如果您的团队正在使用 GenAI 处理那些不容出错的场景——例如金融、法律、医疗——您必然会遇到一个核心挑战:如何准确判断 AI 输出的结果是否可靠?
近期,Spotify 的金融工程团队公开了一个真实案例:他们利用 GenAI 自动解析全球各地供应商的发片。这些发片格式多样、语言混杂,传统方法难以应对。然而,金融领域受 SOX 合规严格约束,必须为 GenAI 的输出附加“置信度分数”——分数达标则自动处理,不达标则转入人工审核。
本文不讨论复杂的理论,只总结他们可直接复用的实践经验:从三种方法中筛选出最优方案,落地实施的关键细节,以及当前尚未解决的挑战。内容均为实用干货。
1. 为什么高严谨场景必须引入“置信度分数”?
Spotify 的起点很典型,先想清楚“为什么做”,再去找“怎么做”:
- 合规硬要求:金融领域必须遵循
SOX法案,不能凭直觉信任 AI,必须提供明确的可靠性依据。 - 业务容错极低:发片解析中一个数字错误(如金额、税号),就可能造成财务对账混乱,甚至触发合规风险。
- 人工衔接需求:不能完全依赖 AI,也不能完全依靠人工——需要一个置信度分数作为“开关”,自动区分“AI可处理”与“需人工审核”的内容,从而提升整体效率。
 图1:置信度分数必要性示意
图1:置信度分数必要性示意
2. 三种置信度方法实测:两种被淘汰,一种最终留用
Spotify 测试了三种主流方法,每一种都遇到了具体问题,最终只留下一个行之有效的方案。
方案一(已淘汰):校准器模型
该方法使用一个额外的 GenAI 模型,对主模型的输出进行评分——例如询问“这个发片金额解析是否正确?请给出置信度分数”。其优势在于能够独立判断,并可通过学习人工反馈不断优化。但致命缺陷是分数缺乏可解释性:比如模型给出80分,却无法解释为何是80分——合规场景不接受这种“黑箱评分”。此外,输出不稳定,同一结果两次评分可能相差10分以上,而金融场景追求的是“确定性”,而非“随机性”。
方案二(已淘汰):对数概率
该方法通过观察 GenAI 生成每个词时的“自信度”——例如生成“100元”时,查看模型对“100”和“元”的自信值,再平均换算成总分。优点是直接从模型底层获取数据,看似客观。但致命问题在于:分数与实际准确率毫无关联!测试结果表明:得分为90的输出实际上是错误的,而得分70的反而正确——完全不可用。
留用方案:多数投票
做法是让多个不同的 GenAI 模型同时解析同一份发片(例如5个模型),置信度分数取“同意同一答案的模型比例”——5个模型中有4个同意则得80分。为什么选择它?首先,分数与准确率高度相关,测试显示同意模型越多,答案正确率越高,完全符合“分数越高越可靠”的预期。其次,逻辑简洁易懂,“多数同意”这一逻辑,合规团队容易理解,人工审核时也便于解释。最后,结果稳定——只要模型和数据不变,每次评分结果基本一致。
 图2:多数投票方法示意
图2:多数投票方法示意
3. 多数投票落地实施:三个必须关注的细节
“多数投票”听起来简单,但直接用会踩坑。Spotify 做了三个关键优化:
模型数量:5至6个最为合适
文献指出“4至7个模型能平衡多样性和成本”,但实际测试发现:少于5个,容易出现“多数模型都出错”的情况(例如3个模型全部解析错误);多于6个,时间和成本翻倍(模型调用费用高),而准确率提升却微乎其微。因此最终选择5至6个模型,并分散覆盖不同厂商,避免同一厂商模型出现“同质化错误”。
投票需“加权”:准确率高的模型权重更大
并非所有模型准确率相同:例如A模型历史准确率为90%,B模型仅为80%。优化方法是对每个模型按其历史准确率进行加权——A的1票计为1.2分,B的1票计为1分,最终根据“加权总分”计算置信度。这样可以避免准确率低的模型拉低整体分数。
分数需“校准”:使分数与实际准确率对应
原始投票分与实际准确率之间往往存在偏差——例如投票分为80%,但实际准确率仅为70%。解决办法是使用 Platt scaling 算法进行校准:将历史数据中的“投票分”与“实际对错”建立映射关系,将原始80分校准为78分,使分数更贴近真实准确率。
 图3:分数校准示意图
图3:分数校准示意图
4. 尚未解决的挑战:两个临时应对方案
Spotify 也没能做到完美,目前还有两个待解决的问题,他们的临时办法可以参考:
4.1 长文本解析:拆分为小块逐一比对
发片中的长文本(例如地址“北京市朝阳区XX街道XX号”),不同模型的输出常常不一致——有的遗漏“街道”,有的多出“市”,无法直接计算“共识”。临时方案是将长文本拆解为“小原子”——地址拆分为“城市、街道、门牌号”,每个小块单独计算投票分,最后再汇总。虽然繁琐,但比直接评估长文本准确得多。
4.2 分数粒度不足:为模型设计更多提问
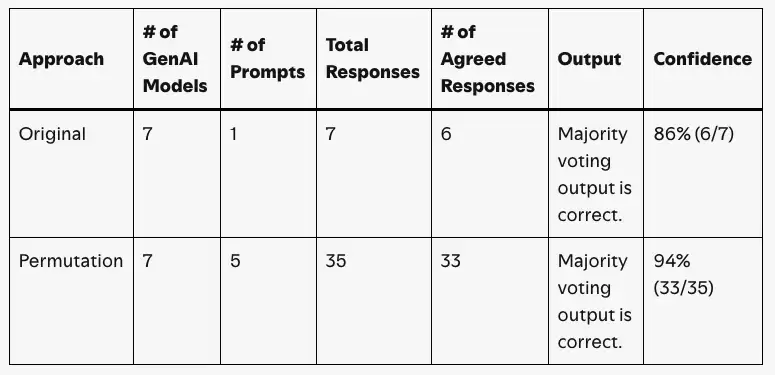
如果仅使用7个模型,分数步长为14%(1/7≈14%)。但某些业务要求达到95%分数才能通过,而95%两侧只能得到100%或86%,这显然不够精细。临时方案是让每个模型使用5种不同的提示词(例如“解析发片金额”“请确认发片上的金额是多少”),总回答数变为7×5=35个,步长粒度降至3%(1/35≈3%),比如33/35≈94%,更贴近业务需求。缺点是成本直接增加5倍,长期仍需寻找更经济的方案(例如使用轻量模型进行多提示)。
 如何获得准确的置信度分数
如何获得准确的置信度分数
5. 三个核心启示与建议
无论你是从事金融、医疗还是法律领域的 GenAI 应用,Spotify 的经验都值得借鉴:
- 选方法先看场景:不要盲目迷信复杂模型。在金融这类追求“确定性”与“可解释性”的场景中,“多数投票”远比“黑箱校准器”更实用。
- 细节决定成败:同样是多数投票,若不做“加权”和“校准”,分数便不准确。落地实施时必须将细节落实到位。
- 接受不完美,小步迭代:长文本、成本等问题暂时无法解决没关系,先采用临时方案运行,再逐步优化——这远胜于等待一个“完美方案”。
如果你的团队也在开发 GenAI 的高严谨场景,不妨从“多数投票”开始尝试。Spotify 已经为你排除了前两个常见的陷阱。




