近年来,如果说大语言模型赋予了机器理解语言的强大能力,智能体为其提供了自主行动的框架,那么世界模型,则是让整个系统学会在真实环境中进行思考与模拟的关键环节。这三者的深度融合,已经成为人工智能领域最前沿、最受关注的研究方向之一。
如何理解这一组合?简单来说,LLM提供了卓越的语言理解与推理能力,世界模型负责对环境进行精准模拟与状态预测,而Agent则将这些能力整合为一个能够自主决策、执行任务的完整智能体。为了清晰展示它们如何协同运作,下面将通过三个具体的实战案例,配合可运行的代码,进行逐步深入拆解。
核心概念速览
在深入案例之前,我们先快速梳理一下这三个核心概念的基础定义,这样后续理解会更加清晰:
| 概念 | 核心能力 | 类比 |
|---|---|---|
| LLM(大语言模型) | 语言理解、生成、推理、知识记忆 | 大脑的「语言皮层」 |
| 世界模型(World Model) | 环境建模、状态预测、因果推理 | 大脑的「想象与模拟系统」 |
| Agent(智能体) | 感知→规划→行动→反馈循环 | 完整的「自主个体」 |
三者的协作关系可以这样理解:大语言模型充当智能体的推理核心,世界模型作为智能体的内部模拟环境,而智能体本身,则是负责感知、规划并最终执行任务的行动主体。
案例一:基于LLM+世界模型的游戏Agent
场景描述
想象一个经典的网格世界(Grid World)。一个智能体需要在迷宫中找到路径,并收集目标物品。传统的强化学习需要依靠大量试错才能学会。但如果给它配备LLM和世界模型,情况就大为不同——它不仅能够通过语言指令理解任务,还能利用世界模型在脑海中先进行路径“推演”,做到心中有数再行动。
架构设计
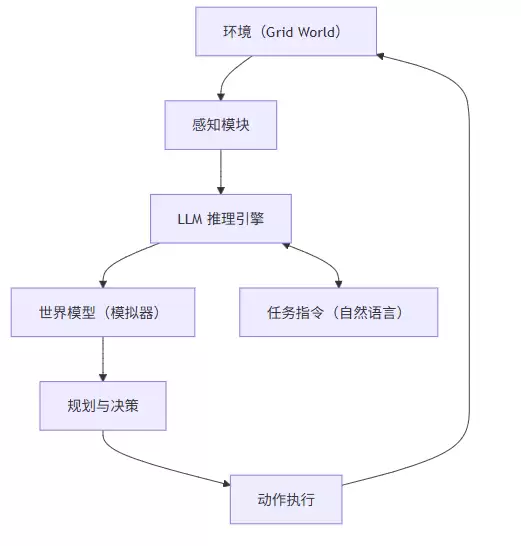
代码实现
import numpy as np
from typing import List, Tuple, Optional
# ---------- 1. 网格世界环境 ----------
class GridWorld:
"""简单的网格世界环境"""
def __init__(self, size: int = 5):
self.size = size
self.agent_pos = (0, 0)
self.target_pos = (size - 1, size - 1)
self.obstacles = {(1, 1), (2, 2), (3, 1)} # 障碍物位置
def get_state(self) -> dict:
"""返回当前状态描述"""
return {"agent": self.agent_pos, "target": self.target_pos, "obstacles": list(self.obstacles), "grid_size": self.size}
def step(self, action: str) -> Tuple[dict, float, bool]:
"""执行动作,返回新状态、奖励、是否完成"""
x, y = self.agent_pos
if action == "up" and x > 0: x -= 1
elif action == "down" and x < self.size - 1: x += 1
elif action == "left" and y > 0: y -= 1
elif action == "right" and y < self.size - 1: y += 1
new_pos = (x, y)
if new_pos in self.obstacles: reward = -1.0
else: self.agent_pos = new_pos; reward = 1.0 if new_pos == self.target_pos else -0.1
done = (self.agent_pos == self.target_pos)
return self.get_state(), reward, done
def reset(self):
self.agent_pos = (0, 0)
return self.get_state()
# ---------- 2. 世界模型(轻量级模拟器) ----------
class WorldModel:
"""基于经验的世界模型,用于模拟环境动态"""
def __init__(self):
self.transition_memory = {} # (state_key, action) -> next_state_key
def update(self, state: dict, action: str, next_state: dict):
"""从真实交互中学习环境动态"""
state_key = self._state_to_key(state)
next_key = self._state_to_key(next_state)
self.transition_memory[(state_key, action)] = next_key
def predict(self, state: dict, action: str) -> Optional[dict]:
"""预测在给定状态下执行动作后的结果"""
state_key = self._state_to_key(state)
next_key = self.transition_memory.get((state_key, action))
if next_key is None: return None
x, y = map(int, next_key.split(","))
return {"agent": (x, y), "target": state["target"], "obstacles": state["obstacles"], "grid_size": state["grid_size"]}
def simulate_rollout(self, state: dict, plan: List[str]) -> List[dict]:
"""模拟执行一系列动作,返回预测的状态序列"""
trajectory = [state]
current = state
for action in plan:
next_state = self.predict(current, action)
if next_state is None: break
trajectory.append(next_state)
current = next_state
return trajectory
def _state_to_key(self, state: dict) -> str:
return f"{state['agent'][0]},{state['agent'][1]}"
# ---------- 3. LLM 驱动的 Agent ----------
class LLMAgent:
"""使用 LLM 推理 + 世界模型规划的 Agent"""
def __init__(self, world_model: WorldModel, llm=None):
self.world_model = world_model
self.llm = llm
def _build_prompt(self, state: dict, task: str) -> str:
return f"""你是一个在网格世界中导航的智能体。
当前状态:
- 你的位置: {state['agent']}
- 目标位置: {state['target']}
- 障碍物: {state['obstacles']}
- 网格大小: {state['grid_size']}x{state['grid_size']}
任务: {task}
请分析当前情况,并给出下一步行动计划(最多3步),格式为动作列表:
动作可选: up, down, left, right
输出格式: ["动作1", "动作2", ...]"""
def plan(self, state: dict, task: str = "到达目标位置") -> List[str]:
"""使用 LLM 生成计划,并用世界模型验证"""
prompt = self._build_prompt(state, task)
# 实际使用时,这里应该调用真实的LLM API
plan = self._simulate_llm_plan(state)
print(f"[LLM] 生成计划: {plan}")
simulated = self.world_model.simulate_rollout(state, plan)
if len(simulated) >= len(plan) + 1:
print(f"[世界模型] 计划验证通过,预计 {len(simulated)-1} 步后到达 {simulated[-1]['agent']}")
else:
print(f"[世界模型] 计划验证失败,存在未知状态")
plan = self._safe_fallback(state)
return plan
def _simulate_llm_plan(self, state: dict) -> List[str]:
"""模拟 LLM 规划(实际应调用真实 LLM)"""
ax, ay = state["agent"]
tx, ty = state["target"]
plan = []
while ax < tx and len(plan) < 3: plan.append("down"); ax += 1
while ax > tx and len(plan) < 3: plan.append("up"); ax -= 1
while ay < ty and len(plan) < 3: plan.append("right"); ay += 1
while ay > ty and len(plan) < 3: plan.append("left"); ay -= 1
return plan[:3]
def _safe_fallback(self, state: dict) -> List[str]:
return ["up", "right", "down"]
# ---------- 4. 运行演示 ----------
def run_demo():
env = GridWorld(size=5)
world_model = WorldModel()
agent = LLMAgent(world_model)
state = env.reset()
print(f"初始状态: Agent={state['agent']}, Target={state['target']}")
total_reward = 0
for episode in range(3):
print(f"--- 第 {episode + 1} 轮 ---")
plan = agent.plan(state, "到达目标位置")
for action in plan:
next_state, reward, done = env.step(action)
world_model.update(state, action, next_state)
total_reward += reward
print(f"执行 {action}: 到达 {next_state['agent']}, 奖励={reward:.1f}")
state = next_state
if done:
print(f"



