1. 什么是过拟合?
过拟合(Overfitting)是机器学习模型训练过程中一个老生常谈但又极易踩坑的问题。简单来说,就是模型在训练数据上表现得像个“学霸”,但一到未知的测试数据上就“翻车”,成绩大幅下滑。背后的原因很直白:模型把训练数据里的细节和噪声都“背诵”下来了,却没有真正理解背后的通用规律。换句话说,它记住了具体例子,却没能学会抽象规则。
当模型出现以下几种信号时,基本可以判定它已经过拟合了:
- 训练集准确率高得离谱(接近100%),但验证集/测试集准确率明显掉队;
- 模型对训练数据中的噪声过度敏感,把随机的波动也当成了信号;
- 模型复杂度远高于问题本身所需,参数量远超数据能支撑的范围。
2. 数据层面的解决方案
2.1 增加训练数据量
数据是模型的燃料。更多、更丰富的数据意味着模型能接触到更多样的模式,从而减少“死记硬背”的机会。实践中,除了直接收集更多真实数据,还可以借助数据增强技术(后面会细说),或者考虑迁移学习——利用预训练模型的知识来降低对小数据的依赖。
2.2 数据增强(Data Augmentation)
通过对现有数据进行合理的变换,可以凭空“造”出更多训练样本,相当于扩充了数据集。对于图像任务,常见的操作包括旋转、翻转、缩放、裁剪、颜色变换;文本领域可以用同义词替换、随机删除、回译;音频领域则有添加噪声、变速变调等。数据增强不仅增加了数据量,还引入了一定的鲁棒性,让模型学会应对真实世界中各类变化。
# 图像数据增强示例(使用albumentations库)
import albumentations as A
transform = A.Compose([
A.RandomRotate90(),
A.Flip(),
A.Transpose(),
A.RandomBrightnessContrast(p=0.5),
A.RandomGamma(p=0.5),
])
2.3 特征选择与降维
冗余或不相关的特征会迫使模型学习无意义的关联,从而增加过拟合风险。通过减少特征维度,可以有效降低模型复杂度。常用方法包括主成分分析(PCA)、线性判别分析(LDA)、基于树模型的特征重要性评估、递归特征消除(RFE)等。一句话:能少用就用少用,特征精简往往比堆参数更管用。
3. 模型层面的解决方案
3.1 正则化技术
正则化通过在损失函数中加入惩罚项,限制模型参数的大小,防止模型过于“嚣张”。常见的三种正则化方式各有特色:
L1正则化(Lasso)
惩罚项为 λ∑|w|,优点是能产生稀疏解——把不重要的特征权重直接压到零,相当于顺便做了特征选择。
L2正则化(Ridge)
惩罚项为 λ∑w²,会让权重趋向于较小值但不会归零,适合特征都相对重要的情况。
Elastic Net
结合了L1和L2,公式为 λ₁∑|w| + λ₂∑w²,适合特征数目较多、且存在分组相关性的场景。
# TensorFlow/Keras中的正则化示例
from tensorflow.keras import regularizers
model = tf.keras.Sequential([
tf.keras.layers.Dense(64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)),
tf.keras.layers.Dense(10)
])
3.2 Dropout
Dropout的思路非常简洁:在训练过程中随机“丢弃”一部分神经元(即让它们的输出暂时为零),迫使每个神经元去适应更独立的模式。这样一来,相当于同时训练了多个不同的子网络,最终模型的泛化能力会显著提升。实现也很方便,只需在关键层后插入Dropout层,丢率通常在0.2~0.5之间。
# Dropout层使用示例
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5), # 丢弃50%的神经元
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.3), # 丢弃30%的神经元
tf.keras.layers.Dense(10, activation='softmax')
])
3.3 早停法(Early Stopping)
早停法直击过拟合的痛点:当验证集性能不再提升甚至开始下降时,立刻停止训练。关键在于设置合理的耐心值(patience)——连续多少个epoch验证损失没有改善就停。同时记得恢复最佳权重(restore_best_weights=True),避免最后几步反而变差。如果再配合学习率调度,效果会更理想。
# Early Stopping回调示例
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
patience=10, # 连续10个epoch验证损失不改善则停止
restore_best_weights=True, # 恢复最佳权重
verbose=1
)
model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=100,
callbacks=[early_stopping])
3.4 批量归一化(Batch Normalization)
批量归一化虽然最初是为了解决训练中内部协变量偏移、加速收敛而设计的,但它附带的正则化效果同样不可忽视。通过对每一层的输入做归一化处理,BN层让梯度更稳定,从而允许使用更高的学习率,同时也能在一定程度上减少过拟合。在实践中,BN层几乎是深度神经网络的标配。
4. 训练策略层面的解决方案
4.1 交叉验证(Cross-Validation)
将数据集分成多个子集,轮流作为验证集,可以更稳定地评估模型性能,避免单次划分带来的偏差。最常用的是K折交叉验证(K-Fold CV),尤其是分层K折(Stratified K-Fold),能保证每折中各类别比例与整体一致。留一法(Lea ve-One-Out)在小数据集上也很常见,但计算开销大。
# 5折交叉验证示例
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print(f"交叉验证准确率: {scores.mean():.3f} (±{scores.std():.3f})")
4.2 集成学习(Ensemble Learning)
集成学习通过组合多个模型的预测结果来降低过拟合风险。Bagging(如随机森林)并行训练多个模型,然后投票或取平均;Boosting(如XGBoost)顺序训练,每个新模型重点关注前序模型犯错的样本;Stacking则用元模型去整合多个基模型的输出。集成方法通常能带来显著的泛化提升,但会牺牲一定的训练速度。
4.3 学习率调度
动态调整学习率可以帮助模型跳出局部最优,同时避免在后期过度震荡。常见的策略有指数衰减、余弦退火,以及Keras中内置的ReduceLROnPlateau——当验证损失进入平台期时自动降低学习率。用好了学习率调度,过拟合的风险也会相应降低。
5. 模型架构层面的解决方案
5.1 简化模型复杂度
减少网络层数、减少每层的神经元数量、或者使用更简单的模型架构(比如用线性模型替代深度网络),都是直接有效的防过拟合手段。在很多实际问题上,简单模型往往比花里胡哨的深层网络表现更好,尤其是在数据量有限时。
5.2 权重约束
通过限制权重的最大范数值(max norm),可以防止某些神经元权重过大,从而抑制过拟合。Keras中可以用kernel_constraint参数轻松实现,例如设置max_norm(3.0)表示权重的L2范数不能超过3。这是一种非常“暴力”但有效的正则化手段。
# 权重约束示例
from tensorflow.keras.constraints import max_norm
model.add(Dense(64, kernel_constraint=max_norm(3.0), # 限制权重最大范数为3
activation='relu'))
6. 评估与监控
6.1 学习曲线分析
绘制训练和验证损失曲线是最直观的过拟合诊断方法。典型的过拟合曲线:训练损失持续下降,验证损失先降后升(出现“U”形),且两者之间的差距逐渐拉大。如果看到这种图形,就该果断采取防过拟合措施了。
6.2 混淆矩阵与分类报告
除了整体准确率,还需深入查看模型在每个类别上的表现。混淆矩阵能揭示模型是否对某些类别过度自信,而对其他类别视而不见——这也是过拟合的一种表现,尤其当某类样本很少时。
6.3 特征重要性分析
理解模型依赖哪些特征做决策,有助于判断是否引入了无关特征导致过拟合。树模型可以直接输出特征重要性,线性模型则看权重绝对值大小。如果某些不重要特征的权重异常大,很可能就是过拟合的信号。
7. 实践建议与组合策略
7.1 针对不同场景的推荐方案
下面的流程图给出了从数据检查、模型选择到策略组合的完整决策路径,可以帮助快速定位最适合的方案。
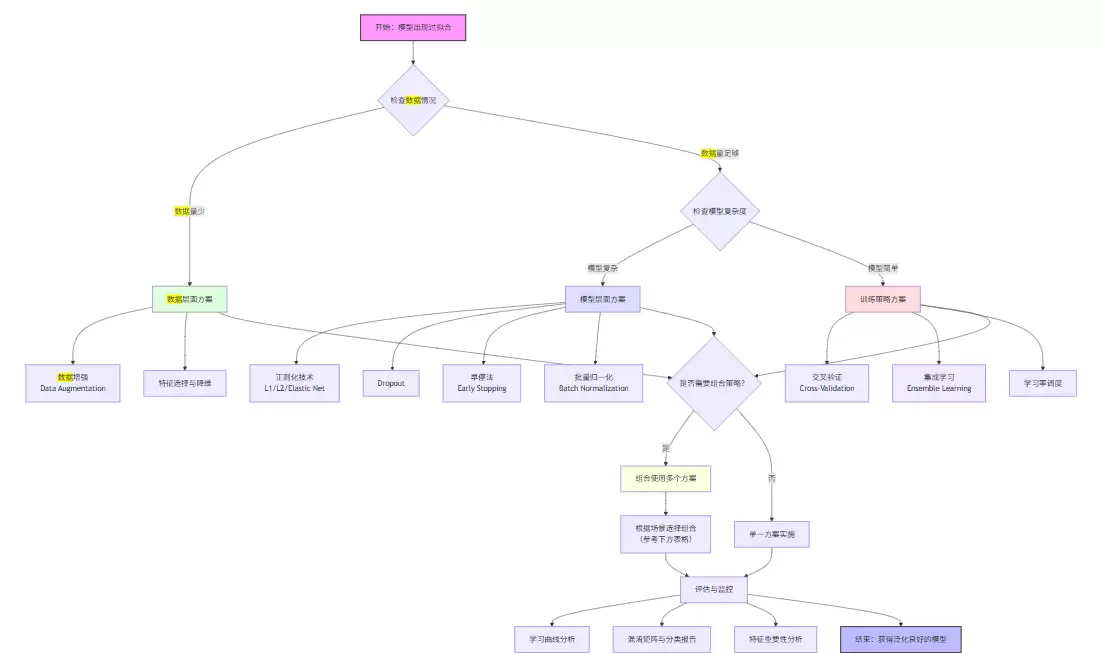
| 场景类型 | 推荐方案 | 理由 |
|---|---|---|
| 小样本数据 | 数据增强 + Dropout + 早停法 | 弥补数据不足,防止过拟合 |
| 高维特征 | L1正则化 + 特征选择 | 减少特征维度,提高泛化 |
| 深度神经网络 | Dropout + BN层 + 权重衰减 | 综合应对深度网络过拟合 |
| 传统机器学习 | 交叉验证 + 集成学习 | 稳定评估,提高泛化 |
7.2 组合使用多个方案
在实际项目中,单一技术往往不够,组合拳才是常态。下面是一个典型的综合防过拟合模型构建示例:
# 综合防过拟合策略示例
def create_robust_model(input_shape, num_classes):
model = tf.keras.Sequential([
# 输入层
tf.keras.layers.Input(shape=input_shape),
# 第一层:Dense + BN + Dropout
tf.keras.layers.Dense(256,
kernel_regularizer=tf.keras.regularizers.l2(0.01)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.3),
# 第二层
tf.keras.layers.Dense(128,
kernel_regularizer=tf.keras.regularizers.l2(0.01)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.3),
# 输出层
tf.keras.layers.Dense(num_classes, activation='softmax')
])
return model
# 训练配置
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True),
tf.keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)
]
下面是一个完整的端到端实战示例,包含数据生成、模型构建、训练、评估和过拟合对比。代码可直接复制运行,生成模拟数据、训练两个对比模型(一个带防过拟合技术,一个故意设置成容易过拟合),并通过4个子图直观展示效果。
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 数据加载与预处理
print("1. 生成模拟数据...")
X, y = make_classification(
n_samples=5000, # 总样本数
n_features=20, # 特征数
n_informative=15, # 有效特征数
n_redundant=5, # 冗余特征数
n_classes=3, # 类别数
n_clusters_per_class=2, # 每类簇数
random_state=42
)
# 划分训练集、验证集、测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
X_test = scaler.transform(X_test)
print(f"训练集: {X_train.shape}, 验证集: {X_val.shape}, 测试集: {X_test.shape}")
# 2. 模型构建函数(复用前面的 create_robust_model)
def create_robust_model(input_shape, num_classes):
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=input_shape),
# 第一层:Dense + L2正则化 + BN + Dropout
tf.keras.layers.Dense(256,
kernel_regularizer=tf.keras.regularizers.l2(0.01)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.3),
# 第二层
tf.keras.layers.Dense(128,
kernel_regularizer=tf.keras.regularizers.l2(0.01)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.3),
# 输出层
tf.keras.layers.Dense(num_classes, activation='softmax')
])
return model
# 3. 创建并编译稳健模型
print("2. 构建稳健模型...")
robust_model = create_robust_model(input_shape=(20,), num_classes=3)
robust_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
robust_model.summary()
# 4. 训练配置(早停 + 学习率调度)
callbacks = [
tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True,
verbose=1
),
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=5,
min_lr=1e-6,
verbose=1
),
tf.keras.callbacks.ModelCheckpoint(
'best_robust_model.h5',
monitor='val_accuracy',
sa ve_best_only=True,
verbose=1
)
]
# 5. 训练稳健模型
print("3. 训练稳健模型...")
history_robust = robust_model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=100,
batch_size=32,
callbacks=callbacks,
verbose=1
)
# 6. 创建过拟合对比模型(无正则化、无Dropout、复杂结构)
print("4. 构建过拟合对比模型...")
overfit_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(20,)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
overfit_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), # 高学习率
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 7. 训练过拟合模型(无早停,小批量)
print("5. 训练过拟合模型...")
history_overfit = overfit_model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=150, # 更多轮次
batch_size=8, # 更小批量,更容易过拟合
verbose=1
)
# 8. 评估两个模型
print("6. 模型评估...")
# 稳健模型评估
robust_train_loss, robust_train_acc = robust_model.evaluate(X_train, y_train, verbose=0)
robust_val_loss, robust_val_acc = robust_model.evaluate(X_val, y_val, verbose=0)
robust_test_loss, robust_test_acc = robust_model.evaluate(X_test, y_test, verbose=0)
print(f"稳健模型结果:")
print(f"训练集 - 损失: {robust_train_loss:.4f}, 准确率: {robust_train_acc:.4f}")
print(f"验证集 - 损失: {robust_val_loss:.4f}, 准确率: {robust_val_acc:.4f}")
print(f"测试集 - 损失: {robust_test_loss:.4f}, 准确率: {robust_test_acc:.4f}")
# 过拟合模型评估
overfit_train_loss, overfit_train_acc = overfit_model.evaluate(X_train, y_train, verbose=0)
overfit_val_loss, overfit_val_acc = overfit_model.evaluate(X_val, y_val, verbose=0)
overfit_test_loss, overfit_test_acc = overfit_model.evaluate(X_test, y_test, verbose=0)
print(f"过拟合模型结果:")
print(f"训练集 - 损失: {overfit_train_loss:.4f}, 准确率: {overfit_train_acc:.4f}")
print(f"验证集 - 损失: {overfit_val_loss:.4f}, 准确率: {overfit_val_acc:.4f}")
print(f"测试集 - 损失: {overfit_test_loss:.4f}, 准确率: {overfit_test_acc:.4f}")
# 9. 可视化对比
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 训练/验证准确率对比
axes[0, 0].plot(history_robust.history['accuracy'], label='稳健模型-训练', color='blue', linestyle='-')
axes[0, 0].plot(history_robust.history['val_accuracy'], label='稳健模型-验证', color='blue', linestyle='--')
axes[0, 0].plot(history_overfit.history['accuracy'], label='过拟合模型-训练', color='red', linestyle='-')
axes[0, 0].plot(history_overfit.history['val_accuracy'], label='过拟合模型-验证', color='red', linestyle='--')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Accuracy')
axes[0, 0].set_title('训练集 vs 验证集准确率对比')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 训练/验证损失对比
axes[0, 1].plot(history_robust.history['loss'], label='稳健模型-训练', color='blue', linestyle='-')
axes[0, 1].plot(history_robust.history['val_loss'], label='稳健模型-验证', color='blue', linestyle='--')
axes[0, 1].plot(history_overfit.history['loss'], label='过拟合模型-训练', color='red', linestyle='-')
axes[0, 1].plot(history_overfit.history['val_loss'], label='过拟合模型-验证', color='red', linestyle='--')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Loss')
axes[0, 1].set_title('训练集 vs 验证集损失对比')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 泛化差距可视化
epochs_robust = len(history_robust.history['accuracy'])
epochs_overfit = len(history_overfit.history['accuracy'])
robust_gap = np.array(history_robust.history['accuracy']) - np.array(history_robust.history['val_accuracy'])
overfit_gap = np.array(history_overfit.history['accuracy']) - np.array(history_overfit.history['val_accuracy'])
axes[1, 0].plot(range(epochs_robust), robust_gap, label='稳健模型', color='blue', linewidth=2)
axes[1, 0].plot(range(epochs_overfit), overfit_gap, label='过拟合模型', color='red', linewidth=2)
axes[1, 0].axhline(y=0, color='gray', linestyle='--', alpha=0.5)
axes[1, 0].set_xlabel('Epoch')
axes[1, 0].set_ylabel('训练-验证准确率差距')
axes[1, 0].set_title('泛化差距对比(越小越好)')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 最终性能对比
models = ['稳健模型', '过拟合模型']
train_accs = [robust_train_acc, overfit_train_acc]
val_accs = [robust_val_acc, overfit_val_acc]
test_accs = [robust_test_acc, overfit_test_acc]
x = np.arange(len(models))
width = 0.25
axes[1, 1].bar(x - width, train_accs, width, label='训练集', color='lightblue', edgecolor='black')
axes[1, 1].bar(x, val_accs, width, label='验证集', color='lightgreen', edgecolor='black')
axes[1, 1].bar(x + width, test_accs, width, label='测试集', color='lightcoral', edgecolor='black')
axes[1, 1].set_xlabel('模型')
axes[1, 1].set_ylabel('准确率')
axes[1, 1].set_title('最终性能对比')
axes[1, 1].set_xticks(x)
axes[1, 1].set_xticklabels(models)
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.sa vefig('overfitting_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
print("7. 分析总结:")
print("-" * 50)
print("稳健模型特点:")
print("1. 使用L2正则化、Dropout、BatchNorm等防过拟合技术")
print("2. 配合早停法和学习率调度")
print("3. 训练集和验证集性能接近,泛化差距小")
print("4. 在测试集上表现稳定")
print("过拟合模型特点:")
print("1. 网络层数多、神经元多,无正则化")
print("2. 使用高学习率、小批量")
print("3. 训练集准确率高但验证集/测试集差")
print("4. 明显的训练-验证性能差距")
print("关键观察:")
print(f"• 稳健模型泛化差距: {robust_gap[-1]:.4f}")
print(f"• 过拟合模型泛化差距: {overfit_gap[-1]:.4f}")
print(f"• 稳健模型在测试集上比过拟合模型高 {100*(robust_test_acc - overfit_test_acc):.2f}%")
运行说明:
- 确保已安装所需库:
pip install tensorflow scikit-learn matplotlib numpy - 代码可直接复制运行,生成模拟数据、训练两个对比模型
- 运行后会保存最佳模型(
best_robust_model.h5)和对比图(overfitting_comparison.png) - 通过4个子图直观展示过拟合现象和防过拟合技术的效果
这个完整示例展示了从数据生成到模型评估的全流程,通过对比实验清晰地说明了组合使用多种防过拟合技术的实际效果。在真实项目中,建议从简单的基线模型开始,逐步增加复杂度,同时始终用验证集监控性能,并灵活组合上述各层面的方案。记住,没有一种方案是万能的——理解每种技术的原理和适用场景,才能真正训练出既准确又泛化的模型。
8. 总结
防止过拟合是机器学习模型训练中的核心任务。通过本文介绍的十大方案,你可以根据具体场景选择合适的策略:
- 数据层面:增加数据、数据增强、特征选择
- 模型层面:正则化、Dropout、早停法、批量归一化
- 训练策略:交叉验证、集成学习、学习率调度
- 模型架构:简化复杂度、权重约束
最佳实践建议:
- 从简单模型开始,逐步增加复杂度
- 始终使用验证集监控模型性能
- 组合使用多种防过拟合技术
- 理解每种技术的原理和适用场景




