摩尔线程迎来最新突破——在其旗舰级AI训推一体全功能GPU MTT S5000上,成功实现对智谱新一代旗舰模型GLM-5.1的Day-0极速适配。所谓Day-0,即在模型发布当天即可运行,此次不仅支持推理部署,还覆盖了训练复现的全流程。
这一能力的实现,得益于MUSA软件栈的生态兼容性。摩尔线程技术团队基于高性能SGLang-MUSA推理引擎和TileLang-MUSA算子编程语言,采用PD分离架构(Prefill/Decode分离)进行深度调优,在MTT S5000上实现了GLM-5.1的高效、高精度推理。这意味着,国产算力基础设施对前沿SOTA模型的响应速度已能同步模型发布。这背后体现了软硬协同应对复杂AI推理场景的能力,也为行业树立了新的标杆。
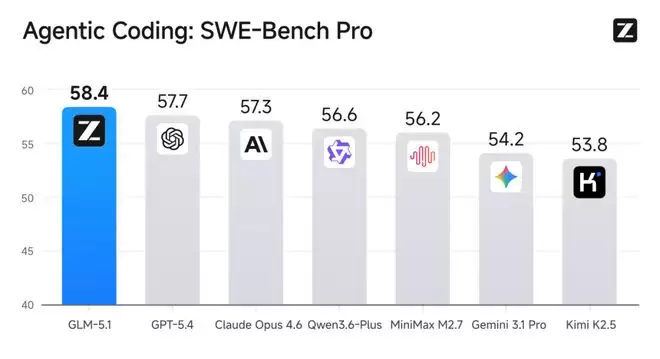
谈到GLM-5.1,智谱此次推出的确是迄今最智能的旗舰模型,也是当前全球最强的开源模型。其最大亮点在于代码能力——在最接近真实软件开发的SWE-bench Pro基准测试中,GLM-5.1直接超越了GPT-5.4和Claude Opus 4.6,刷新全球最佳成绩。此外,模型整体性能大幅提升之余,GLM-5.1在长程任务(Long Horizon Task)处理能力上实现了显著突破。与当前大多只能进行分钟级交互的模型不同,GLM-5.1可在一次任务中独立、持续工作超过8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。这意味着它已不再是仅能短暂对话的“聊天助手”,而是真正能投入实战的“工程伙伴”。
针对GLM-5.1的长程任务与代码生成特性,摩尔线程基于自研MUSA架构以及SGLang-MUSA、TileLang-MUSA等关键技术,完成了系统性的算子适配与推理性能调优。硬件底子方面:MTT S5000单卡AI算力(稠密)可达1000 TFLOPS,支持FP8到FP64的全精度计算。原生FP8加速直接提升了推理效率,结合高效的KV Cache管理,能够有效支撑极长上下文的显存需求。PD分离架构进一步将Prefill和Decode阶段解耦,降低长序列生成中的相互干扰,确保持续任务的高吞吐与低延迟。此外,MTT S5000提供784GB/s的卡间互联带宽,大规模部署时弹性扩展能力出色。通过这一套软硬协同优化,MTT S5000能够稳定承载GLM-5.1的长程任务吞吐与工程级代码推理表现。
回顾来看,从GLM-4.7到GLM-5.1,摩尔线程已连续实现发布当日的极速适配。这不仅体现了MUSA架构对主流AI生态的深度兼容,更标志着国产全功能GPU已具备大模型“从适配到部署”的全链路支撑能力。下一步,摩尔线程将持续夯实算力底座,帮助开发者快速应用前沿模型,共建更成熟的国产AI生态。




