一、TL;DR
AI coding agent 默认以最快速度到达「完成」,跳过写 spec、先写测试、上线检查这些在 diff 里看不见的工作。Addy Osmani 把 Google 二十年的工程实践蒸馏成 agent-skills——20 个结构化 Skill,加上一个负责任务路由的 Meta Skill,把高级工程师的判断力编码成 agent 无法绕过的工作流。
值得注意的是,这套工程实践本身并不只属于 AI——写 spec、显式化假设、验收标准可量化、反合理化,对人类工程师同样适用,放进团队 wiki 照样有效。而 Addy 设计 Skill 的方式——触发条件、阶段检查点、边界三分法、反合理化内置——也是一套可以直接借鉴的方法论,无论你是在为 AI agent 还是为团队编写自己的 Skill。
二、什么是 Skill
在深入 agent-skills 之前,先问一个关键问题:Skill 到底是什么?
Addy 的定义很精准:一个 Skill 是注入 agent 上下文的 Markdown 文件,但它不是参考文档——它是一个带检查点和退出条件的工作流。每个步骤都有明确的执行指令,每个阶段都有人类审核节点,任务完成的标准是「有证据」,而不是「看起来对了」。
这个区别很关键。普通的参考文档,agent 会读一遍,生成看起来合理的输出,然后跳过实际要做的事。Skill 的结构让这条捷径消失——没有完成检查点,就不能进入下一步。
可以把它理解为介于 system prompt 片段和 runbook 之间的东西:比 system prompt 更结构化,比 runbook 更高层——不是机械执行步骤,而是带判断点的工作流。
三、蒸馏与编码:Google 工程基因如何变成可执行的 Skill
agent-skills 里的工程实践,不是 Addy 发明的。翻开 Google 出版的《Software Engineering at Google》,几乎可以找到每一条实践的出处:
| 实践 | 对应 Skill | SWE Book 章节 |
|---|---|---|
| Hyrum 定律 | api-and-interface-design | Ch01 — What Is Software Engineering? |
| 左移 | ci-cd-and-automation | Ch01 — What Is Software Engineering? |
| 切斯特顿之栅 | code-simplification | Ch03 — Knowledge Sharing |
| 代码评审 | code-review-and-quality | Ch09 — Code Review |
| 测试金字塔 / Beyoncé Rule | test-driven-development | Ch11 — Testing Overview |
| DAMP > DRY | test-driven-development | Ch12 — Unit Testing |
| 主干开发 | git-workflow-and-versioning | Ch16 — Version Control and Branch Management |
| 代码是负债 | deprecation-and-migration | Ch15 — Deprecation |
这正是「蒸馏」二字的含义——把 Google 工程师二十年积累的实践,提炼成 agent 可以直接执行的指令。
但问题就在于,光有正确的内容还不够。如果只是把它们写进一份文档,agent 读一遍,生成看起来合理的输出,然后照样跳过实际要做的事。真正的挑战是「编码」:把这些实践转化成 agent 无法绕过的结构。这是 Addy 自己摸索出来的 Skill 设计准则,在 SWE Book 里找不到对应:
- 触发条件明确。 每个 Skill 最前面都是「何时用 / 何时不用」。spec-driven-development 明确写道:单行修改、typo、无歧义的独立改动,直接跳过。防止 agent 无脑套用。
- 阶段检查点,人类不可绕过。 spec-driven-development 的四阶段工作流——SPECIFY → PLAN → TASKS → IMPLEMENT——每个阶段结束都有「Human reviews」检查点,明确标注:「未经人类验证,不得进入下一阶段。」
- 假设显式化。 每个 Skill 的第一步不是写代码,而是列出假设清单,格式固定:
ASSUMPTIONS I'M MAKING: 1. [关于需求的假设] 2. [关于架构的假设] → Correct me now or I'll proceed with these. - 验收标准可量化。 模糊目标必须转化为可测试的标准。「更快」不够,要写成「LCP < 2.5s」。code-review-and-quality 里同样要求:「量化问题,不要模糊表述——‘这个 N+1 查询会增加约 50ms 延迟’,而不是’这可能会慢一点‘。」
- 边界三分法。 每个 Skill 都定义了三条边界:Always(直接做)、Ask First(先问)、Never(禁止)。agent 遇到决策点,直接查表,不需要猜测。
- 反合理化内置。 提前把 agent 会找的借口写进 Skill,附上反驳。这个设计下一章单独讲。
- Spec 是活文档。 不是冻结的需求文档,而是随代码一起提交、在 PR 里引用、随实现持续更新的活文档。
四、Meta Skill:整个体系的操作系统
20 个 Skill 摆在那里,问题来了:什么时候用哪个?
如果在会话开始时把所有 Skill 全部加载进 context,本身就是反模式。Addy 说得很直接:「每个加载的 token 都会降低性能,不需要的留在磁盘上。」
这就是 using-agent-skills 存在的原因——整个体系的操作系统,负责在正确的时机激活正确的 Skill。
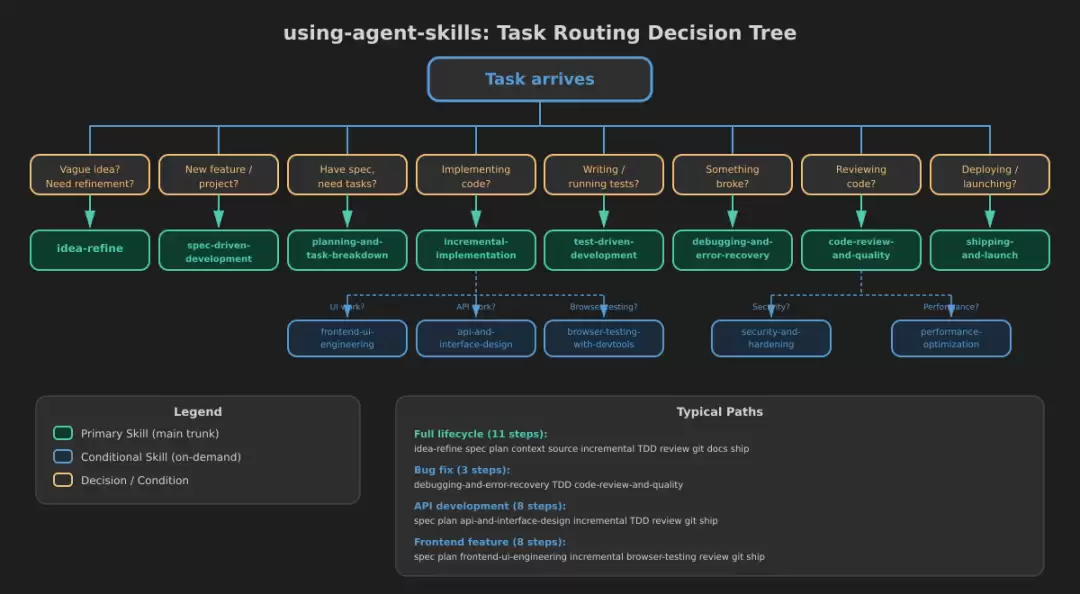
决策树:任务进来,先路由
任务到来时,meta skill 用一棵决策树做路由:
主干与按需加载:两层结构
仔细看这棵树,20 个 Skill 实际上分成两层:
11 个构成主干,覆盖一次完整功能开发的全生命周期:idea-refine → spec-driven-development → planning-and-task-breakdown → context-engineering → source-driven-development → incremental-implementation → test-driven-development → code-review-and-quality → git-workflow-and-versioning → documentation-and-adrs → shipping-and-launch
另外 9 个是条件加载,只在特定场景下激活,可以分为四类:
| 类型 | Skill |
|---|---|
| 领域专家型(特定技术栈) | frontend-ui-engineering、api-and-interface-design |
| 异常处理型(出问题才用) | debugging-and-error-recovery、browser-testing-with-devtools |
| 深化审查型(review 增强) | code-simplification、security-and-hardening、performance-optimization |
| 生命周期边缘型(跨迭代决策) | ci-cd-and-automation、deprecation-and-migration |
典型路径
不同任务类型,走不同的路径:
| 场景 | 路径 | 步骤数 |
|---|---|---|
| 完整功能开发 | idea-refine → ... → shipping-and-launch | 11 步 |
| Bug 修复 | debugging-and-error-recovery → TDD → code-review | 3 步 |
| API 开发 | spec → plan → api-and-interface-design → incremental → TDD → review → git → ship | 8 步 |
| 前端功能 | spec → plan → frontend-ui-engineering → incremental → browser-testing → review → git → ship | 8 步 |
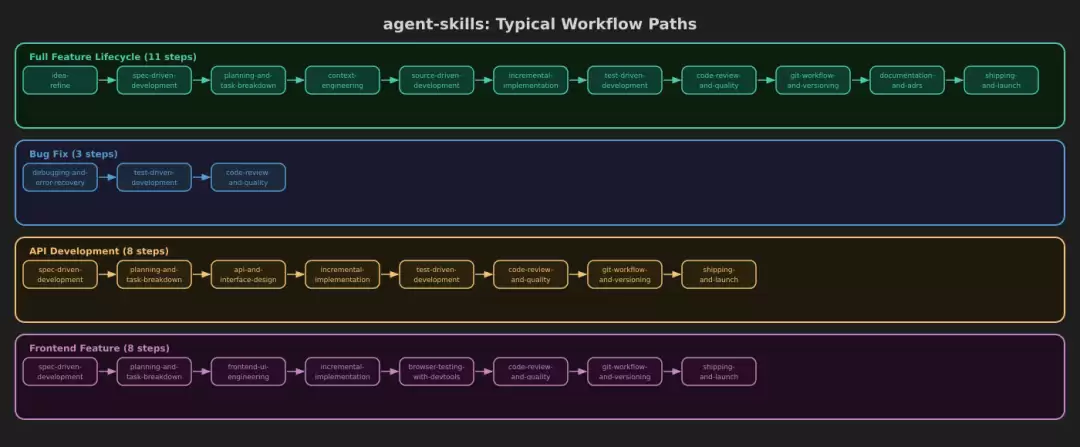
最长 11 步,最短 3 步。meta skill 的价值正在于此——根据任务类型,从主干上裁剪出合适的路径,而不是每次都走完整流程。
六条不可违背的行为规范
路由之外,meta skill 还定义了 agent 的底层操作原则——六条无论执行哪个 Skill 都必须遵守的行为规范:
- 显式化假设。 开始任何任务前,先列出假设清单:
ASSUMPTIONS I"M MAKING: 1. [关于需求的假设] 2. [关于架构的假设] → Correct me now or I'll proceed with these.「最常见的失败模式,是带着错误假设一路往前走。」 - 主动管理困惑。 遇到不确定,停下来,明确说出具体的困惑,等待解答。不猜测,不绕过。
- 该反驳就反驳。 发现问题,直接指出,量化影响——「这会增加约 200ms 延迟」,而不是「这可能会慢一点」。提出替代方案,接受人类的最终决定。
- 强制简洁。 完成前问自己:能用更少的行数实现吗?抽象是否值得其复杂度?有经验的工程师会不会说「为什么不直接……」?
- 范围纪律。 只动被要求动的地方。不重构相邻系统,不删除没完全理解的代码,不因为「看起来有用」就添加未被要求的功能。
- 验证才算完成。 有通过的测试、有构建输出、有运行时数据——才算完成。
10 个失败模式
meta skill 还附了一份负面清单,把 agent 最常踩的坑提前列出来:
前五条,都是「不该走时往前走」:
- 没确认就带着错误假设前进
- 遇到困惑继续硬推
- 发现不一致却不说
- 非显式决策不体现权衡
- 对糟糕方案随声附和
后五条,都是「做了不该做的事」:
- 把代码和 API 过度复杂化
- 改动了与任务无关的代码
- 删除了没完全理解的东西
- 没有 spec 就开始实现「显而易见」的需求
- 「看起来对了」就收工,跳过验证
两类失败,一个根源:agent 在优化「快速完成」,而不是「正确完成」。meta skill 做的,就是把这条捷径逐一堵死。
五、反合理化:预先封堵借口
agent-skills 里最有创意的设计,不是那 20 个 Skill,而是每个 Skill 里都内置的一张表——反合理化表格(Anti-Rationalization)。
设计思路很反直觉:与其告诉 agent 应该做什么,不如把它会找的借口提前写下来,附上反驳,让这些借口在说出口之前就被堵死。
回到引子里的那两个场景:
场景 A:跳过 spec
agent 最常用的借口是「spec 会拖慢进度」。spec-driven-development 的反驳是:
场景 B:跳过测试
test-driven-development 里写得更直接:
| 借口 | 反驳 |
|---|---|
| “I’ll write tests after” | You won’t. Post-hoc tests test implementation, not beha vior. |
| “Too simple to test” | Simple code gets complicated; test documents expected beha vior. |
| “Tests slow me down” | Now yes. Every future change: no. |
| “It’s just a prototype” | Prototypes become production. |
「等会再写」是整个表格里最有力的一条。「等会」这个词承载了太多从未兑现的承诺——就像我们常说的「有时间一起吃个饭」,说的时候是真心的,但都知道不会发生。不只是 agent,人类工程师也一样。把它写进 Skill,是对所有人的约束。
这个设计模式本身也值得借鉴——不只用于 agent。Addy 在博客里提到,可以把反合理化当成团队实践:把你们团队经常对自己说的谎话列出来,加上反驳,放进 wiki。适用范围远不止 AI 编程。
六、收尾
回头看引子里那个 agent——它不是不够聪明,它只是在忠实地执行自己的默认目标:以最快速度到达「完成」。
没有人告诉它,「完成」不等于「正确完成」。
agent-skills 做的,就是把这个差距填上——用 Addy 二十年在 Google 积累的工程判断力,用 SWE Book 里那些经过大规模验证的实践,把它们编码成 agent 无法绕过的结构性约束。
不是参考文档,不是建议,是工作流。
模型会越来越强,但判断力不会自动涌现。在它真正拥有之前,我们能做的,是把我们的判断力写下来。
代码是廉价的。判断力不是。agent-skills 做的,是让前者不再替代后者。
参考资料
[1] Addy Osmani: https://addyosmani.com
[2] agent-skills: https://github.com/addyosmani/agent-skills
[3] Software Engineering at Google: https://abseil.io/resources/swe-book
[4] Hyrum 定律: https://abseil.io/resources/swe-book/html/ch01.html#hyrumapostrophes_law
[5] 左移: https://abseil.io/resources/swe-book/html/ch01.html#shifting_left
[6] 切斯特顿之栅: https://abseil.io/resources/swe-book/html/ch03.html#understand_context
[7] 代码评审: https://abseil.io/resources/swe-book/html/ch09.html
[8] 测试金字塔 / Beyoncé Rule: https://abseil.io/resources/swe-book/html/ch11.html
[9] DAMP > DRY: https://abseil.io/resources/swe-book/html/ch12.html
[10] 主干开发: https://abseil.io/resources/swe-book/html/ch16.html
[11] 代码是负债: https://abseil.io/resources/swe-book/html/ch15.html
[12] 触发条件明确: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#when-to-use--not-use
[13] 阶段检查点,人类不可绕过: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#the-gated-workflow-4-phases
[14] 假设显式化: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#surface-assumptions-first
[15] 验收标准可量化: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#reframe-vague-requirements-as-testable-criteria
[16] 边界三分法: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#six-core-areas-of-a-spec
[17] 反合理化内置: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#common-rationalizations-vs-reality
[18] Spec 是活文档: https://github.com/addyosmani/agent-skills/tree/main/skills/spec-driven-development#keeping-the-spec-alive
[19] using-agent-skills: https://github.com/addyosmani/agent-skills/tree/main/skills/using-agent-skills




