Day6 学习日志:从架构细节到对齐
日期:2026-03-20
定位:在 Day5「参数量账本」的基础上,补全训练与推理阶段的关键机制及偏好对齐链路。
一、昨日回顾(Day5 要点)
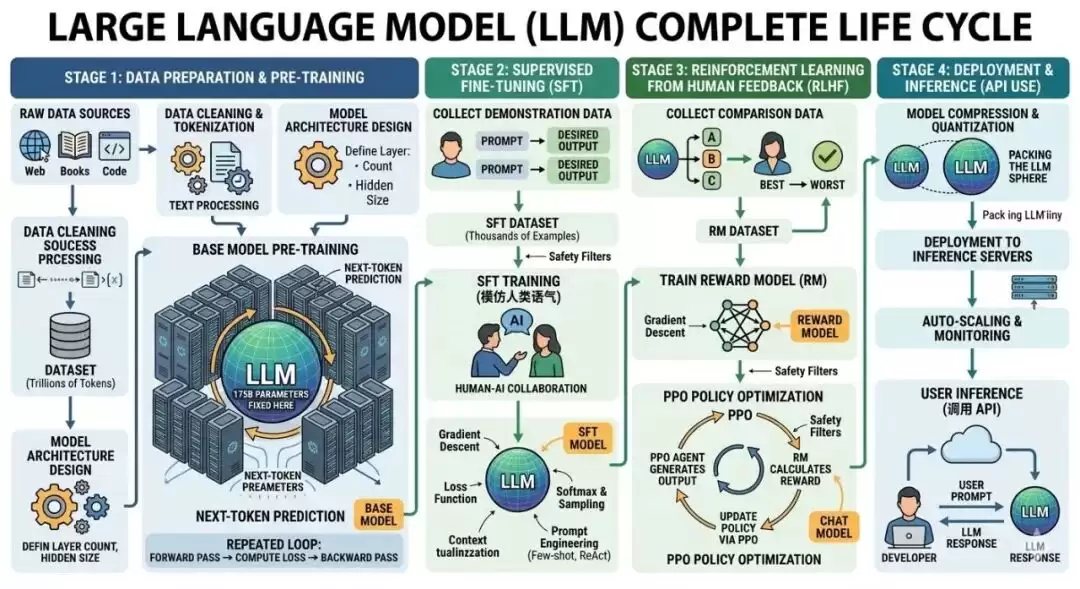
回顾第5天的内容,我们从矩阵维度清晰计算了GPT-3约175B参数的构成,核心要点包括:
| 要点 | 内容 |
|---|---|
| 配置 | 96层仅有解码器模块,96个注意力头 |
| 单层公式 | 参数量约:注意力部分约占1/3,前馈网络约占2/3(先4倍升维再降回原维度) |
| 总量级 | 单层参数约亿级,乘以96层再加上嵌入层共175B |
| 直觉 | 注意力机制负责“谁与谁相关”,前馈网络负责“记忆内容”;FP16精度下仅权重就约350GB |
| 顺带 | 点乘与缩放、Q/K维度对齐、预训练→有监督微调→偏好对齐的典型生命周期 |
基于这些认知,今天我们将深入更细粒度的工程机制——归一化、缩放策略、词表投影、采样方式,以及对齐后续环节(奖励模型、近端策略优化、直接偏好优化趋势)。
二、今日精读:架构里的「呼吸与温控」
1. Add & Norm:深层网络稳定训练的基石
残差连接(Add)相当于为梯度保留了一条“高速公路”——即便当前子层学习效果不佳,信号仍能直达后方,有效缓解深层梯度消失问题。层归一化(Layer Norm)则将激活值拉回到稳定尺度,避免连续乘积导致数值爆炸或崩塌,使训练过程更加稳健。这一配对常被比喻为Transformer模块的“呼吸与温控”:残差确保通路畅通,归一化维持数值秩序。
2. 缩放因子:Softmax 前的「贫富调节」
点积结果随着维度增大通常会整体偏大,导致Softmax输出极端尖锐(接近one-hot),梯度在少数位置上饱和,模型难以学到“多种合理的关注”。通过除以根号下维度后,点积的尺度被校准到与维度无关的量级,Softmax变得更加平滑,保留了可调空间,相比极端尖峰也更具“创造性”余地。
三、今日精读:模型如何「开口说话」
1. Linear Head:从隐向量到词表映射
模型最后一层输出的是高维语义向量,并非具体的汉字或token。词表投影矩阵(规模庞大,例如GPT-3中与50257个词类对齐)将该向量与全词表的“原型向量”进行匹配,输出每个词的未归一化分数(logits)。
2. 采样策略:同一组 logits,不同的“性格”
Top-K / Top-P 并非永远只选取argmax结果,而是在高分候选集合中再引入随机性,从而生成更丰富多样的文本。Temperature参数控制概率分布的平滑程度:温度越高,分布越平坦,低概率token更容易被采样,输出更发散且富有创意;温度越低,输出越接近“标准答案”。调用API时调整temperature、top_p,本质上就是在操纵这一层概率几何。
四、今日精读:从 SFT 到 PPO(再瞥一眼 DPO)
1. 奖励模型 RM:学会“打分”
在有监督微调模型的骨干上替换或增加头部,利用人类排序(例如回答A优于回答B)进行训练,使优质回答的得分显著高于劣质回答(拉大分数差距)。奖励模型本身不生成文本,仅为策略模型提供标量反馈信号。
2. PPO:带约束的策略更新
核心思路:策略模型(SFT后)在生成过程中“试探”,依据奖励模型的回报调整参数。若本次生成比基线更优,则强化该轨迹;反之则弱化。KL散度惩罚限制了新策略与参考模型(通常是SFT检查点)的偏差,避免为了刷高分而产出怪异、不安全或分布外的文本。PPO效果好但实现复杂、调参困难,工业界许多场景已转向直接偏好优化(DPO)等更简洁的对齐方法。
3. 工程师视角的一句话总结
模型本质上是在高维空间中重排概率分布;参数能稳定训练并能对齐才有实际价值。做应用时,注意力机制的缩放因子、KV缓存技术、上下文长度对延迟和账单的影响,往往比死记硬背公式更为紧迫。
明日预告
开启AI应用实战方向:RAG 架构 与 Function Calling 。




