科学研究的基本范式正在被大模型悄然重塑。过去数年间,人工智能虽然在多个专业科学领域取得显著进展,却始终面临一个现实困境:绝大多数AI模型都是“专才”,每更换一个分子类型或研究环节,就必须重新训练一套专用系统。这种各自为战的分散格局,如今终于迎来了一个潜在的颠覆者。
阿里 ATH-Token Foundry 与中国人民大学高瓴人工智能学院联合开发的 LOGOS——全称 Language Of Generative Objects in Science,正是针对这一痛点应运而生。这款被定义为“基于统一科学语法”的多领域基础模型,现已正式开源。在六大代表性科学任务上,LOGOS 凭借纯序列建模范式,以一致性的表现匹配甚至超越了各领域的专用方法。
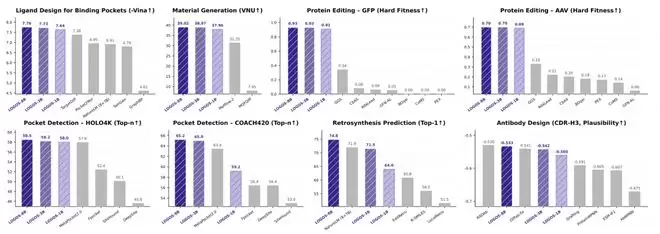
LOGOS 在六大任务中展现出令人惊讶的通才能力。这种“惊讶”主要源于其极低的参数量——仅 1B 参数的模型,就在多项任务上超越了拥有 8×7B 参数的微软 NatureLM。换言之,LOGOS 参数量仅为后者的 1/56,而性能却不相上下甚至更优。这种极高的参数效率,才是真正值得关注的硬指标。
那么,LOGOS 是如何实现这一突破的?
首先,在训练阶段,LOGOS 构建了一个庞大的多模态语料库,总计包含 44.87B token,涵盖7类模态:蛋白质(28.9B token)、抗体(3.0B token)、小分子(2.1B token)、化学反应与 MOF 材料(0.47B token)、蛋白质口袋(5.8B token)以及蛋白口袋-配体复合物(4.6B token)。这意味着模型在预训练过程中同时“阅读”了生物学、化学和材料科学三大领域的核心语言。
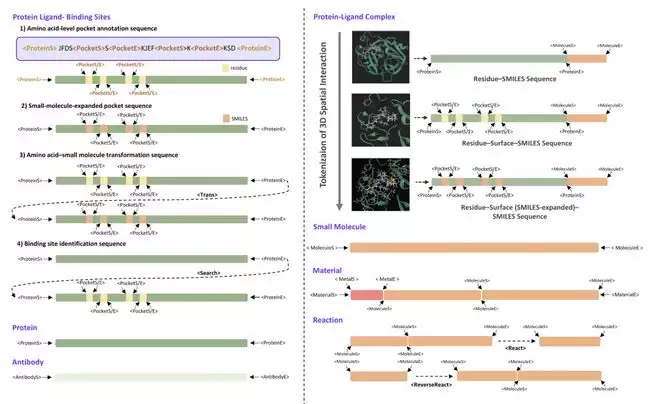
然而,数据量大仅是其中一个方面。最关键的设计在于,LOGOS 建立了一套共享词表——将蛋白质序列、小分子 SMILES 结构、材料晶体参数等原本互不兼容的异构对象,全部转化为统一的离散 Token 序列。这种方案的核心优势在于,所有科学对象都能在同一个生成空间中,通过大模型以自回归方式进行理解和生成。从本质上讲,它们不再使用各自领域的“行话”,而是采用同一种“科学语法”。
更精妙的是对3D空间相互作用的处理。传统方法需要模型理解蛋白质与小分子的结合方式,必须依赖显式的3D坐标和复杂的几何神经网络。而 LOGOS 独创了一种“文字描述法”——将3D空间的接触模式直接“语法化”为离散 Token,模型完全无需输入3D坐标。它仅需“阅读文字”(即进行序列预测),就能在内部构建出复杂的3D互作规律。这好比用自然语言描述一幅立体画,不需要具备立体视觉,描述本身就已隐含了空间结构。
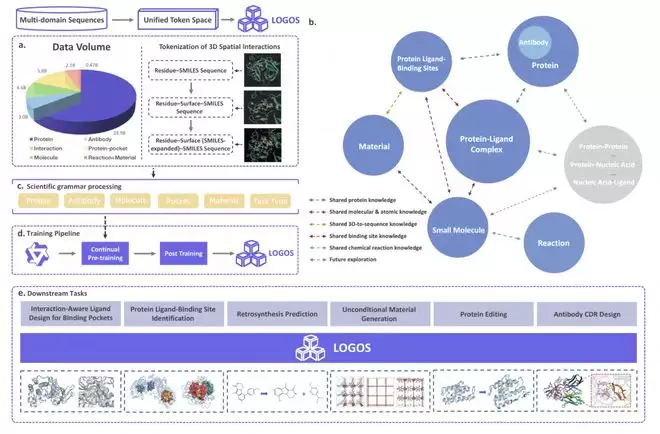
传统科学AI存在两个难以回避的障碍:一是“专病专药”——从结构预测切换到分子生成等不同研究环节,必须更换模型和假设;二是“学用脱节”——预训练目标与实际应用之间存在巨大鸿沟,模型落地时往往需要大量微调。LOGOS 的科学语法设计恰好同时攻克了这两大难题。
在形式上,预训练数据采用的序列形式与下游任务的输入输出形式完全一致;在目标上,预训练阶段的 next-token prediction 任务与下游的条件生成任务实现了完全对齐。这种 form-objective alignment 意味着,模型在预训练过程中所学到的知识可以直接应用于下游任务,两者之间的差距几乎被消除,复杂的适配层或大量微调因此变得不再必要。
统一语法带来的另一个深层优势是知识共享。举一个直观的例子:当模型看到蛋白质的“方言”(例如某个氨基酸口袋序列)时,可以直接“翻译”出对应小分子的“方言”(即 SMILES 结构)。这证明模型并非机械地对比表面特征,而是在底层真正学会了两类科学对象之间的对应关系。它掌握了“翻译”能力,而不仅仅是死记硬背。
目前,LOGOS 的模型权重、推理代码以及技术报告已全部开源,可通过 HuggingFace、GitHub 或 arXiv 论文获取完整资料。如果你正在思考如何将大模型科学化落地,这个开源项目非常值得深入研究。




