一、存储正在成为AI基础设施的关键瓶颈
过去几年,企业在讨论AI基础设施时,话题几乎离不开GPU:采购哪款显卡、如何调度资源、利用率能达到多少。然而,当平台真正搭建并运行后,许多团队发现,最令人头疼的往往不是算力,而是存储。
原因并不复杂——AI负载对存储的要求与传统企业应用完全是两套不同的逻辑。训练阶段,需要将海量样本快速送入GPU,考验的是带宽;推理阶段,要迅速加载模型、响应请求,考验的是延迟;数据预处理环节,则经常面对海量小文件,考验的是元数据性能。如果使用为数据库和虚拟机设计的传统存储来应对这些任务,带宽和IOPS很难满足需求,结果高价购入的GPU只能空闲等待数据到来。
与此同时,私有云自身也在经历新一轮存储架构的重新选择:继续采用超融合将存储与计算绑定,还是将存储独立出来实现扩展?AI负载引入后,这个问题变得更加紧迫——因为AI对存储的需求量和增长速度,往往与计算并不同步。
接下来,我们围绕企业最常问的几个问题,梳理分布式存储的选型逻辑。
二、存算分离与超融合,如何选择?
这是近期讨论最广泛的问题之一。戴尔在2026年主推存算分离架构,声称在特定配置下比超融合可节省最高65%的采购成本。这一数据一经公布,许多企业开始重新审视自己的架构选择。
 存算分离与超融合架构对比示意图
存算分离与超融合架构对比示意图
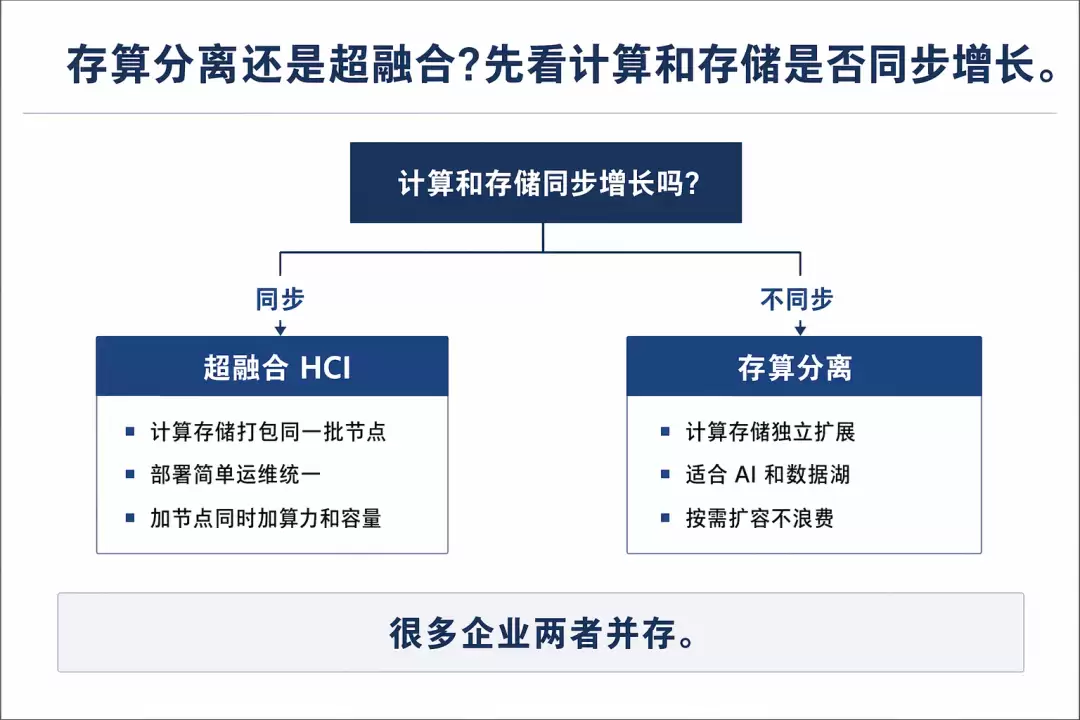
先说结论:两种架构并无绝对优劣之分,关键在于计算和存储的增长节奏是否同步。
超融合适合计算与存储同步增长的场景。计算和存储打包在同一批节点上,部署简单、运维统一,增加节点意味着算力和容量同步提升。如果业务规模可预测、计算存储比例稳定,超融合的简洁性便是实实在在的优势。ZStack的超融合产品线在大量VMware替代和信创落地项目中,正是凭借“一套节点搞定计算、存储与网络”的简洁特性站稳了脚跟。
存算分离则适合计算与存储增长不同步的场景。AI是典型例子:训练任务可能在短时间内需要大量GPU,而数据量则持续稳定增长;反过来,数据湖可能快速膨胀,但计算需求变化不大。此时将存储独立出来扩展,无需为了增加容量而被迫连带购买算力,资源利用更加精细。戴尔所说的65%,正是基于这种按需独立扩展所节省的冗余采购成本。当然需要提醒的是,这仅是厂商在特定配置下的内部测算,实际节省多少还需结合自身负载和许可模型重新核算。
因此,选型首先要回答一个问题:计算和存储是否同步增长。同步,则超融合省心;不同步,则存算分离更经济。讨论“哪个架构更先进”其实是一个伪命题。许多企业的最终做法是两者并存:核心业务运行超融合,AI和数据湖则采用存算分离。
三、分布式存储的三副本与纠删码,如何权衡?
确定走存算分离后,下一个问题是如何保障数据可靠性。分布式存储通过多副本或纠删码来应对硬件故障,两种机制各有取舍。
 三副本与纠删码对比图
三副本与纠删码对比图
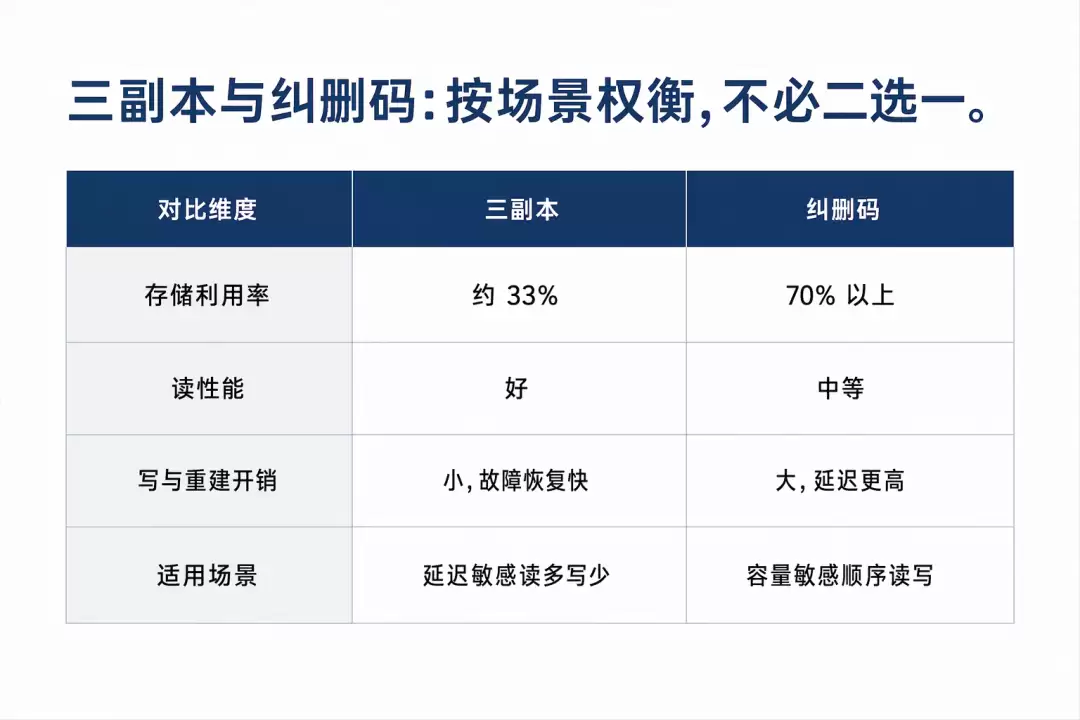
三副本,即将每份数据存储三份,任意一份所在的节点或磁盘损坏,数据也不会丢失。优点是读性能好、故障恢复快;代价是存储利用率仅约三分之一,存储1TB数据需占用3TB空间。对于延迟敏感、读多写少的场景,例如推理服务加载模型,三副本更为合适。
纠删码则类似于RAID的思路,将数据切块并加入校验,用更少的冗余空间达到接近的可靠性,存储利用率可达70%以上。代价是写入和故障重建时计算开销大、延迟更高。对于容量敏感、以顺序读写为主的场景,例如训练数据集、备份归档,纠删码更具性价比。
实际应用中并非必须二选一。成熟的分布式存储支持按存储池配置不同策略:热数据采用三副本以保证性能,温冷数据使用纠删码以节省空间。ZStack企业版分布式存储支持对象、块、文件三种类型,可在同一套存储底座上按业务场景灵活配置可靠性策略,无需为不同需求部署多套存储。
四、AI场景下,存储架构需额外考虑哪些维度?
传统企业存储选型,通常关注容量、IOPS和可靠性即可。但引入AI后,有几个额外维度必须清晰把握。
 AI存储带宽与元数据性能图示
AI存储带宽与元数据性能图示
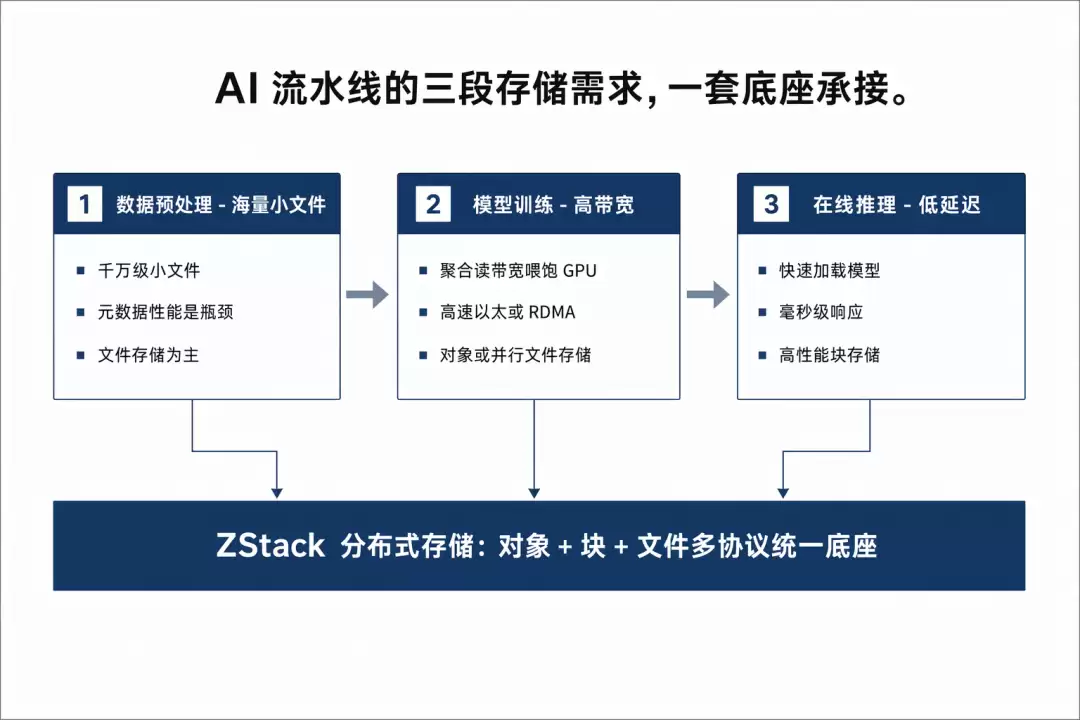
带宽优先于IOPS。训练场景中,GPU集群对存储的并发读带宽要求极高,单纯堆叠IOPS无法解决问题,需要关注聚合带宽能否满足GPU需求。存储网络的规划(高速以太网或RDMA)以及存储引擎的并行能力,在此处比单盘性能更为关键。
海量小文件的元数据性能。AI数据预处理常涉及千万级小文件,此时元数据操作(如列出目录、查询文件)的性能往往比数据读写本身更容易成为瓶颈。选型时需专门压测小文件场景,不能仅依据大文件顺序读写的数据评估。
多协议统一。在AI流水线中,训练可能使用文件存储,模型仓库可能采用对象存储,在线服务则可能依赖块存储。如果每种协议都需要独立的存储系统,数据在不同系统间频繁搬运,既低效又易出错。支持对象、块、文件多协议的统一存储底座,能让数据在同一系统内被不同环节直接访问。
与算力平台的协同。存储并非孤立环节。ZStack分布式存储与ZStack AIOS智塔处于同一技术体系内,存储资源和GPU算力的调度可以协同规划,避免存储与计算各自为政、互相等待。
五、私有云存储选型的实操建议
将前述逻辑落实到具体行动中,企业在进行分布式存储选型时,可按以下步骤推进。
先分清负载类型,再选架构。将现有和规划中的负载按“计算与存储是否同步增长”分类,同步的归于超融合,不同步的(尤其是AI和数据湖)归于存算分离,避免一开始就全盘押注单一架构。
按场景配置可靠性策略,避免一刀切。热数据采用三副本,冷数据采用纠删码,在同一套存储中分池管理,兼顾性能与空间。
AI场景专门压测带宽和小文件。不要沿用传统数据库的测试方法来评估AI存储,带宽和元数据性能需单独验证。
优先选择多协议统一的存储底座。对象、块、文件一套覆盖,减少数据搬运和多套存储的运维负担。
存储是私有云和AI基础设施中最容易被低估、又最难补救的一环。GPU采购错了还能更换,存储架构选错了,数据迁移的代价要大得多。在AI负载不断增长、数据量快速膨胀的当下,将存储选型与算力规划置于同等重要的位置,是私有云能否支撑AI的关键。




