2025年即将进入尾声。对于这一年,AI行业可以说经历了起伏与震荡。不过,就在年末,谷歌DeepMind的掌门人哈萨比斯,在一场访谈中道出了一个重磅判断:2030年,AGI必至。
当然,这并非没有前提——在此之前,还需要一到两个「Transformer级别」的核爆级突破。恰好就在NeurIPS 2025大会上,谷歌甩出了下一代Transformer的最强继任者——Titans架构。
划重点的内容来了,以下五大核心点,基本代表了DeepMind对未来12个月「关键趋势」的判断——
多模态融合彻底打通类人的视觉智能;语言与视频的深度融合;世界模型成为主流;智能体达到可靠应用水平。
哈萨比斯强调,我们应该尽快把现有的AI系统做大做强,至少它们会成为最终AGI的「关键零件」。甚至,它本身就可能是那个终极系统。
话又说回来,我们至少还需要一到两个像Transformer、AlphaGo这种级别的突破才行。
八年前,谷歌的Transformer奠基之作改变了整个AI界。如今,一个极有潜力成为Transformer的继任者——Titans架构,正式在NeurIPS 2025亮相。它融合了RNN极速响应和Transformer的强大性能,集二者之大成。即便在200万token的上下文里,Titans在召回率和准确率方面都表现最优。博客一出,可以说是全网地震。

DeepMind掌门人:2030年,AGI必至
今年早些时候,哈萨比斯就预测过,具备或超越人类能力的AGI,可能会在2030年前实现。在最近这场公开对话中,他再次强调:AGI很可能是人类历史上最具碘伏性的时刻之一,如今正在加速逼近。如果非要给一个时间表,他表示距离实现AGI也就剩下5到10年。
谈及未来愿景,哈萨比斯的声音里带着憧憬:他最大的梦想,也是奋斗一生的目标,是实现一个「丰饶时代」。那是一个人类面临的最大问题都已被解决的世界——免费的清洁能源、攻克了许多疾病、在材料科学上取得了突破。到那时,人类将进入一个全新的后稀缺时代,繁荣发展,走向星空,将意识播撒到银河系。
但即使是这种乌托邦式的图景,也伴随着问题:如果技术能解决所有难题,人类存在的目的又是什么?作为科学家,哈萨比斯对这一点感到担忧,甚至对科学方法本身都心存疑虑。

而通往AGI的道路注定不会一帆风顺。哈萨比斯指出,恶人和错误使用AI的风险真实存在,甚至「灾难性后果」已经开始显现。比如对能源或供水系统的网络攻击,已经是显而易见的攻击目标。也许还没用上最先进的AI,但这种攻击已经开始发生了。
AI带来的最严峻后果,可能是灭绝级风险。他强调,没人确切知道人类灭绝概率P(doom)是多少,但这个风险不是零。只要不是零,就必须认真对待,投入资源去应对。
对Gemini 3探索不足10%
哈萨比斯认为,Gemini最被低估的能力是它能够「观看」视频并回答相关概念性问题。他举了个例子,曾经询问Gemini电影《搏击俱乐部》中的一个场景:打架前摘下了戒指,这个动作有什么象征意义?Gemini的回答是,这代表主角脱离日常生活的象征,是对社会规范的拒绝,是一种「放弃身份」的宣言。
这种「抽象理解」能力出乎他的意料。哈萨比斯认为Gemini已经具备了某种「元认知」。另一个例子是Gemini Live功能。他认为,多模态AI的潜力,远比大多数人今天所理解的要大得多。
每次DeepMind推出新版模型时,哈萨比斯都会有一种强烈的遗憾感:自己可能连这个系统的十分之一都没来得及深入测试,就要投入下一个版本的研发了。而用户们往往会比开发人员更快地发掘新功能,把模型用到连他们都没想到的地方。
最核心的观点
哈萨比斯最核心的观点,可能是AGI的实现路径问题。他认为,距离真正的AGI还有大约5到10年。DeepMind对AGI的定义要求很高:要称得上「通用」,AI系统必须全面具备人类的所有认知能力,包括创造力和发明能力。
现在的LLM在某些领域已经非常惊艳,堪比博士水平,甚至能拿奥林匹克金牌;但在另外一些领域,它们仍然存在明显缺陷,呈现出「参差不齐」的智力表现。
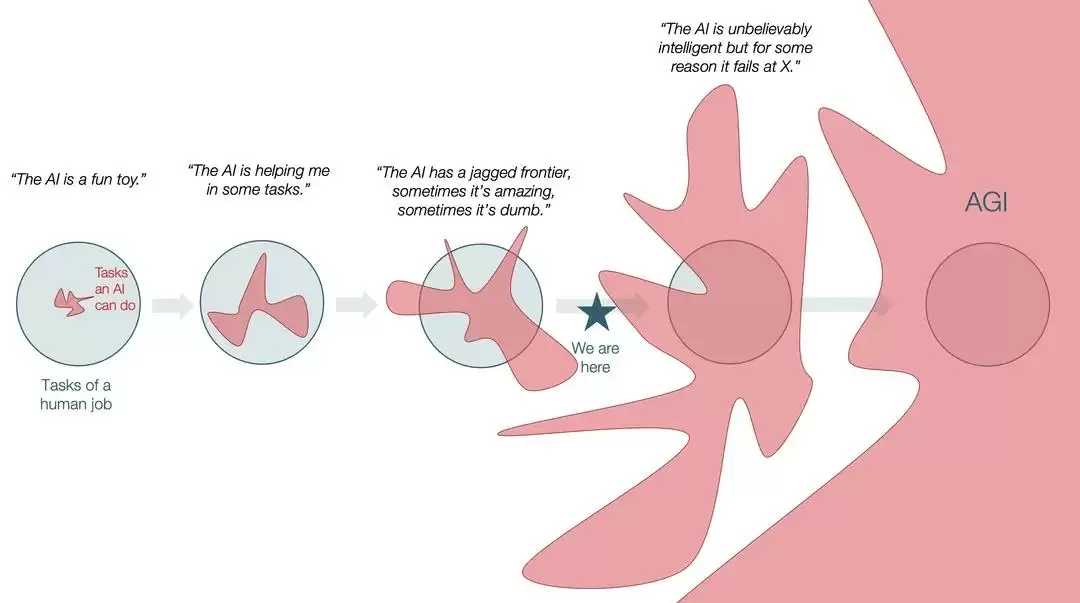
真正的AGI应当拥有「各项能力均衡发展」的稳定智能。这包括当前模型所缺失的几个关键能力:持续学习、在线学习、长期规划和多步推理。目前,大语言模型完全不具备这些能力。
他承认存在一种可能性,即规模扩展可能就是AGI系统的全部,尽管他认为这种情况可能性较小。这要求我们必须将规模扩展推向绝对极限。退一步说,规模扩展至少会成为最终AGI的「关键构件」。哈萨比斯相信,它们未来会具备这些能力,但可能还需要一两个重大技术突破——而谷歌似乎已经有了Transformer级别的重大突破。

最强「Transformer」出世
几天前的NeurIPS大会上,谷歌首席科学家Jeff Dean和AI教*父Hinton同框。关于LLM和研究路线,Hinton当场提出了一个尖锐的问题:谷歌是否后悔发表Transformer论文?Jeff Dean给出了干脆的回应:「不后悔!这项研究对世界产生了重大影响」。

几乎同一时间,谷歌放出了全新的架构Titans,成为Transformer的最强继任者。此外,还有全新的MIRAS框架。两者的结合,可以让AI模型在运行过程中动态更新核心记忆,跑得更快,也能处理超长规模的上下文。


众所周知,Transformer最大的瓶颈在于,上下文无限扩展会导致计算成本飙升。除了业界迭代的RNN、Mamba-2等架构,谷歌也提出了新一代解决方案——Titans+MIRAS,就是一套把RNN速度和Transformer准确性结合起来的架构与理论思路。
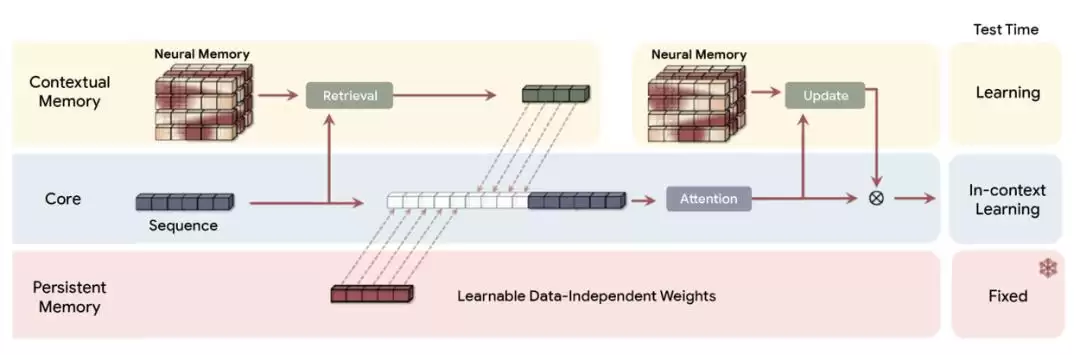
Titans(MAC)架构通过一个长时记忆模块来压缩历史数据,并将生成的摘要加入当前上下文,再交由注意力机制处理。Titans是具体的模型架构,而MIRAS是用于泛化这些方法的理论框架。它们合起来,实现了一种「测试时」记忆的能力。在运行时,模型不再只是把信息压成一段静态状态,而是在数据不断输入时主动学习,即时更新自己的参数。这个关键机制,可以让模型立刻把新的、具体的信息加入到核心知识里。
值得一提的是,清华姚班校友钟沛林参与了两项工作。他博士毕业于哥伦比亚大学,2021年起加入谷歌任研究科学家。
Titans:即时掌握新上下文
一个高效的学习系统,需要既独立又互相关联的「记忆模块」。这一机制,就像人脑会将短期记忆和长期记忆区分开来一样。
为此,Titans引入了一种全新的神经长期记忆模块,本质上是一个深层神经网络(一个多层感知机MLP)。它拥有更强的表达能力,在不丢失关键信息的同时,总结海量内容。有了Titans,LLM不只是记笔记,而是在真正理解并串联整个故事。

更重要的是,Titans并非被动存储数据,而是主动学习如何识别并保留贯穿整个输入的重要关系和概念主题。衡量这一能力的核心指标之一,谷歌将其称之为「惊奇度」。如果遇到「高惊奇」度的信息,会被优先写入长期记忆。而且,模型会随着不断学习,自适应管理权重,主动遗忘不再需要的信息。
MIRAS:统一视角,序列建模
序列建模的每一次重大突破,本质上都在使用同一种底层机制:高度复杂的联想记忆模块。MIRAS的独到之处和实用价值在于,它把各种架构视为解决同一个核心问题——如何在融合新信息与旧记忆的同时,不让关键概念被遗忘——的「不同手段」。

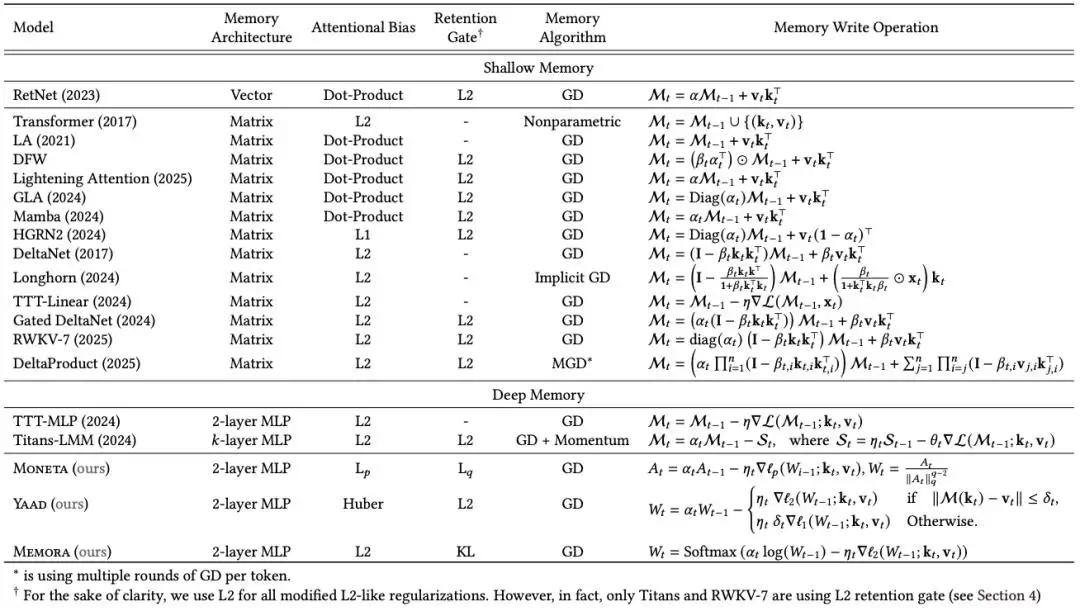
MIRAS通过四个关键设计维度来定义序列模型:
记忆架构:承担信息存储的结构,例如向量、矩阵,或像Titans那样的深层多层感知机。
注意偏置:模型内部优化的学习目标,决定优先关注哪些信息。
保留门:一种记忆正则化机制。MIRAS将传统「遗忘机制」重新解释为正则化形式,用于在学习新知识与保留旧知识之间取得平衡。
记忆算法:用于更新记忆状态的优化算法。
超越注意力
几乎所有现行成功的序列模型,在处理偏置和保留机制时,都依赖于均方误差(MSE)或点积相似度。这种依赖导致模型对异常值过于敏感,并限制了其表达能力。MIRAS突破了这一局限。借鉴优化理论与统计学文献,它构建了一个生成式框架,开拓了更丰富的设计空间。
基于MIRAS,谷歌构建了三款独特的无注意力模型:YAAD、MONETA、MEMORA。在语言建模和常识推理任务中,Titans架构在同等规模下,优于最先进的线性循环模型(如Mamba-2和Gated DeltaNet)以及Transformer++基线模型。
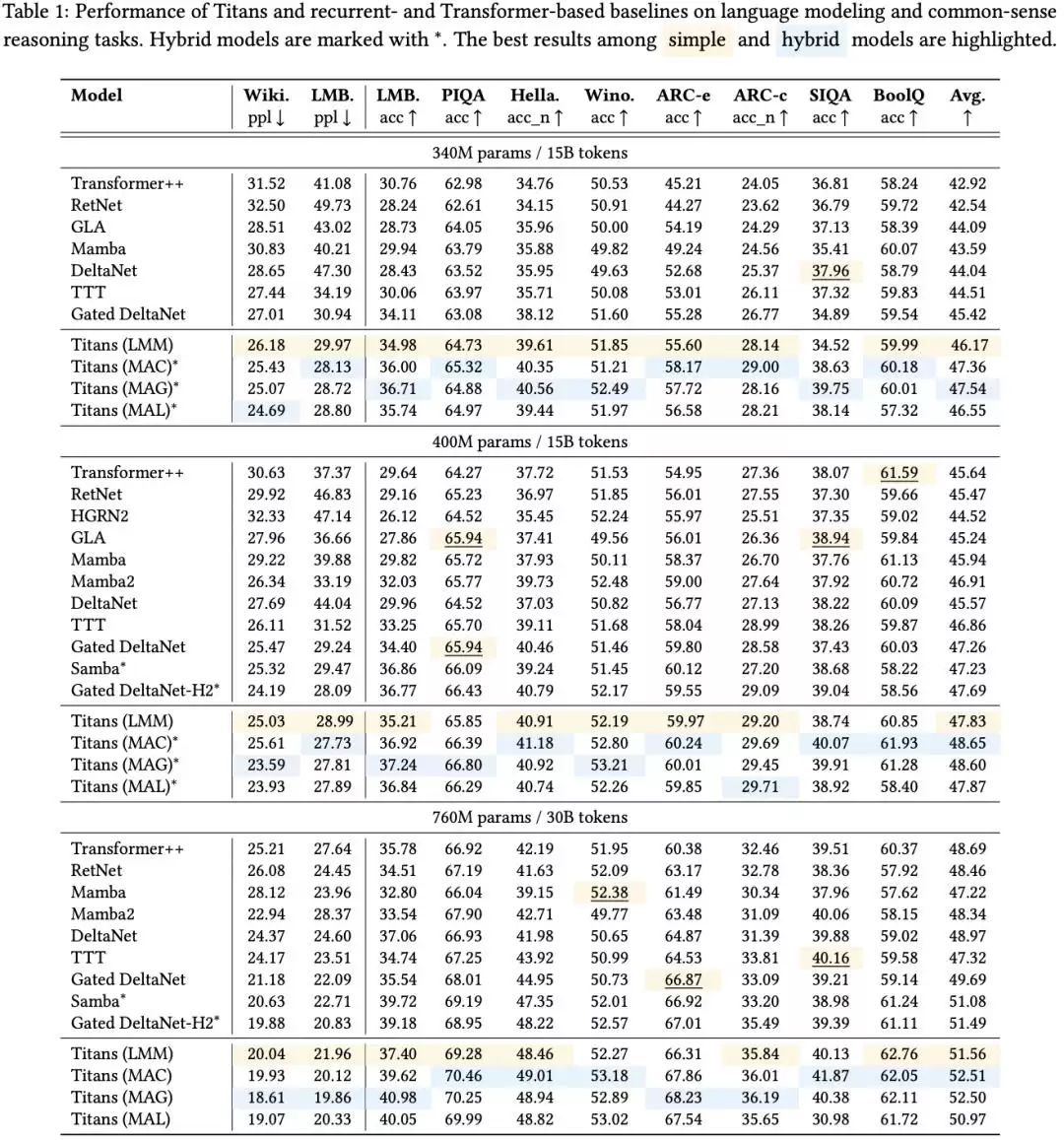
新颖的MIRAS变体(MONETA、YAAD、MEMORA)相比这些基线模型也提升了性能,验证了探索稳健的非MSE优化机制的优势。重要的是,这些模型保持了高效的并行化训练和快速的线性推理速度。
这些新架构最显著的优势在于其处理超长上下文的能力。这在BABILong基准测试中得到突出体现——该任务需要对分布在超长文档中的事实进行推理。在BABILong基准上,Titans以更少的参数量,表现优于包括GPT-4在内的所有基线模型。Titans进一步展示了可有效扩展到超过200万token上下文窗口的能力。
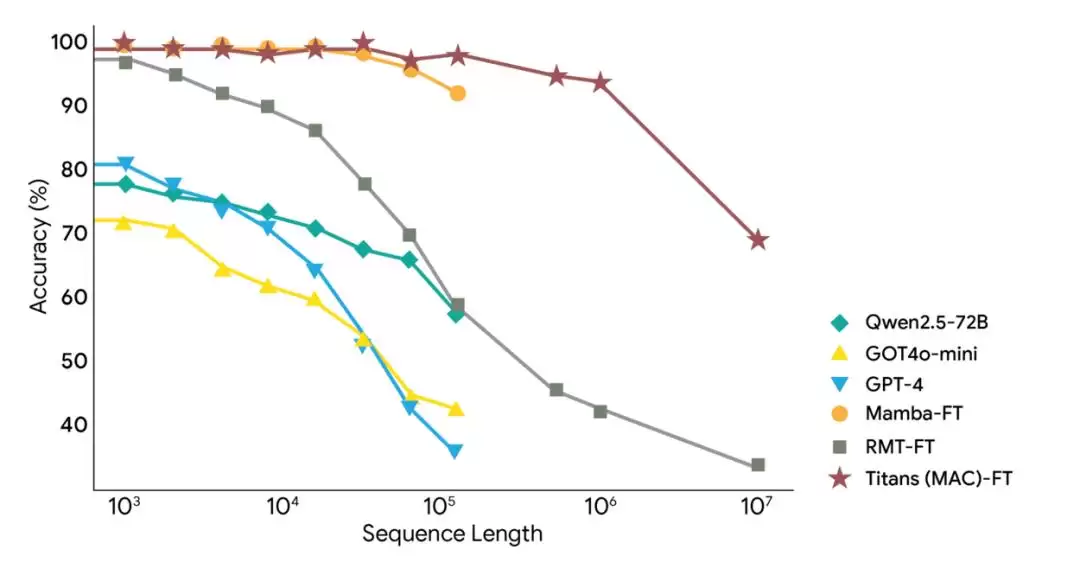
有Reddit网友预测,或许我们明天就能看到采用Titans架构的Gemini 4。正如网友所言,这可能是谷歌继Transformer之后,首个重大突破。

在架构层面,Titans+MIRAS补上了「记忆与持续学习」这一环。在多模态能力层面,Gemini显露出「元认知」的边缘形态。也许,AGI正加速到来。




