
二是重复计算负担。同一个高频问题——例如“怎么计费”“有没有免费额度”——换一个用户提问,或者同一个人再次询问,系统每次都重新调用大模型,从头思考一遍。对用户而言是重复等待,对企业而言是重复消耗Token。文档问答的提问分布具有明显的长尾特征,头部高频问题占比很高,这部分本应“计算一次、复用多次”,却被白白浪费了。
之前我在公司内部开发过一版“官网文档中心智能问答助手”的技术架构,踩过检索质量、并发和成本控制上的不少坑。最近将那套思路从业务中剥离出来,并对技术架构做了精简,重写开源了一个轻量版本,命名为DocMind,供有同样需求的团队参考。本篇是系列开篇,我想把它的设计目标、整体架构以及几个关键的工程取舍讲清楚——重点不在于“它能跑”,而在于“为什么要这么设计”。
二、它是什么:一句话与三条设计原则
先给一句话定义:
在重写和开源之前,我确定了三条设计原则,后续所有的取舍都围绕它们展开:
轻量可落地:不引入Redis、MongoDB这类外部中间件,不强依赖Docker。一台普通机器、一条命令即可启动。中间件每多一个,部署门槛和运维负担就高出一截——对于“想快速验证”的团队非常不友好。
敢对外开放:它的定位是直接挂到公网的“轻量AI助手”,因此安全防控必须是第一公民,而非事后打补丁(这部分内容较多,单独放在系列第3篇)。
跨语言:知识库可以只有一份中文或英文文档,但要能服务全球多语种用户。这是我认为最有价值、也最容易被忽视的能力,也是我们公司之前官网全球化过程中最大的诉求。
它实际运行起来的样子(Demo使用一份公开产品文档作为知识源):
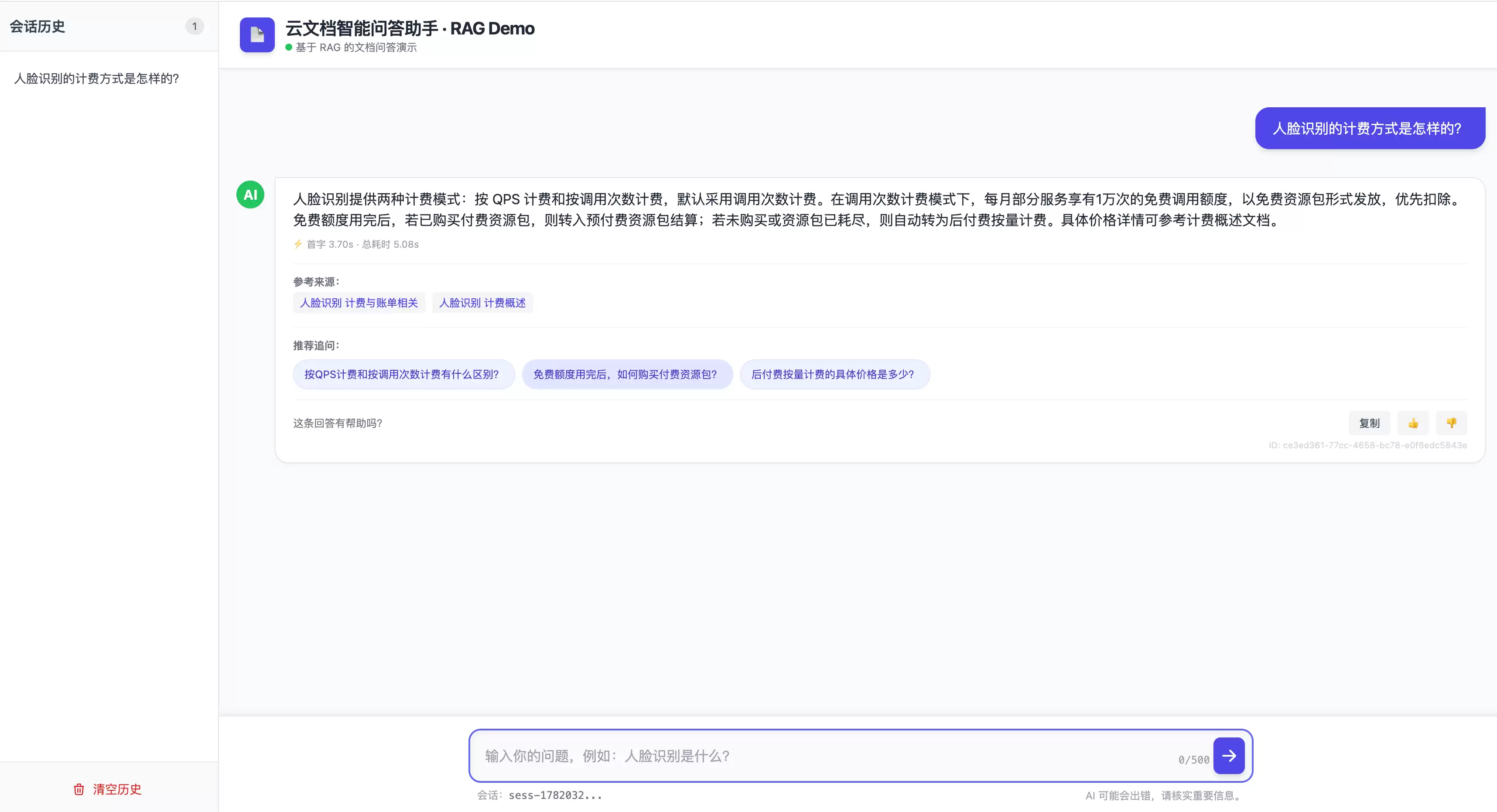
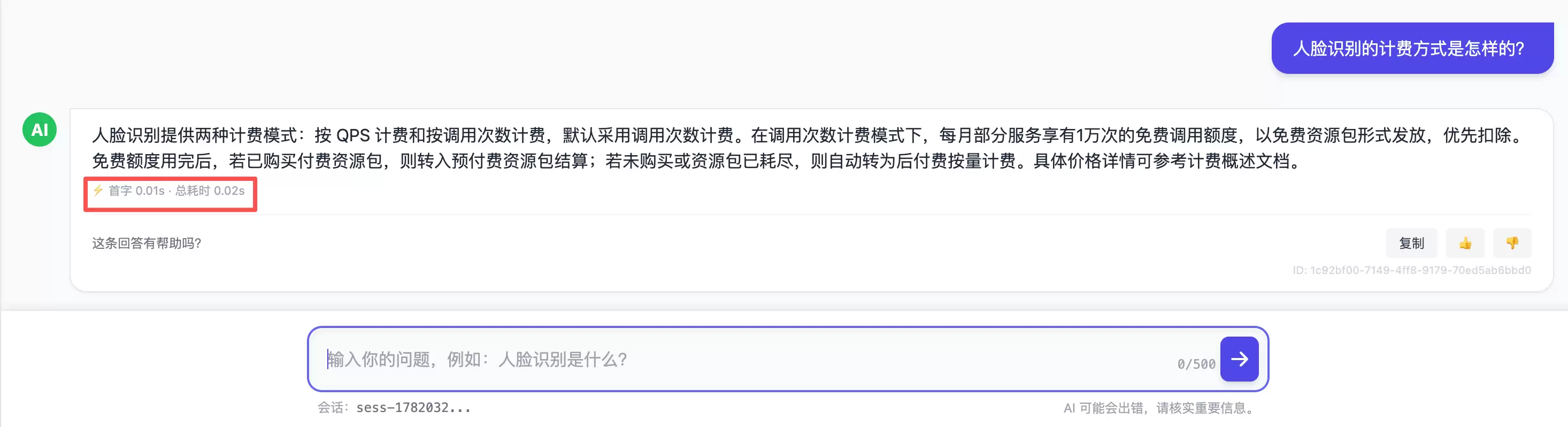
留意答案下方两个细节:响应耗时是明确标注出来的,参考来源点击即可跳转原文。这两个看似不起眼的设计,背后都有刻意的工程考量。
三、整体架构:离线建库 + 在线AI问答
抛开细节,DocMind本质上包含两条链路:离线建库和在线问答,简要说明如下:

3.1 离线建库:把文档站变成可检索的知识
① 抓取范围按路径前缀限定。爬虫以起始URL的path作为前缀,仅抓取该目录下的页面。例如直接提供整个文档中心的导航入口,爬虫脚本从根地址开始全量爬取,支持整个文档中心全部内容的AI智能问答。如果文档中心很大,你也可以有针对性地只选择某个产品或模块进行爬取,比如人脸识别产品入口是 .../document/product/867,系统就只爬取这一个产品的文档,不会顺着导航链接把整个站点都拖下来。这是一个非常实用的“圈地”机制——文档站内部互链极多,没有这个约束,爬虫会迅速失控。
② 正文容器自动识别。网页中的导航栏、侧边目录、页脚占用大量噪声,直接全文向量化会严重污染检索质量。我的做法是按优先级依次尝试一组正文容器选择器: → → (部分文档站的自定义正文容器) → .markdown-body(常见markdown主题),都命中不了才回退整个。识别到正文后做空白合并、噪声行清洗。换一个新文档站时,若它的正文结构特殊,只需在选择器列表里添加一条class即可,无需修改主流程。
③ 切片:诚实地说,目前是固定窗口。当前采用固定长度滑动窗口:每片约800字符,相邻片重叠100字符。重叠是为了避免将一个完整语义切断在两片边界,导致检索召回不到。我不打算把它包装成什么高级策略——它简单、可预测,对大多数文档足够使用。但我们也清楚它的局限:它不理解段落和语义边界。按语义/标题层级切片是后续优化的明确方向,将在第2篇里与检索质量一起讨论。
④⑤ 向量化与增量更新。切片经BGE-M3本地模型编码后写入ChromaDB,每条携带url / title / chunk_index元数据——title用于来源溯源的友好展示。重复ingest时,按页面内容哈希判断是否变化,未变则跳过,并清理掉已不存在的过期文档,实现增量而非每次全量重灌。
3.2 在线问答:从一句提问到一段带出处的回答
⑥ 语种识别。使用确定性规则判断提问语种(是否包含CJK字符),从而决定回答应使用的语言基调。这里我选择规则而非再次调用模型,是为了节省一次往返、降低一份延迟和成本——能用确定性逻辑解决的,不必动用大模型。

⑦ 向量检索Top-3。提问经同一个BGE-M3编码后,在ChromaDB里按向量距离取出最相近的3个切片。这里隐藏着本项目最关键的能力之一:因为BGE-M3是多语言模型,中文文档和外语问题被映射到同一个语义空间,所以“中文知识库 + 外语提问”才能对得上——这是第2篇的主题。
⑧ 相关度阈值闸门:查不到就老实说没有。这是我最想强调的一个设计。检索结果的最小距离一旦超过阈值(默认0.55),说明知识库里没有足够相关的内容,此时系统直接礼貌拒答,根本不调用大模型。
这个闸门同时解决三个问题:
- 防幻觉:没有上下文支撑时,宁可说“我这儿没有这个信息”,也不让模型硬编一个似是而非的答案。
- 省成本:无关提问被挡在LLM之前,不产生Token消耗。
- 划边界:让助手始终待在“文档知识范围内”,不被诱导去回答它不该回答的问题。
对于一个面向公众的问答系统,“敢于拒答”比“什么都敢答”要可靠得多。
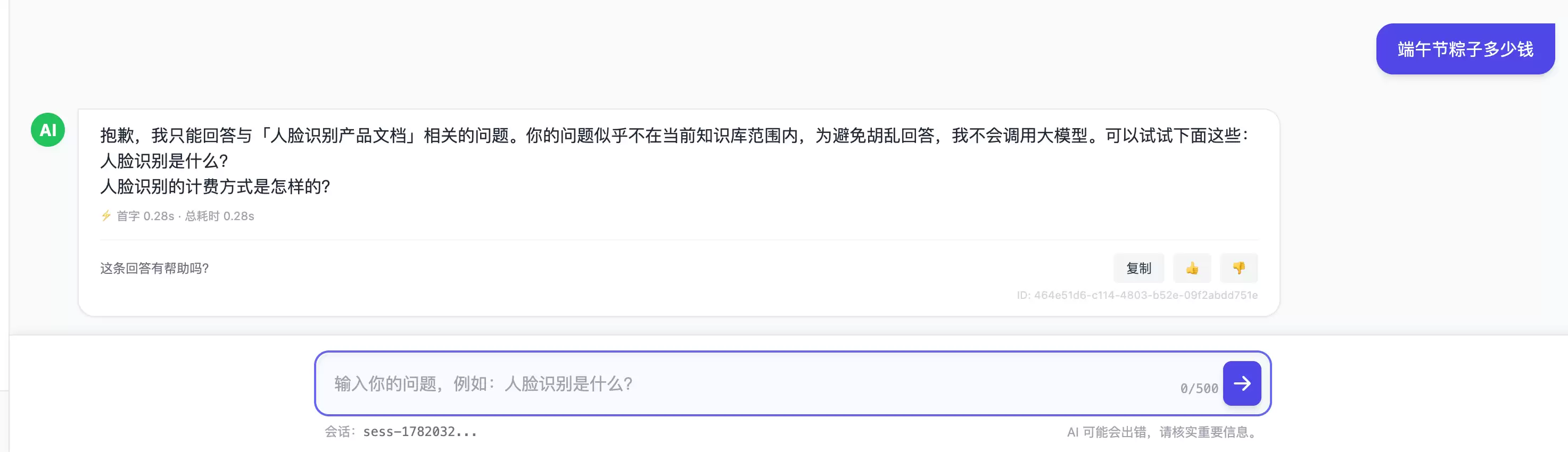
⑨ 缓存:相同问题,计算一次复用多次。回到开头提到的“重复问题重复算”痛点——这正是我重点解决的地方。系统对“完全相同的问题 + 相同对话上下文”做答案缓存:第一次正常生成,之后再问一模一样的问题,直接命中缓存返回,零Token消耗、瞬时响应。缓存键由问题与上下文哈希得到,并带有TTL与基于会话的失效联动(会话清空时一并清掉其缓存)。
需要把话说准:这是精确匹配缓存,而非语义缓存——“人脸识别是什么”和“什么是人脸识别”目前会被当作两个问题。将其升级为语义级缓存是一个有价值的方向,但也要权衡误命中的风险,这个取舍留待后续。
⑩ 上下文组装与截断。命中的切片拼成上下文喂给模型,超过长度上限时截断,避免将过长上下文砸给LLM,既浪费Token又稀释重点。
⑪ 后处理:把回答收拾干净。模型产出后做了两步纠偏:一是语言一致性——回答语种与提问语种不符时触发一次改写(中/英之间),避免“中文提问、英文作答”的尴尬;二是剥离开头废话——大模型很爱用“根据提供的上下文信息,……”“Based on the provided context, ……”开头,Prompt里要求过它别这么干,但模型并不可靠,所以在输出侧用规则确定性地把这类前缀剥离。能用Prompt降低概率,但用代码兜底保证,是我处理这类“模型不老实”问题的一贯做法。
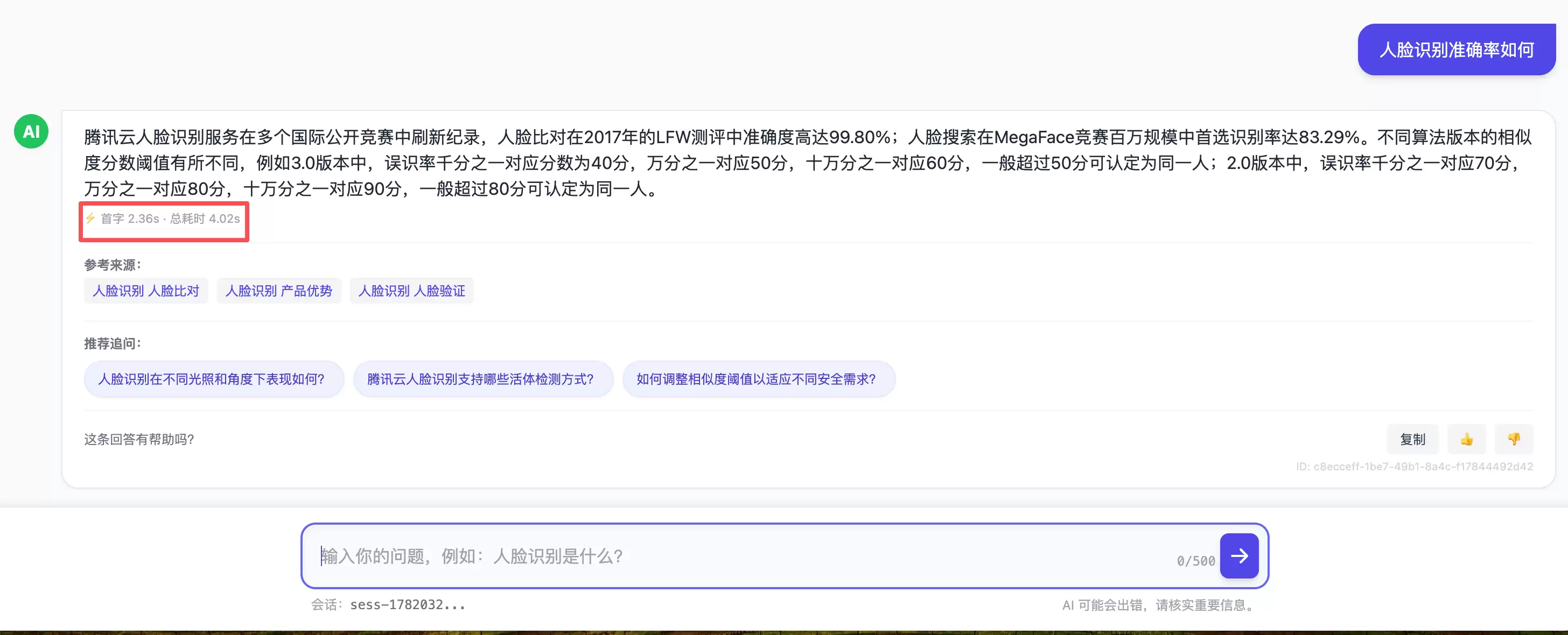
⑫ 输出、溯源与追问。最终通过SSE把回答推送到前端,同时附上参考来源(文档标题 + 链接)和几个推荐追问,并写入缓存。
四、几个值得说的工程取舍
4.1 “流式”其实是模拟的——一个有意识做出的取舍
界面上回答是逐字蹦出来的打字机效果,但我要诚实地讲清楚它的实现:上游LLM调用是非流式的——我先一次性拿到完整答案,再在本地将其切成小片,通过SSE逐片下发,模拟出流式效果。
为什么不直接用真流式?因为我在拿到完整答案后还要做两件需要全文才能做的事情:语言一致性纠偏、剥离开头废话;以及把完整答案写入缓存。真正的逐Token流式,会让这些“针对全文的后处理”变得复杂得多。
它的代价我也不回避:因为要等全文生成完才开始吐字,界面上的“首字耗时”实际上约等于整段生成时间(这也是为什么Demo里首字~3s、总耗时~4s两个数字很接近)。所以可以这样理解:demo项目真正的“快”,是缓存命中时的秒回,而不是首次生成的首字延迟——首次延迟取决于你所接的上游模型。
如果要兼得,正确方向是“真流式 + 增量后处理”(边收Token边做可增量的清洗),这是已列入计划的优化项。
4.2 把“耗时”显示做成一等公民
特意将每条回答的首字/总耗时直接显示在界面上。这不只是一个炫技的小徽章——它是一种对用户和对自己的诚实:用户能直观感知快慢,自己也能借助它快速评估“更换上游模型值不值”“缓存命中率高不高”。一个系统愿不愿意把自己的延迟摊在明面上,某种程度上反映了它对自身表现的底气。
4.3 来源溯源:让AI不是黑箱嘴替
每个回答都带回它所依据的文档标题和链接,用户一点就能跳到原文核对。对于文档问答这类“答案必须可信”的场景,可溯源不是加分项,而是底线——它把“AI说的”还原成“文档里写的,AI只是帮你找到并归纳”。
4.4 轻量的理由与代价
无Redis、无MongoDB——向量库使用嵌入式ChromaDB(一个本地目录),审计/反馈与爬虫元数据各用一个SQLite文件,限流、缓存、会话历史等运行时状态采用进程内的LRU + TTL容器承载。
好处是部署极简,从git clone到能跑只需几步。代价也很清楚:进程内状态意味着单实例——要做多副本水平扩展,这些内存态就需要外移到共享存储。这是一个明确的定位取舍:DocMind服务的是中小规模文档中心的“轻量落地”,并非为超大规模高可用集群而设计。
4.5 为什么没有直接套一个现成RAG框架
这个问题绕不开:LangChain、LlamaIndex、Dify这些成熟方案都在,为什么还要自己写一套?
我的判断是:针对这个具体场景,自己实现这条主干链路的边际成本,低于驾驭一个大框架的认知成本与约束成本。RAG的核心链路——爬取、切片、向量化、检索、阈值判断、组装、调用——本身并不复杂,代码量可控、每一步都看得见摸得着。而通用框架为了覆盖所有场景,引入了大量抽象层;一旦我需要做“阈值拒答”“输出侧剥废话”“精确匹配缓存”“面向公网的多维限流”这类贴近业务的定制,在框架的抽象里反而要绕路,甚至要和它的默认行为对抗。
这并不是说造轮子更高明——而是在“可控、可读、可改”与“开箱即用、但内部是黑箱”之间,为这个项目选择了前者。如果是一个需要快速对接几十种数据源、上百种工具的复杂Agent系统,我的选择会反过来。技术选型从来不是比谁更先进,而是看它是否匹配你当前要解决的问题的形状。
4.6 可观测与反馈闭环:上线只是开始
一个要对外服务的系统,光能跑还不够,必须“看得见、调得动”。这块做了两件事:
- 审计双写:每一次问答、每一条用户反馈,都同时写入结构化日志(stdout JSON,方便实时
grep+jq)和一个独立的SQLite表(支持分页、过滤、关键字检索)。每条记录带有request_id,可串联全链路追踪。需要强调的是:审计数据绝不进入向量库——避免有人通过提问反查到“别人问了什么”。 - 反馈闭环:每条回答下方有




