今天我们来深入探讨一个从“纯文本”阶段演进到“拓扑协议”的实战落地案例。简单来说,Mermaid 拓扑协议的“双轨制”(人类友好版 + AI 协议版)已经全面部署在后端和前端的各5张流程图中。配套文件包括 .md 人类版、.ai.md AI协议版,以及一个 validate_mermaid.py 验证脚本。与此同时,i18n 跨语言召回 v1 方案也顺利通过验收——中文查询词已能正确召回英文候选,术语表覆盖了42条关键映射,pytest 测试的32个用例全部通过。
换言之,技术图谱已经完成了从“纯文本描述”到“Mermaid 流程图”,再到“拓扑协议结构化”的三阶段跃迁。下面详细拆解其中的关键决策与避坑要点。
1) 今日核心目标
- [x] Mermaid 拓扑协议从概念落地为可执行规范(双轨制 + 验证脚本)
- [x] 后端5张流程图全部完成
.ai.mdAI协议版重写 - [x] 前端5张流程图同步完成
.ai.md与.cursorrules更新 - [x] i18n 跨语言召回 v1 任务验收(术语表 + query-side OR 扩展 + 可观测性)
2) 关键产出 / 决策
决策 1:Mermaid 双轨制(人类版 + AI 协议版)
为什么要维护两套版本?原因很现实:LLM 在生成 Mermaid 时如果只用裸边(A --> B),幻觉率会显著提高;但人类读者看到加了引号的边(A --"-->"--> B),视觉负担又过重。两全之策就是采用双轨设计。
具体而言:
.md版本 = 人类友好版:采用简洁标签,允许裸边,锚点写于节点内部。.ai.md版本 = AI 协议版:使用结构化标记(~>代表异步、?>代表条件、[ok]/[err]代表状态、::xxx代表元关系)。核心约束是零裸边,锚点被分离为// → path#Ln格式。
这一决策带来的影响不可小觑:
- 后端:
docs/_tech_graph/目录下的5张 flowchart 需要双轨化,同时需编写99_mermaid_protocol.md规范文档。 - 前端:同样对5张流程图进行双轨化,并在
.cursorrules中引用总规范。 - 验证:
scripts/validate_mermaid.py必须支持前后端通用的扩展名。
决策 2:拓扑协议边标记语义
为了让 AI 协议版具备清晰的行为指引,我们给边标记赋予了明确的语义:
| 标记 | 语义 | 示例 |
|---|---|---|
| -> | 同步执行 | process() → save() |
| ~> | 异步(await) | await embed_text() |
| => | 映射/赋值 | result = transform(data) |
| ?> | 条件分支 | if not valid: / try/except |
| [ok] | 成功路径 | validate() --"[ok]"--> save() |
| [err] | 错误路径 | parse() --"[err]"--> fallback() |
| ::yields | 流式产出 | LLM --"::yields"--> sources |
| ::branches | 并行分支 | gather 多路 |
| ::merges | 结果归并 | fuse_hits_rrf() |
| ::archives | 日志归档 | OUT --"::archives"--> DB |
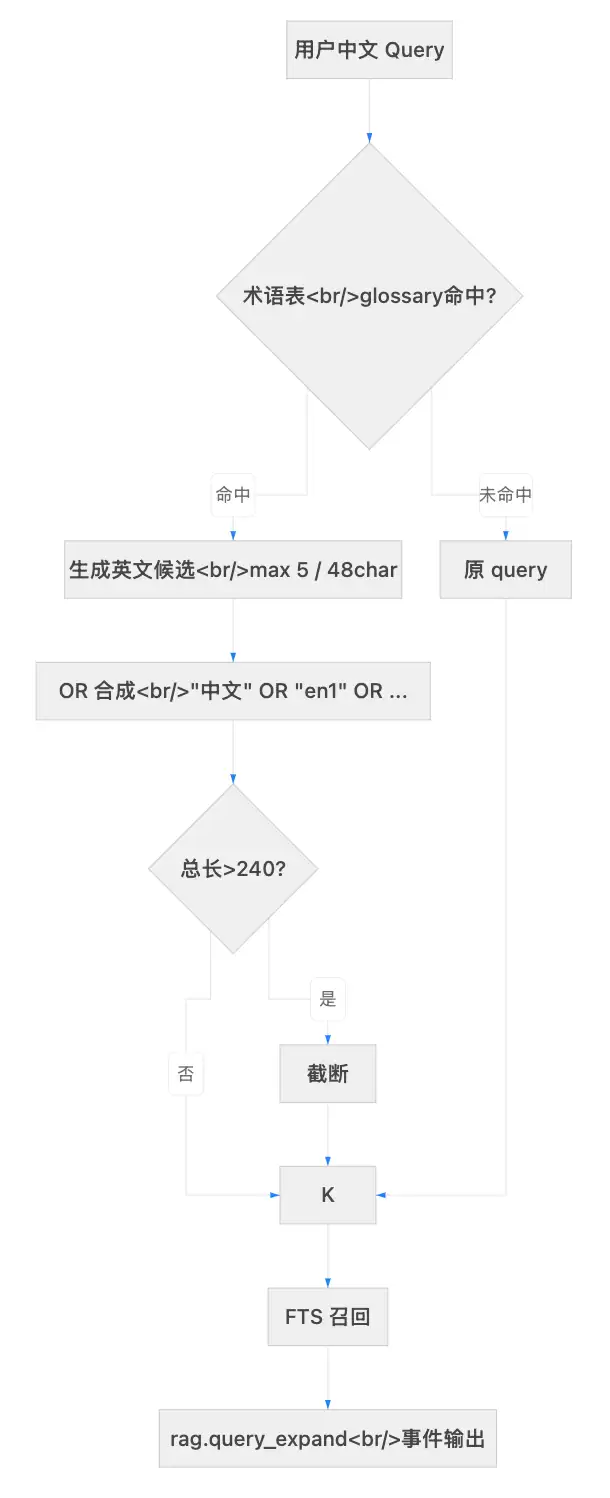
决策 3:i18n v1 最小可用方案
为何需要这个功能?典型场景是:中文用户搜索“消息历史”,但文档中只有 RunnableWithMessageHistory 这样的英文术语。结果自然是召回失败,用户只能干瞪眼。
我们的方案是一个最小可用版本:
- 维护一份术语表
data/i18n_glossary.json,目前收录了42条中文→英文候选映射。例如“消息历史”对应["message history"]。 - 采用 query-side OR 扩展策略:将原始 query 与候选以
OR合并,再送交keyword_documents(query_text)。 - 设置严格上限:候选数 ≤5,单候选 ≤48 字符,总 query 长度 ≤240 字符。
- 可观测性方面,通过
rag.query_expand事件输出扩展前后的对比情况。
验收结果:pytest 32 个用例全部通过,覆盖了候选生成、上限截断、异常兜底等场景。
3) 实现要点
3.1 拓扑协议验证脚本
# scripts/validate_mermaid.py
# 检查项:
# 1. 零裸边(无边标记的 -->)
# 2. 锚点格式 // → path#Ln
# 3. 异步节点 [[async def ...]] 必须用 ~> 边
3.2 i18n Query 扩展流程
flowchart LR
Q[中文 Query] --> G{术语表命中?}
G -->|命中| C[生成英文候选]
G -->|未命中| R[返回原 query]
C --> L{超限?}
L -->|是| T[截断]
L -->|否| O[OR 合成]
T --> O
O --> K[keyword_documents]
R --> K
3.3 双轨文件行数对比
| 图 | 人类版 | AI 版 | 膨胀率 |
|---|---|---|---|
| 00_main | 54 | 70 | + 29% |
| 10_flow_rag | 52 | 78 | + 50% |
| 11_text2sql | 45 | 63 | + 40% |
| 12_fts | 45 | 64 | + 42% |
| 13_rpc | 40 | 59 | + 47% |
4) 风险与坑位
在实际落地过程中,一些问题逐渐浮出水面:
- 锚点正则兼容问题:前端代码使用
.tsx .ts扩展名,但最初的验证脚本只支持.py .sql .md,后续已修复。 - 通配符路径:类似
app/**/page.tsx[...slug]的 glob 语法不符合标准锚点格式,作为合理例外予以保留。 - 人类版维护成本:双轨意味着修改代码需要同步更新两份图。缓解策略是:优先更新
.ai.md,.md按需同步。 - i18n 术语表运营:目前42条仅覆盖高频术语,长期需要建立回填机制——遇到未命中时人工补充,再回归验证。
5) 明日计划
- [ ] 验证拓扑协议在真实 LLM 生成场景中的幻觉降低效果(对比实验)
- [ ] i18n 术语表回填:从最近3天未命中的 query 中提取候选补充
工程图|i18n v1 Query-Side 扩展