Anthropic 不久前发布了一篇关于智能体上下文工程的深度文章,读后收获很大。本文梳理其核心要点,算是一份学习笔记,帮助你快速理解什么是上下文工程,以及它为何对智能体如此重要。
01 — 提示词工程 vs 上下文工程
先厘清一个基础概念:上下文,指的是从大语言模型(LLM)采样时包含的所有 token 集合。
下面这张对比图清晰展示了提示词工程与上下文工程的差异。提示词工程的核心在于“引导”,即教会大模型如何思考,从而输出我们想要的结果。而上下文工程则更像一个后端管家,负责在智能体运行过程中,对大模型输出的信息进行整合、提炼,甚至实现持久化管理。两者并非非此即彼,而是相互配合、协同发力的关系。
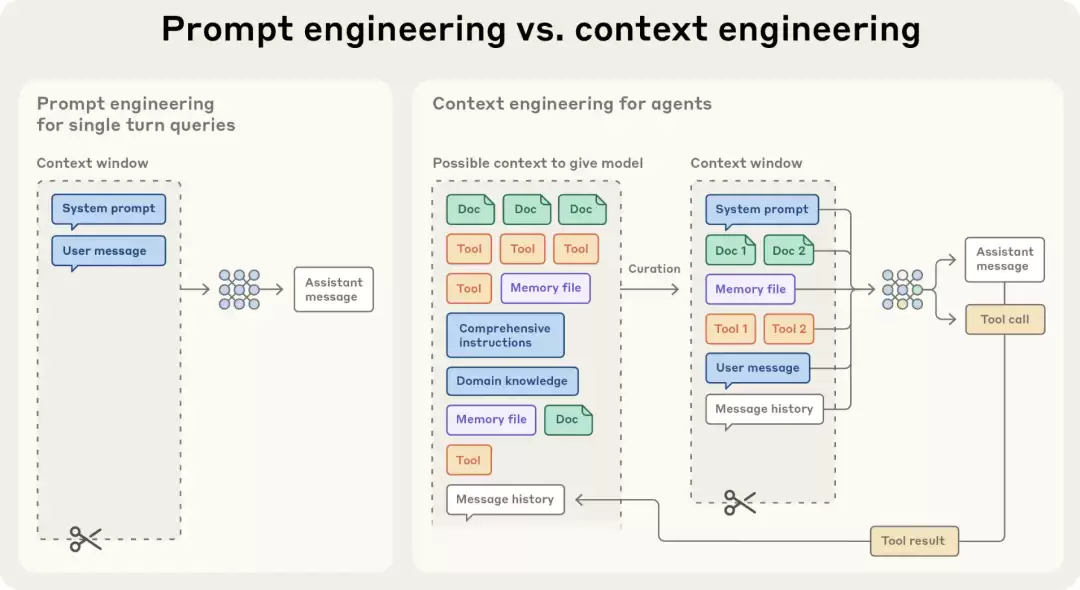
两者各有侧重:提示词工程致力于求解“单次问答”的最优方案,而上下文工程则专注于实现“多轮自主任务”的最佳效果。应用场景不同,侧重点自然不同。
02 — 上下文工程对智能体的关键意义
文章提出了一个有趣的观点:上下文是会“腐烂”的。
Anthropic 通过经典的“大海捞针”实验,给出了一组令人警醒的数据:当上下文长度低于 8k 时,模型召回率高达 95%;一旦扩展到 32k,召回率骤降至 78%;若拉到 100k,关键信息被模型“忽略”的概率直接飙升至 30%。
简言之,随着上下文窗口中 token 数量的膨胀,模型准确回忆信息的能力会直线下降。
这一问题的根源藏在 LLM 的架构基因中。Transformer 架构让每个 token 都能与整个上下文中的其他 token 建立关联,产生 n² 级别的成对关系。上下文过长时,模型精准捕捉这些关系变得越来越困难。这好比在上下文规模与模型注意力焦点之间,天然存在一股制衡力量。
数据胜于雄辩:要构建真正有能力的智能体,上下文工程必须认真对待。
03 — 优质上下文的四个配方
1、提示词:高信号、低噪音
不要在提示词中写入“if A 且 B 且 C 则执行 D”这类脆弱的逻辑,也别只说“请尽量做好”这种空话。正确做法是:清晰给出边界、目标和输出格式,让模型自行推理路径。建议将提示词拆分为不同部分,如 <背景信息>、<指令>、## 工具指导、## 输出描述 等,用 XML 标签或 Markdown 标题划分,一目了然。
2、智能体工具调用:高效 token 与高效行为
工具是智能体与环境交互的桥梁,并在运行时不断引入新上下文。但我们常见的一种失败模式是:工具集过于臃肿、功能过多,导致模型在选用工具时模棱两可。这里有一个朴素的道理:如果人类工程师自己都无法明确某个场景该用哪个工具,就别指望 AI 能做得更好。为智能体规划一个最小可行工具集,反而有利于在长时间交互中维护和精简上下文。通过工具返回 token 高效的信息,同时规范智能体的行为,这才是提升 token 效率的关键。
3、示例(few-shot):典型场景优于边缘情况
挑选 3 个能覆盖 80% 主流场景的典型示例,远比堆砌 20 条“罕见 corner case”更有效。前者能让模型举一反三,后者只会让它迷失在细枝末节中。
4、动态检索
Anthropic 在另一篇文章中重新定义了智能体:LLM 在循环中自主使用工具。这一理念也带来了上下文字段设计思路的转变。如今,许多 AI 原生应用开始采用基于嵌入的“推理前检索”模式——先检索出重要上下文,再交给智能体推理。这不再是提前将所有数据塞进上下文,而是走“即时”路线:智能体只维护轻量级的标识符(如文件路径、存储查询、网页链接),通过工具在运行时按需动态加载数据到上下文中。这一做法很像人类认知的方式:我们不会记住整个信息库,而是依赖文件系统、收件箱、书签等外部系统,在需要时检索信息。
04 — 长程任务如何解决上下文问题
当任务从“分钟级”拉长到“小时级”,上下文窗口必然爆掉。针对这一难题,Anthropic 内部总结了三把“瑞士军刀”。
1、压缩
例如在 Claude Code 中,通过将消息历史传给模型进行总结和压缩。模型会做一次“精加工”,丢弃冗余的工具输出或消息,只保留架构决策、未解决的错误和实现细节等真正关键的信息。优先对智能体深处的工具调用及结果进行压缩,效果通常最佳——一旦工具在一次调用后深埋于消息历史里,后续智能体便无需再看原始结果。
2、结构化笔记
简单说就是智能体记忆。让智能体定期将笔记写入持久化的“抽屉”中,这个“抽屉”在上下文窗口之外,等到需要时再拉回来。这样就能把上下文空间腾给即时使用的信息。
3、子智能体架构
这是绕过上下文限制的另一种方案。与其让一个智能体在整个项目中扛着重量级上下文,不如让专门的子智能体用轻量上下文去处理集中的任务。主智能体负责高级计划与协调,子智能体则深入执行具体的技术工作或利用工具搜索信息。每个子智能体可能耗费数万个 token 做大量探索,但最终只返回一份浓缩的总结(通常 1,000-2,000 token)。这样实现了关注点的清晰分离——详细的探索上下文被关在子智能体内部,而主智能体专注综合与分析。Anthropic 在其多智能体研究系统中测试过,在分析 100 页 PDF 的任务上,子智能体方案比单智能体系统准确率提升了 27%,而 token 消耗反而降低了 40%。
05 — 结语
在提示词时代,我们像搭讪高手,用一句话吸引模型;到了上下文时代,我们像电影导演,用整场戏讲好故事。当你的智能体开始自己查资料、写笔记、指挥子任务时,请记住:限制它的从来不是智商,而是你给它的注意力预算。




