上个月,一个做了四年自动化的朋友跟我吐槽。
他们产品改版,页面重构。四百多个UI用例,跑一次失败两百个。定位器全挂了。他带着两个初级工程师,通宵改XPath、CSS Selector,改完第二天又挂了几个。他说这不是第一次了,每次发版前都像在填坑。
我问他,你们有没有试试AI生成动态定位器?他说试了,ChatGPT写出来的代码跟手动写没什么区别,该断还是断。
问题不是AI能不能写脚本,而是他们还在用三年前的思路做自动化。
2026年的测试行业,已经没有人再怀疑AI能不能干活了。信通院报告显示,全球70%的企业测试用例已由AI生成。传统自动化脚本的月均失效比例超过25%。AI生成测试用例的普及率从2020年的不足10%跃升至当前的70%。
但很多人最大的变化,只是多了一个代码补全工具。该维护脚本的还在维护脚本,该排查随机失败的还在排查随机失败。
工具变了,工作流没变。
另一部分团队已经开始换玩法了。
一、从改XPath到定义意图
先看一个真实场景。
一个典型Selenium脚本是这样写的:
driver.find_element(By.ID, “email”).send_keys(“test”)
driver.find_element(By.XPATH, “//button[text()=‘登录’]”).click()
每一行都包含具体的定位方式、具体的操作顺序、具体的数据。页面结构变化,脚本直接碎一地。
问题的本质是测试意图被淹没在实现细节里。你真正想表达的是“输入邮箱并点击登录”,但不得不写出一堆定位器和等待逻辑。
AI Skill的解法完全不同。
它不是用AI帮你生成一段会过时的脚本,而是把AI作为执行层的一个可调用能力。一个登录验证的Skill是这样定义的:
- 意图:验证邮箱格式校验逻辑
- 输入:测试邮箱地址
- 执行:AI理解当前页面结构,动态定位邮箱输入框,输入值,触发校验,读取错误提示
- 输出:校验结果是否匹配预期
整个Skill里没有任何写死的XPath。所有定位由AI在运行时实时完成。
这个转变的本质是从“步骤驱动”升级到“意图驱动”。测试工程师不再花时间伺候定位器,而是花时间定义“什么算正确”。
二、脚本维护的本质困局
传统自动化测试有一个天然缺陷:把“做什么”和“怎么做”焊死在了一起。
这不是代码写得差的问题。
Selenium脚本的每一行都在描述“怎么做”——用ID找元素、用XPath找按钮、等待三秒、点击。但“做什么”被淹没在这些实现细节里。维护成本随着UI变动指数级增长。
本质上是抽象层次太低。
传统自动化脚本在三个层面存在根本性脆弱:
- 脚本与UI强耦合。 页面结构调整,定位器失效。不是脚本逻辑错了,是“路”变了。
- 异常处理僵化。 脚本只认得预设的路径。页面加载慢了一点、弹窗多了一个、按钮文字改了一个字——全部失败。
- 维护成本随用例量指数增长。 四百个用例,每个都要单独维护。改一个页面结构,改四百个地方。
这三个问题叠加的结果是什么?
维护工作量占比超过60%,月均脚本失效率高达25%。测试团队不是在写自动化,是在给自动化写“售后”。
另一个层面是范式变化。如果说2023-2024年是AI辅助测试的探索期,那么2025年则是AI深度融入测试全生命周期的转折点,而2026年,AI将从“辅助”走向“主导”。AI智能体将人工智能从被动响应的工具,升级为具备自主规划、推理与协作能力的“决策伙伴”。测试活动将从“脚本驱动”跃迁至“目标驱动”。
三、AI Skill 的工程架构
抛开玄学,AI Skill是一个可调度的、结构化的智能任务单元。
它的内部架构可以拆解成四个工程层:
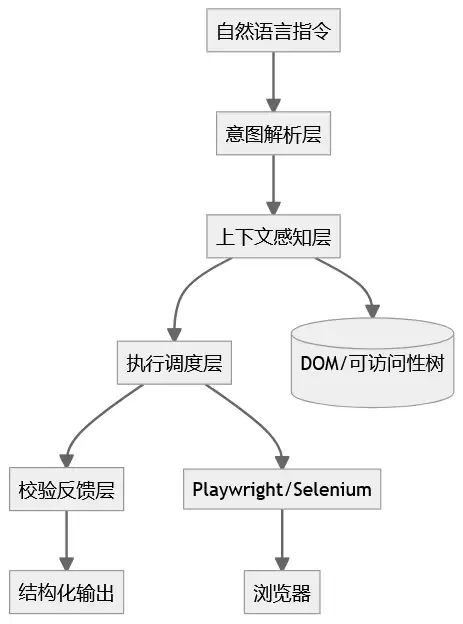
第一,意图解析层。
接收自然语言或结构化指令。比如“验证登录页邮箱格式校验”,模型把这句话拆解成:目标页(登录页)、动作(输入邮箱并触发校验)、预期行为(显示错误提示)、校验项(邮箱格式)。这一层把人类模糊的描述转成机器可执行的计划。
第二,上下文感知层。
Skill不能盲目操作。它需要知道当前页面长什么样、有哪些可交互元素、每个元素的语义是什么。实现方式通常是抓取DOM树或可访问性树,压缩后注入模型上下文。这是AI定位器能工作的核心——模型不是猜XPath,而是看完整页面结构后推理出最匹配目标语义的元素。
目前主流的实现方式有两种路径:
一种是基于MCP(Model Context Protocol)协议,Playwright和Selenium等主流框架正在引入各自的MCP服务器,通过结构化页面快照让AI理解界面并操作。
另一种是多模态视觉驱动,直接通过截图让视觉模型理解界面布局和元素位置。这种方式不依赖DOM结构,对复杂动态页面适应性更强。
第三,执行调度层。
将解析后的计划转化为具体的浏览器操作。调用Playwright或Selenium的API,执行点击、输入、滚动、等待等动作。这一层还要处理异常——元素没出现怎么办、超时了怎么办、弹窗挡住了怎么办。
第四,校验反馈层。
执行完操作后,验证结果是否符合预期。不是简单的“有没有报错”,而是语义级别的验证——错误提示文案对不对、页面跳转正不正确、数据状态符不符合预期。
这四个层加起来,就是一个完整的AI Skill工程单元。
四、一个登录页面的两种写法
用同一个场景对比,差异会更清楚。
传统脚本方式:
# 步骤1:打开登录页
driver.get(“https://xxx.com/login”)
# 步骤2:输入邮箱
driver.find_element(By.CSS_SELECTOR, “#email-input”).send_keys(“test@test.com”)
# 步骤3:输入密码
driver.find_element(By.CSS_SELECTOR, “#password-field”).send_keys(“123456”)
# 步骤4:点击登录
driver.find_element(By.XPATH, “//button[contains(@class, ‘login-btn’)]”).click()
# 步骤5:验证跳转
assert “dashboard” in driver.current_url
问题在哪? CSS选择器#email-input可能变成#email,XPath里的class可能从login-btn变成submit-btn,断言里的dashboard可能变成home。改一个页面,全盘皆崩。
Skill方式:
意图:验证正确邮箱密码可成功登录
前置条件:已注册账号test@test.com / 123456
验证点:登录后跳转至仪表盘,显示用户名
没有定位器、没有XPath、没有等待逻辑。AI在运行时实时看页面、找元素、执行操作、验证结果。
核心差异: 前者让人适应脚本,后者让脚本适应变化。
传统方式追求“精准控制”,适合稳定环境下的高效执行。AI驱动方案通过“智能识别”与“行为模拟”,突破动态页面与复杂交互的限制。
这不是谁更好的问题。传统自动化在稳定场景下依然高效,但维护成本随用例量指数增长。AI Skill在动态场景下优势明显,但引入了模型调用成本和不确定性。
成熟的做法是混合架构:核心稳定流程用传统脚本保证效率,高频变动的UI层用AI Skill降低维护成本。
五、工程落地:从哪开始
如果现在想落地AI Skill,有几个实际问题绕不开。
第一个问题:Skill的粒度怎么拆?
拆得太粗,一个Skill干太多事,不稳定、难调试。拆得太细,Skill数量爆炸,编排成本高。
一个可参考的原则:一个Skill只做一件事,但这件事是一个完整的业务语义单元。 比如“登录”是一个Skill,“验证邮箱格式”是另一个Skill。而不是“点击输入框”是一个Skill、“输入文字”是另一个Skill。
第二个问题:稳定性怎么保证?
AI的不确定性是客观存在的。同一个页面,模型这次找到的元素和下次可能不一样。
生产级的做法不是消除不确定性,而是管理不确定性:
- 设置明确的超时和重试机制
- 对关键操作做二次确认(比如点击后验证页面变化)
- 建立降级策略——AI定位失败时回退到传统定位器
- 记录每次执行的上下文,便于失败后复现
第三个问题:现有的测试资产怎么办?
四百个Selenium脚本不可能一夜之间全部重写。
渐进式迁移是唯一可行的路径:
- 识别高频失效的用例——这些是AI Skill最有价值的地方
- 从最核心、最稳定的业务流程开始封装Skill
- 新功能直接用Skill方式写,老脚本逐步替换
- 传统脚本和Skill可以共存,通过统一的调度层管理
第四个问题:反馈闭环在哪?
很多团队把Skill当成“高级版的脚本生成器”——生成了、跑完了、结束了。
但Skill真正的价值在于持续进化。每一次执行的成功与失败、定位器的命中与miss、验证的通过与否,都应该回流到Skill的上下文中。失败的案例用来优化prompt和定位策略,成功的案例用来固化经验。
六、你的测试资产还能撑多久
回到开头的故事。
那个通宵改XPath的朋友,后来换了一种做法。他们把登录、注册、下单、支付四个核心流程封装成了四个Skill。页面改版后,不需要改任何代码。AI重新看页面、重新找元素、重新执行。
UI自动化维护时间从4小时压到了15分钟。
这不是个例。已经有团队在把“登录”“下单”“支付”每个步骤变成独立的Skill,让AI根据一句话自动编排执行顺序和传参。
定义Skill者驾驭AI,仅修脚本者将被替代。
招聘市场已经在反映这个变化。AI Agent、RAG、工作流编排这些词正在频繁出现在技术岗的JD里。企业需求正在从“会写代码”转向“会用AI落地业务”。
测试开发尤其需要关注这个趋势。需求分析、用例生成、日志诊断这些高重复、强流程的场景,正在成为Agent落地的最佳入口。
Skill的本质不是一种新技术,而是一种新的工程抽象方式。它把“测试工程师的经验”从代码里抽出来,变成了AI可以理解和执行的“知识”。
你现在维护的那些自动化脚本,有多少是在描述“怎么做”,又有多少是在描述“做什么”?
如果明天页面重构了,你的测试需要改多少行代码?




