9月末的杭州细雨绵绵,但云栖小镇里那股AI的热浪却丝毫未减,反而让人感到暑气未消。
9月24日,2025年云栖大会如约开幕。发布会上,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭登台,分享了题为《超级人工智能之路》的主题演讲。
回想2024年云栖大会,那是吴泳铭接手阿里云一年多后的首次正式亮相。彼时他曾断言:生成式AI最大的想象力,绝不仅仅是手机上多出一两个超级App,而是接管数字世界、改变物理世界。一年前,这番话听起来更像一个愿景;一年后的今天,愿景已化作一张更加清晰的路线图,甚至透着一股激进的冲劲。
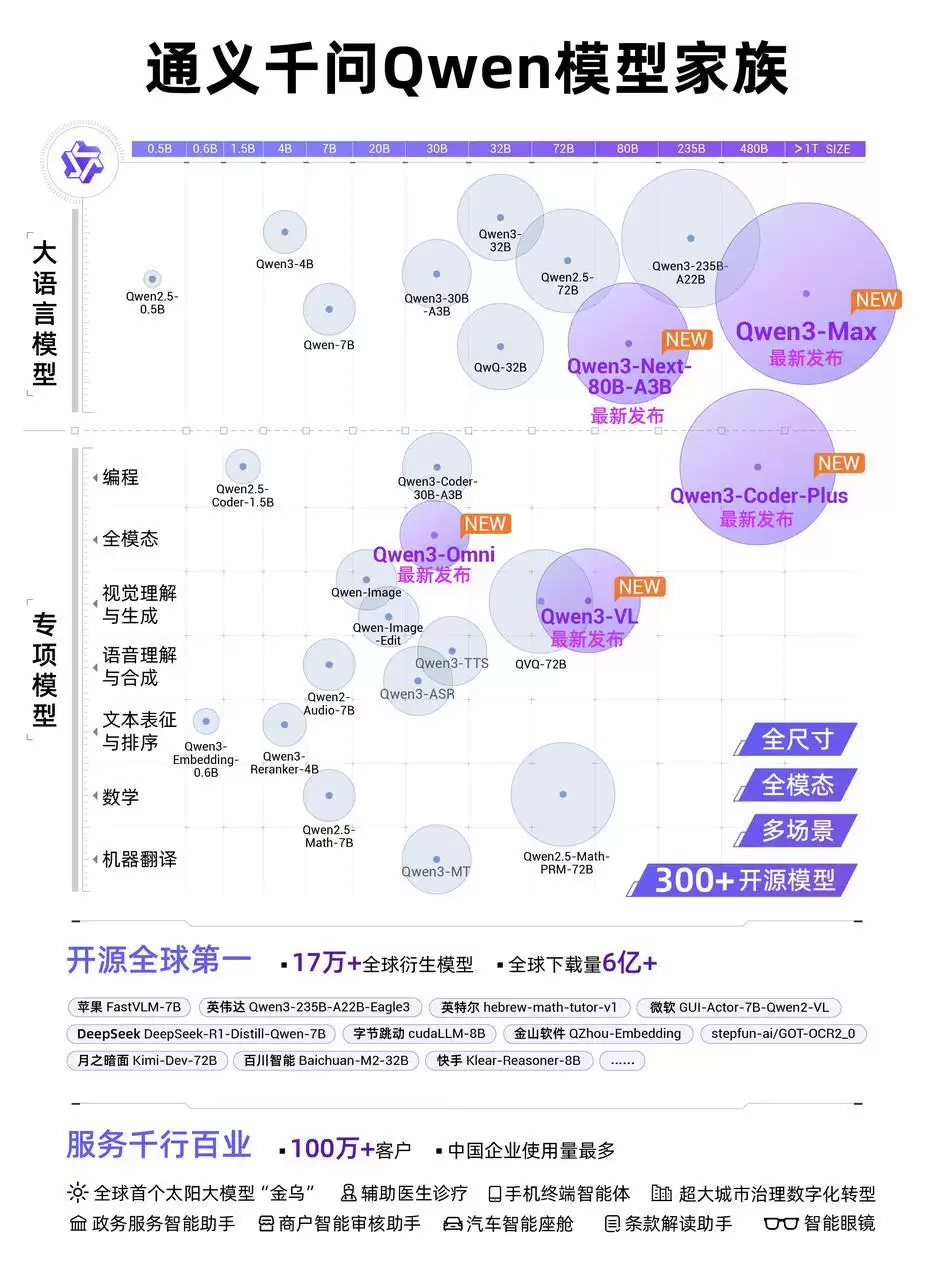
本次云栖大会,阿里云发布的新品令人目不暇接。例如旗舰模型Qwen3-Max,这是通义大模型家族中性能最强的产品,据称性能已超越GPT-5、Claude Opus 4等竞品,在LMArena榜单中跻身全球前三。
除旗舰款外,阿里还一口气推出了六款新模型:下一代基础模型架构Qwen3-Next及系列模型、编程模型Qwen3-Coder、视觉理解模型Qwen3-VL、全模态模型Qwen3-Omni、视觉基础模型Wan2.5-preview、语音大模型通义百聆。七款模型齐发,诚意十足。

△来源:阿里云
不过,更值得深究的,是吴泳铭抛出的两个颇为激进的判断。
第一个判断非常明确:大模型就是下一代操作系统。大模型将“吞噬”软件,使任何人都能用自然语言创造出无限多的应用。未来,几乎所有与计算世界交互的软件,可能都不再是如今的商业软件,而是由大模型生成的Agent。基于这一判断,过去几年阿里云从底层算力、中间基础设施到上层云服务,对整个操作系统进行了重构,以适应大模型带来的底层技术栈变革。
第二个判断顺延这一逻辑:超级AI云,就是下一代的计算机。以计算机发展历程作类比,自然语言是AI时代的编程语言,Agent是新软件,Context是新Memory,而LLM将成为承载用户、软件和AI计算资源交互调度的中间层——即AI时代的操作系统。阿里云的目标,正是构建这个“超级AI云”,为全球提供智能算力网络。
今年2月,阿里已宣布一项为期三年、总投资3800亿元的AI基础设施建设计划。而吴泳铭今天又补充了新目标:为迎接ASI时代的到来,到2032年,阿里云全球数据中心的能耗规模将比2022年提升10倍。
阿里云还首次明确提出了自己的AI发展战略和目标:不是之前热议的AGI(通用人工智能),而是更进一步——ASI(超级人工智能)。吴泳铭详细解读了通往超级人工智能之路的三个阶段:
第一阶段,“智能涌现”——AI通过学习人类(如全世界的知识集合),具备泛化智能能力,逐步发展出推理能力;第二阶段,“自主行动”——AI掌握工具使用和编程能力,开始“辅助人”,这也是行业目前所处的阶段;第三阶段,“自我迭代”——AI通过连接物理世界的全量原始数据,实现自主学习,最终“超越人类”。
2025年,全球大模型领域在纠结中前行。OpenAI推出GPT-5后,效果与市场预期差距较大,关于模型创新停滞、遇到瓶颈的声音不绝于耳;但另一边,Meta、OpenAI的资本投入却一个比一个激进——谁都不想错过这轮技术革命。如今,阿里云用实际行动表明:不仅要投入,还要加倍激进地投入。
市场对阿里云新战略的反应同样热烈。今天阿里港股持续走高,盘中大涨超9%,创下2021年10月以来的新高。
模型七连发,饱和式投入
云栖大会前夕,阿里Qwen大模型团队负责人林俊旸就在推特上预告:我们将发布超过6个新品,而且都不是“小东西”。正式发布时,数量只多不少。阿里云CTO周靖人在台上分享PPT,翻页飞快,语速紧凑,但依旧超时不少。
阿里云共推出七款全新模型,每款的体量和性能提升幅度都相当重磅:
Qwen3-Max:旗舰模型,预训练数据量达36T tokens,总参数超万亿,Coding和Agent工具调用能力显著提升;
Qwen-Next:下一代模型架构及系列模型,总参数80B,但仅激活3B就能与千问3旗舰版235B模型相当,训练成本比Qwen3-32B大幅降低超90%;
Qwen 3-VL(视觉理解):不仅能精准解读图片、图表,还实现了突破——“视觉编程”能力,可将视觉设计稿直接转化为前端代码,并能操作手机和电脑,从“看”进阶至理解和执行;
Qwen3-Coder(代码模型):生成速度、代码质量和安全性均有明显提升,可轻松完成代码补全、Bug修复乃至一键生成完整项目等复杂任务;
Qwen3-Omni:原生多模态模型,兼具“听、说、看、写”能力,与人对话自然流畅,既能理解音视频,又不丢失文字和图像能力,适合车载、眼镜、手机等随身AI场景;
通义万相Wan2.5-preview:全新视觉基础模型,支持文生视频、图生视频、文生图和图像编辑,还能生成与画面匹配的人声、音效和音乐BGM;
通义百聆:全新语音模型家族,涵盖语音识别、语音合成等子模型,例如Fun-CosyVoice可提供上百种预制音色,适用于客服、销售、直播电商、消费电子、有声书、儿童娱乐等场景。
△来源:阿里云
阿里云并非仅靠静态数据集来证明模型能力。在盲测的LMArena等权威排行榜上,旗舰模型Qwen3-Max的预览版本已位列Chatbot Arena第三。
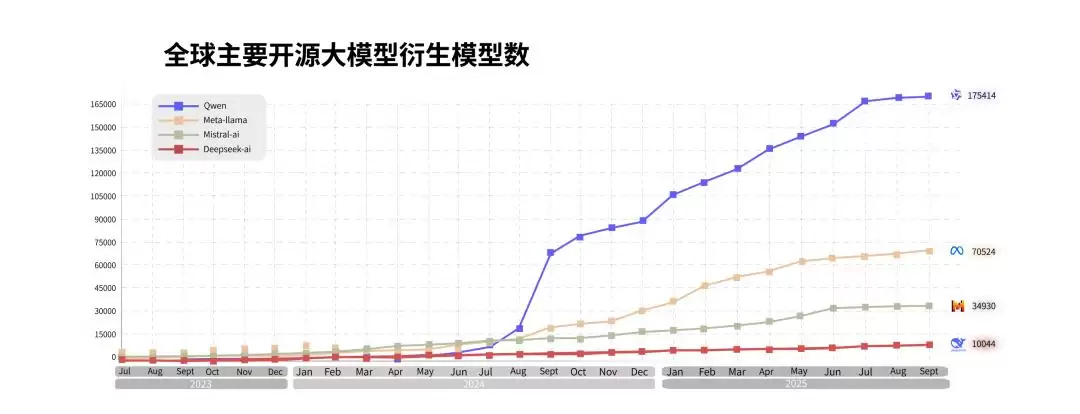
DeepSeek引爆全球AI行业之后,国内开源模型之争也被点燃,与去年各家闭门造车的状态形成鲜明对比。无论国内还是海外,今年都经历了一轮开源模型大战,几乎所有仍在投入模型的厂商均加大了开源力度。而阿里,是国内巨头中对开源路线最为激进的一家。
这一方面因为阿里是国内最早一批做模型开源、建设模型生态的公司,这些投入如今已换回实际回报,阿里自然有动力更激进地投入。DeepSeek和Qwen,是少数在全球范围内真正闯出知名度的模型。DeepSeek引爆开源后,Qwen也再次被全球AI圈关注,迎来新一轮爆发。截至目前,阿里通义已开源300多个模型,覆盖不同规模及全模态——LLM、编程、图像、语音、视频,一应俱全。在全球范围,通义大模型也是开源模型中的领军者,全球下载量突破6亿次,衍生模型超17万个。
△来源:阿里云
除模型外,阿里云今年还发布了全新Agent开发框架ModelStudio-ADK——Agent能自主规划、调用模型,自然也带来更多算力消耗。阿里云披露了一个数据:随着模型能力提升和Agent应用爆发,过去一年,阿里云百炼平台的模型日均调用量增长了15倍。在模型开源上的投入,不仅加速了模型迭代,也已转化为云上收入。最新一季财报显示,阿里云季度收入同比大涨26%,AI相关收入连续8个季度实现三位数增长。据国际权威市场调研机构英富曼(Omdia)报告,2025年上半年,中国AI云市场规模达223亿元,阿里云占比35.8%位列第一,市场份额高于第二到第四名的总和。
“做LLM时代的安卓”
2024年,OpenAI的Sora发布、GPT-5研发停滞,技术路线的讨论曾让全球大模型领域情绪低落。但如今,这种情绪基本消散。就在云栖大会前几天,英伟达刚宣布对OpenAI投资1000亿美元。吴泳铭也在大会上预测,未来五年全球AI累计投入金额将超过4万亿美元。
阿里云CTO周靖人在会后接受《智能涌现》采访时坦言:现在整个行业对技术路线的大方向分歧已很少,全球几乎所有公司都在激进地投入AI竞争,快速发布模型。问题在于各家的具体做法。“现在的模型竞争,已经是系统和系统之间的竞争了。”他说,“模型发展创新不存在憋大招的说法,这跟底层的基础设施、云都是相辅相成的。”
“系统”怎么理解?这可能更多指向一种AI战略选择。DeepSeek改变了全球AI叙事之后,所有大厂都在增加AI投入,从底层算力到云计算、开源,无一例外。各家的AI路线分野已形成有趣的对照——拿最近的腾讯生态大会来说,腾讯在AI上谈得更多的是场景和在B端、C端落地,先把AI用在自己的业务里,再转向对外;字节则更像iOS,从模型到应用,也采取军团式打法,区别在于字节习惯先闭源卷出更好的版本,开源节奏稍慢。
2023年对阿里云而言是个关键节点。吴泳铭接任阿里云CEO后,提出“AI驱动、公共云优先”战略。此后,阿里云主要完成了几件事:一是回归公共云,砍掉重交付、利润低的项目;二是将大量预算投入AI,不仅对外投资了AI六小龙等初创企业,也大力投入到模型自研、开源和基础设施重构。如今阿里云的路线更靠近谷歌——从底层算力基础设施、中间云计算到上层模型,均采取全栈自研、自主构建策略,并确保每层在国际范围内领先。
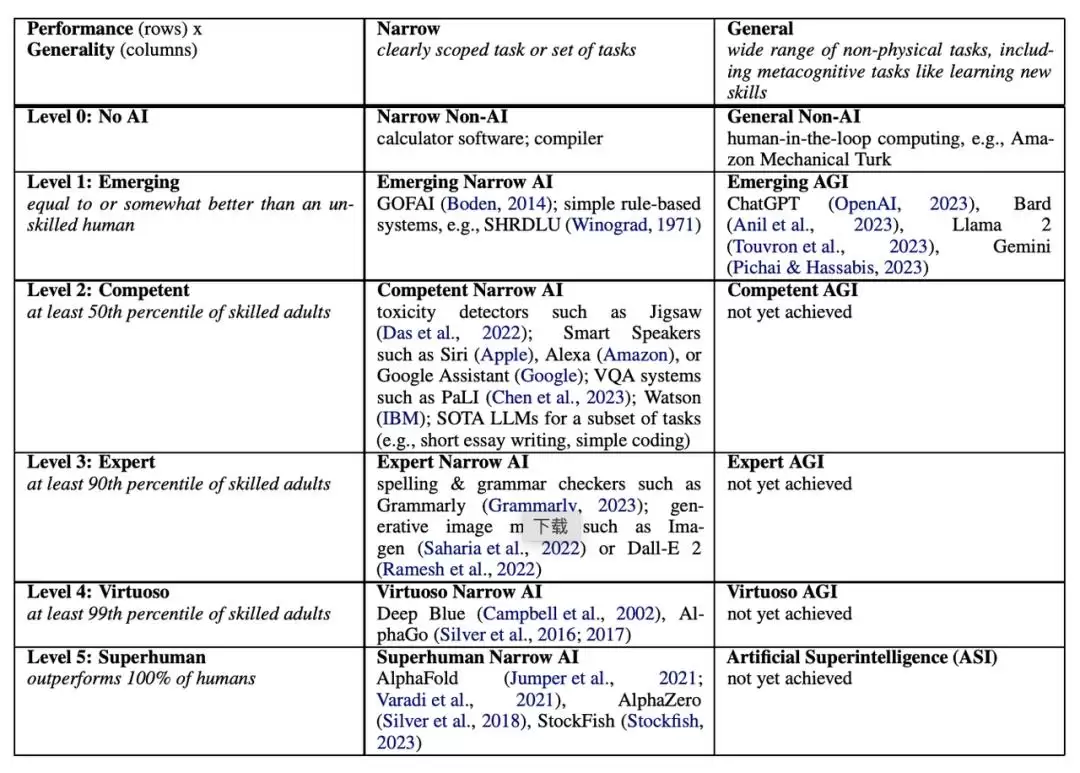
今天阿里提出的ASI并非新名词。今年3月,Google DeepMind披露了“AGI六级路线图”,与阿里的ASI三部曲有不少对应之处:ASI的第三阶段“超越人类”,与DeepMind定义的AGI Level 6颇为相似。
△来源:DeepMind
激进投入AI,也源于AI与云计算已密不可分。阿里云甚至宣布了新定位,变成“全栈人工智能服务商”。“Token就是未来AI世界的电。”吴泳铭如是说。毫无疑问,我们仍处于AI时代的早期。当前模型调用量占企业云消耗的比例还很小,但趋势变化至关重要。在会后采访中,阿里云通义大模型业务总经理徐栋对媒体表示:一年前,大模型的调用量更多来自离线任务的数据打标等;而一年后,在线任务的调用量已增长数十倍,各行各业的企业正将大模型嵌入生产流程——这证明大模型正在快速给云市场带来增量。
过去16年,提供数字世界的“水和电”,曾是阿里云对自身市场价值的一贯阐释——这与如今阿里云喊出的“LLM时代的安卓”,其实一脉相承。无论是提出新路线图,还是确立新定位,阿里都需要在AI时代找到主场,在应用市场爆发前占据领先地位,这一目标已愈发清晰。




