一、决策树模型训练
先从训练集说起。建立决策树模型的第一步,当然是准备一份可靠的数据。这里直接采用 scikit-learn 自带的葡萄酒数据集,这是分类任务中非常经典的案例,非常适合用来练习和实践。
先导入必需的 Python 工具包:
import pandas as pd
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz接下来加载数据集,了解其中的结构与内容。
wine = load_wine()加载后可以确认数据的基本情况:总共包含178条样本,13个特征维度,目标变量有3个分类类别。

如果想更直观地查看数据,可以借助 Pandas 将特征与目标合并显示:
pd.concat([pd.DataFrame(wine.data, columns=wine.feature_names), pd.DataFrame(wine.target)], axis=1)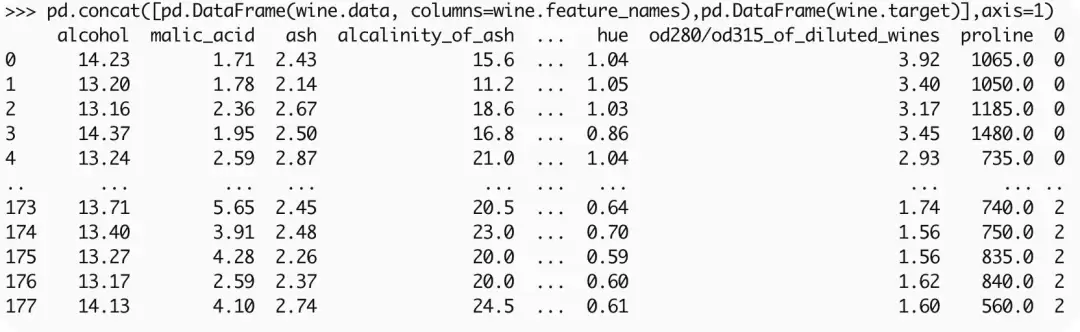
随后,将数据集划分为训练集和测试集。这里让测试集占30%,训练集占70%,这是实践中较为常见的比例。
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)接着便可以构建并训练决策树模型。本示例选择基于信息熵的 ID3 算法进行建模。
# 选择信息熵模式即ID3算法建立决策分类树模型
clf = DecisionTreeClassifier(criterion="entropy")
# 用训练数据建立决策树
clf = clf.fit(Xtrain, Ytrain)
# 用以上训练的决策树,给测试数据返回打分
score = clf.score(Xtest, Ytest)
模型训练完成后,仅看评分还不够直观。利用 graphviz 将决策树可视化导出,整棵树的判断逻辑便一目了然。
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf,
out_file = None,
feature_names= feature_name,
class_names=["琴酒","雪莉","贝尔摩德"],
filled=True,
rounded=True)
graph = graphviz.Source(dot_data)
graph.view()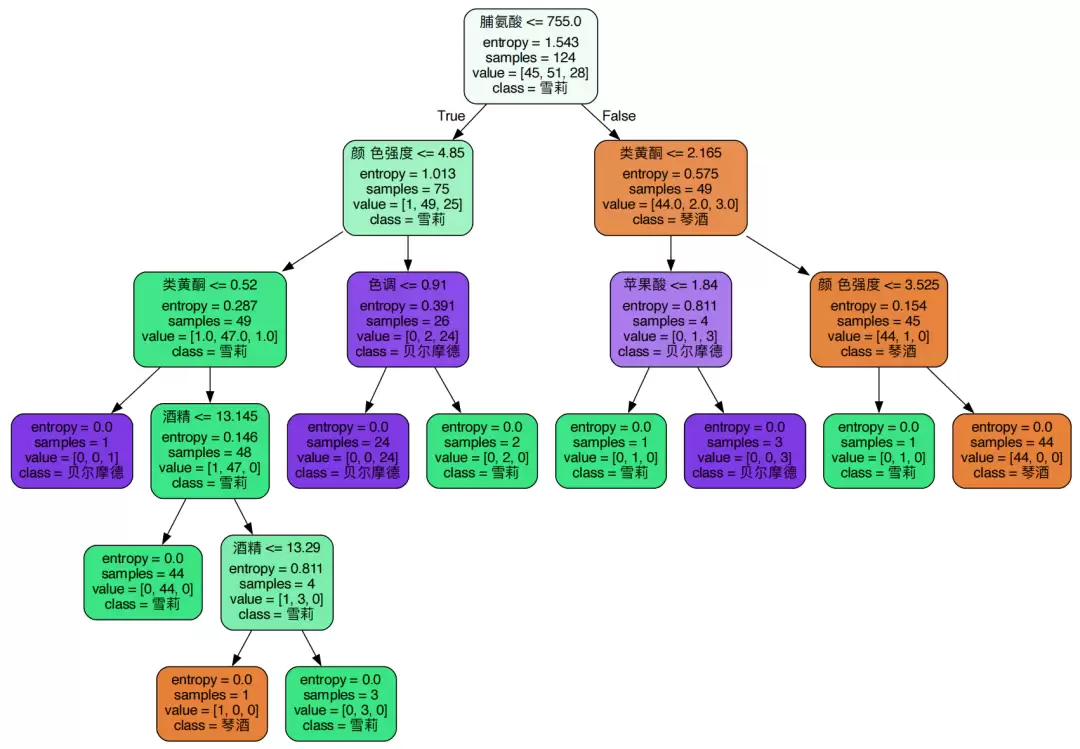
二、决策树模型微调
模型虽然跑起来了,但你是否直接使用了默认参数?对于决策树而言,默认参数几乎不可能达到最优效果,尤其因为它天生容易过拟合。因此,调参才是让模型从“能用”变为“好用”的关键环节。
1、决策树分类树重要参数介绍
分类树涉及多个参数,核心都在下面这个类的定义中。更详细的说明可参考官方文档。
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0, monotonic_cst=None)
2、随机相关参数调整
splitter、random_state 和 max_features 这三个参数控制着树在构建过程中的随机性。不同数据集的“黄金组合”往往不同,下图是 DeepSeek 给出的推荐组合,但实际调优仍需要根据自己数据的训练结果反复微调,不存在万能药方。

3、剪枝相关参数调整
必须高度警惕:决策树是一个天然容易过拟合的模型。它在训练集上表现近乎完美,但一到测试集上就可能原形毕露。因此,剪枝是决策树调优中绕不开的核心环节。
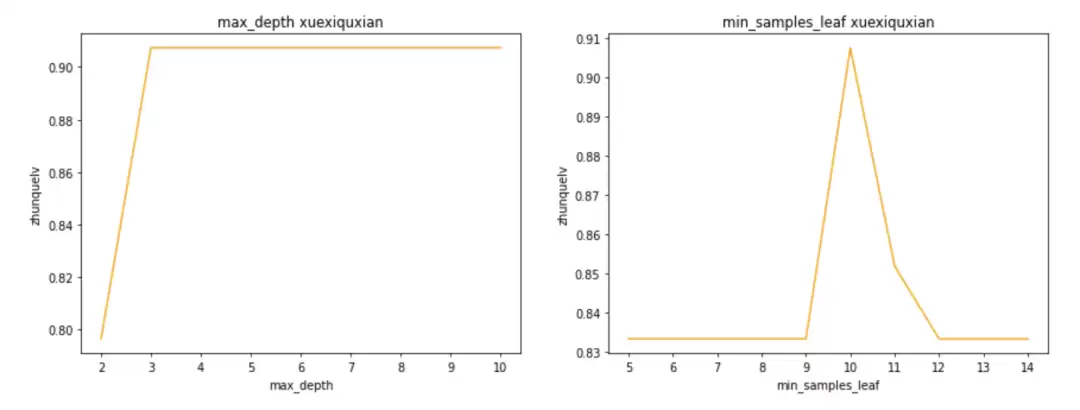
常用的剪枝参数包括 max_depth、min_samples_leaf、min_samples_split、max_features 以及 min_impurity_decrease 等。如何找到这些参数的最优值?最直观的方法是绘制学习曲线——以某个超参数的取值作为横坐标,模型的准确率作为纵坐标,找到曲线的峰值位置。
L = []
L1 = []
# 调节决策树最大深度
for i in range(2, 11):
dct = DecisionTreeClassifier(criterion='entropy'
, random_state=10
, splitter='random'
, max_depth=i
, min_samples_leaf=10
, min_samples_split=10)
dct.fit(Xtrain, Ytrain)
L.append([i, dct.score(Xtest, Ytest)])
# 调节一个节点在分枝后的每个子节点都必须包含的训练样本个数
for j in range(5,15):
dct1 = DecisionTreeClassifier(criterion='entropy'
, random_state=10
, splitter='random'
, max_depth=3
, min_samples_leaf=j
, min_samples_split=10)
dct1.fit(Xtrain, Ytrain)
L1.append([j, dct1.score(Xtest, Ytest)])
a = pd.DataFrame(L, columns = ['max_depth', 'zhunquelv'])
b = pd.DataFrame(L1, columns = ['min_samples_leaf', 'zhunquelv'])
A = [a, b]
plt.figure(figsize=(15, 5), dpi=70)
for k,v in enumerate(A):
plt.subplot(1,2,k+1)
plt.plot(v.iloc[:,0], v.zhunquelv, color='orange')
plt.xticks(v.iloc[:,0])
plt.xlabel(v.columns[0])
plt.ylabel('zhunquelv')
plt.title(f'{v.columns[0]}学习曲线');
plt.sa vefig('learning_curve.png', bbox_inches='tight')从输出的学习曲线可以看到,max_depth 取 3 时准确率最高,min_samples_leaf 取 10 时效果最佳。
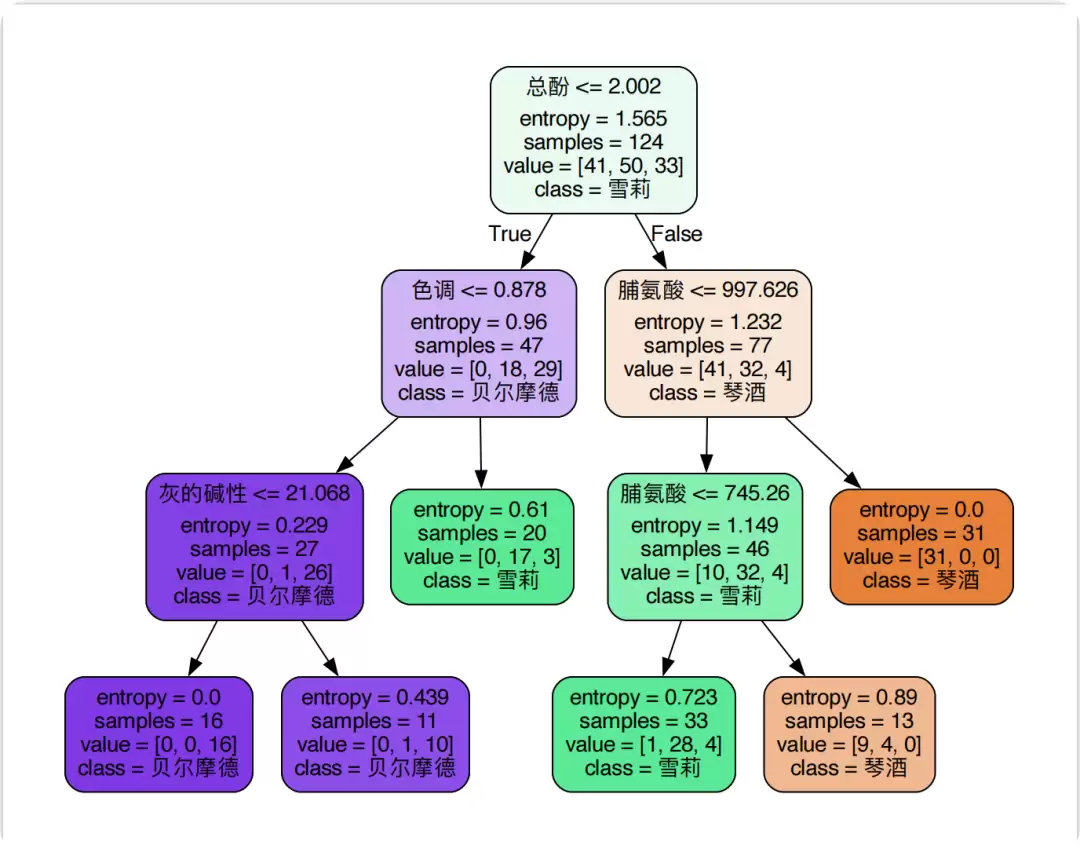
再看这两个参数组合下的决策树结构:
其余剪枝参数的调节思路完全相同。建议先从 max_depth 开始,确定最优值之后依次调节其他参数,直到模型达到比较理想的状态。这种每次只调一个参数的策略本质上是一种局部最优的贪心思路,但在实践中通常效果不错。
4、网格搜索选取最佳参数
如果对模型精度有更高要求,并且不太在意训练时长,那么网格搜索是一种更彻底的优化方式。它会把预定义的所有参数组合全部跑一遍,并结合交叉验证选出最优参数。听起来很完美,但代价是计算量可能非常庞大。因此,网格搜索更适合在参数空间不大且计算资源充裕的情况下使用。
从实践经验来看,局部最优往往已经能满足大多数场景,网格搜索更像是“锦上添花”的步骤。
三、训练后的决策树模型文件保存
模型调优完成后,没必要每次重复训练。将其保存下来是最基本的操作。
# 通过pickle来保存训练后的模型文件
import pickle
with open('decision_tree_model.pkl', 'wb') as file:
pickle.dump(clf, file)四、加载训练的决策树模型文件,以及对新数据的预测
保存好模型之后,后续需要对新数据进行预测时,直接加载即可。
with open('decision_tree_model.pkl', 'rb') as file:
clf_loaded = pickle.load(file)
new_data = [[13.17, 2.59, 2.37, 20, 120, 1.65, 0.68, 0.53, 1.46, 9.3, 0.6, 1.62, 840]]
prediction = clf_loaded.predict(new_data)
print(f'预测类别:{prediction[0]}')
五、小结
以上就是利用决策树模型对葡萄酒数据进行分类的完整流程,涵盖了训练、调参、保存以及预测。但需要强调的是,这只是一个入门示例。在实际业务数据上,参数调优仍需反复测试与迭代。
决策树的应用场景远不止分类,这里简要总结如下:
- 分类问题:例如判断一封邮件是否为垃圾邮件,这是最常见的使用场景。
- 回归问题:通过特征预测连续数值,比如利用房屋属性预测房价。
- 特征选择:决策树天然能够评估特征的重要性,这对理解数据非常有帮助。
- 异常检测:例如检测信用卡交易是否存在欺诈行为。
- 决策分析:在营销场景中,可根据用户特征预测其购买概率,辅助制定精准策略。




