D集成光学助力万亿参数MoE训练实现2.7倍加速与8倍集群扩展
时间:2026-06-18 16:16
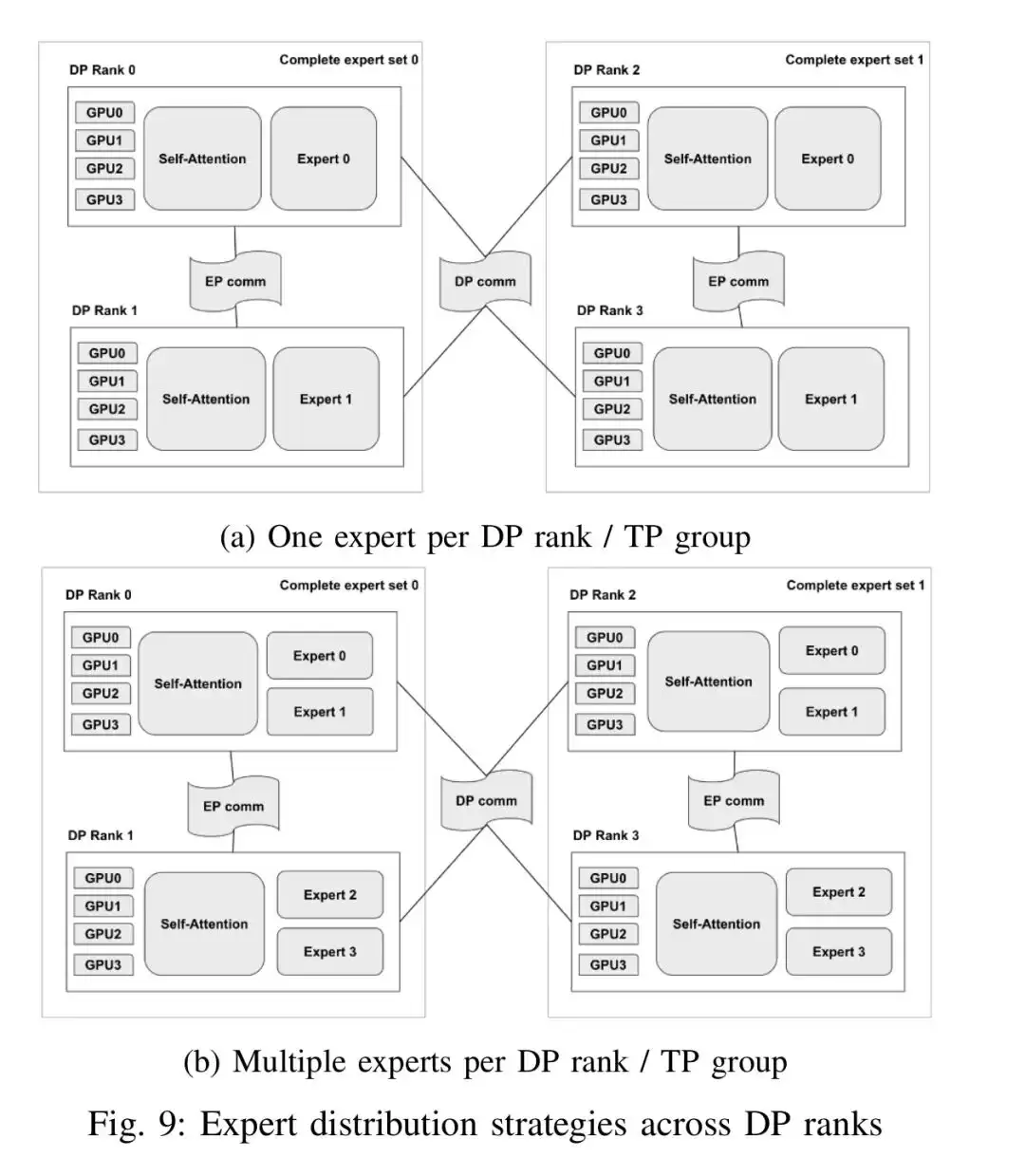
LightmatterPassage3D集成光学平台通过垂直堆叠光子与逻辑芯片,重构了稀疏混合专家模型的互连架构。实测显示,万亿参数MoE训练速度提升2 7倍,集群扩展能力提高8倍,能效达4 3pJ bit,带宽密度为传统方案的6 6倍。
AI模型的参数规模正朝着万亿级、十万亿级急速迈进,传统半导体制程的摩尔定律放缓固然令人担忧,但眼下更紧迫的瓶颈其实出在互连环节——尤其是当模型架构转向稀疏混合专家(MoE)时,专家之间那种高频的“全交换”通信模式,将铜线的物理极限、封装岸线的资源枯竭问题全盘暴露。2025年IEEE高性能互连研讨会上,Lightmatter团队推出了Passage 3D集成光学平台,思路非常直接:将光子芯片与逻辑芯片垂直堆叠,彻底重构了scale-up集群的I/O范式。实测数据显示,针对万亿参数的MoE模型,训练速度可提升2.7倍,集群扩展能力提高8倍。
万亿参数MoE的互连挑战
Transformer从2017年的65M参数一路增长至今,训练所需的GPU也从单节点8卡扩张到了数万卡级别的数据中心。MoE架构凭借稀疏激活机制,在不过度增加计算量的前提下大幅扩展模型容量,已成为大模型演进的主流方案。但问题也随之凸显:专家并行中那个棘手的all-to-all操作,即便在7200Gbps的高速互连系统里,也能占据前向传播延迟的47%。
关键在于,scale-up域越大,可部署的专家就越多,模型性能自然随之提升。遗憾的是传统铜互连已逼近物理极限:224Gb/s速率下,无源铜缆的最大传输距离仅约1米;到了448Gb/s,连1米都难以维持。结果导致电互连的GPU集群被严格限制在单个机架内,目前主流方案最多支持72个GPU包,即便规划中的2027年144 radix交换机面世,也基本触及铜互连的物理天花板。
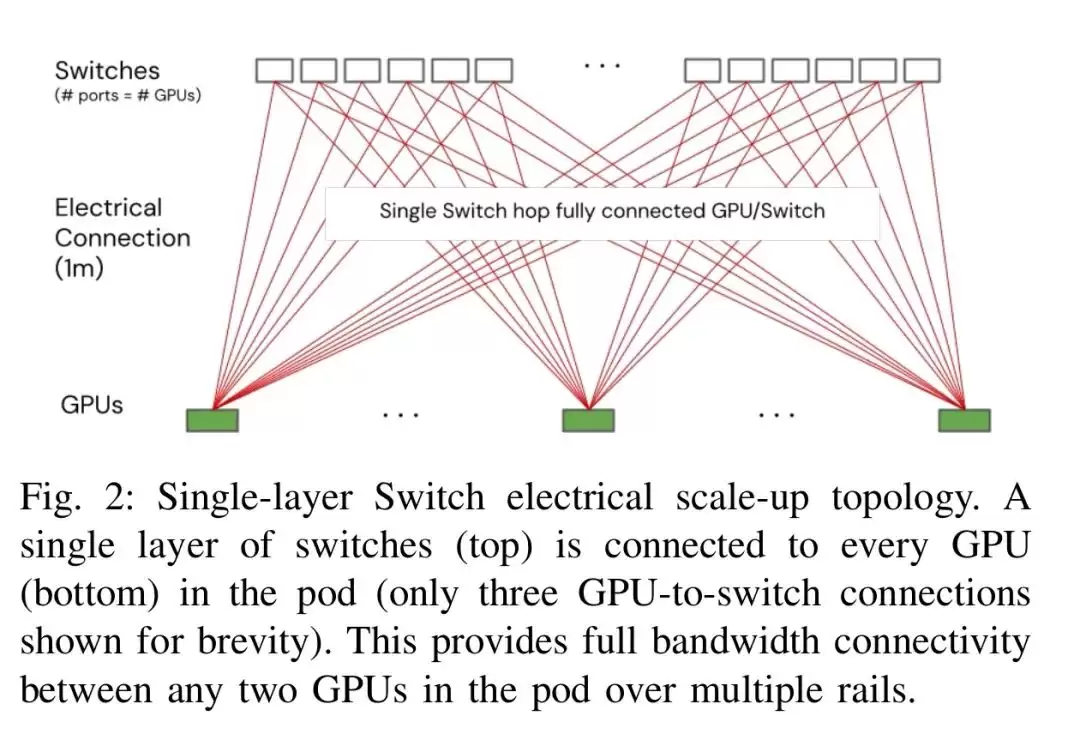
除了传输距离,封装岸线资源枯竭同样棘手。现代高端GPU普遍采用多芯片模块设计,南北两侧的岸线几乎全被HBM内存堆栈占据,仅东西两侧能留给互连I/O。SerDes接口想提速,信号完整性和功耗都在施加压力,进一步挤压了计算资源的功率预算。

传统光学方案的三重上限
为绕开铜互连的距离限制,业界并非没有尝试其他路径——可插拔光模块、线性可插拔光学(LPO)、2.5D共封装光学(CPO)均有人探索。但问题在于,这些方案没有一个能同时兼顾能效、密度和可扩展性这三个维度的硬性指标。
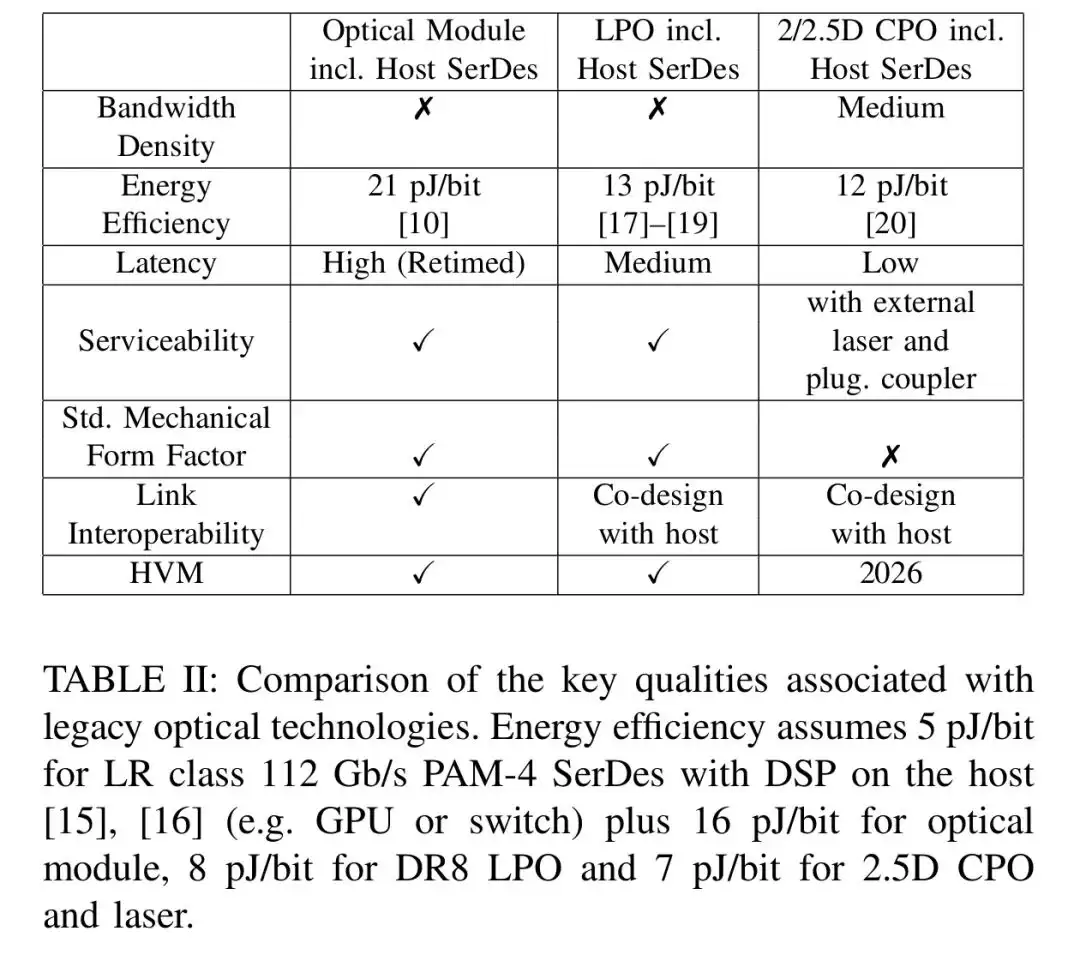
可插拔光模块虽然维护方便、互操作性强,但内置的DSP和重定时器导致总能耗高达21pJ/bit,而且单个模块面积超过2000平方毫米,带宽密度仅为1.3Gb/s/平方毫米。LPO移除了模块内的DSP,能效提升至13pJ/bit,但它仍需依赖host端的高性能SerDes,大尺寸的OSFP-XD模块也解决不了密度问题,高带宽需求下甚至需要冷板冷却。
2.5D CPO将光引擎与主机芯片共封装在同一基板上,电信号传输距离缩短,能效推进到12pJ/bit。可惜2.5D集成方式下,光引擎和host芯片仍是并排布局,需要大量岸线资源做信号扇出,封装面积明显膨胀。2.5D光引擎的带宽密度约为34Gb/s/平方毫米,仍无法满足下一代GPU的I/O需求。更关键的是,这些传统光学方案的功耗并未真正降下来——如果用可插拔光模块搭建NVLink spine网络,光模块部分就要消耗20kW功率,而一个机架的功率预算总共仅120kW,相当紧张。
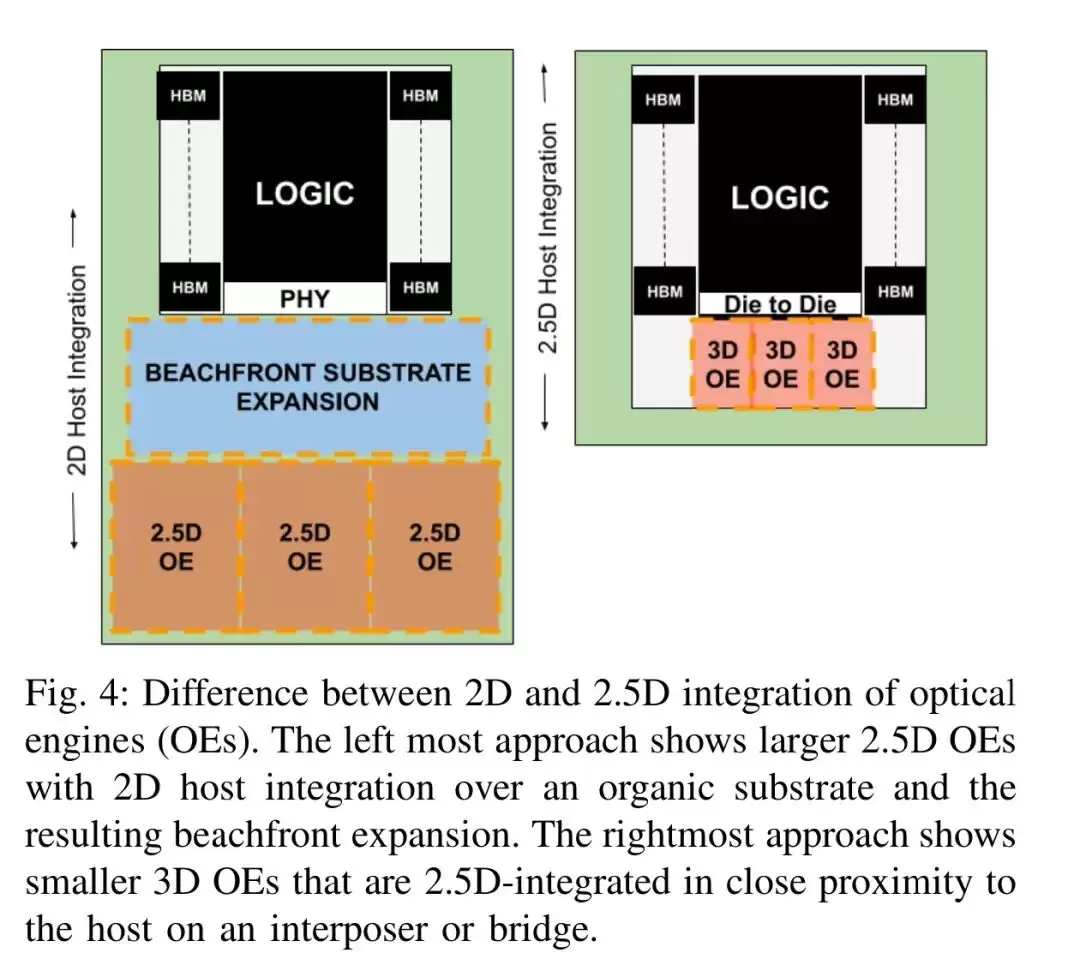
Passage 3D集成光学:重塑GPU与交换机的I/O范式
Lightmatter的Passage平台走了一条截然不同的路:全3D堆叠架构,将电集成电路(EIC)直接堆叠在光子集成电路(PIC)之上。这一设计彻底颠覆了I/O逻辑——SerDes到光电转换单元的距离被压缩至100微米以内,因此能采用无需DSP的低功耗短距SerDes,能效和带宽密度直接跃升至新高度。
具体而言,Passage的核心创新体现在四个方面:
**1. 3D堆叠与TSV互连**:PIC芯片集成了硅光子组件和硅通孔(TSV),可直接为上层的EIC供电和传输信号。这意味着I/O接口不再受限于芯片岸线,而是能散布在整个芯片面积上——岸线资源枯竭的问题就此被绕过。
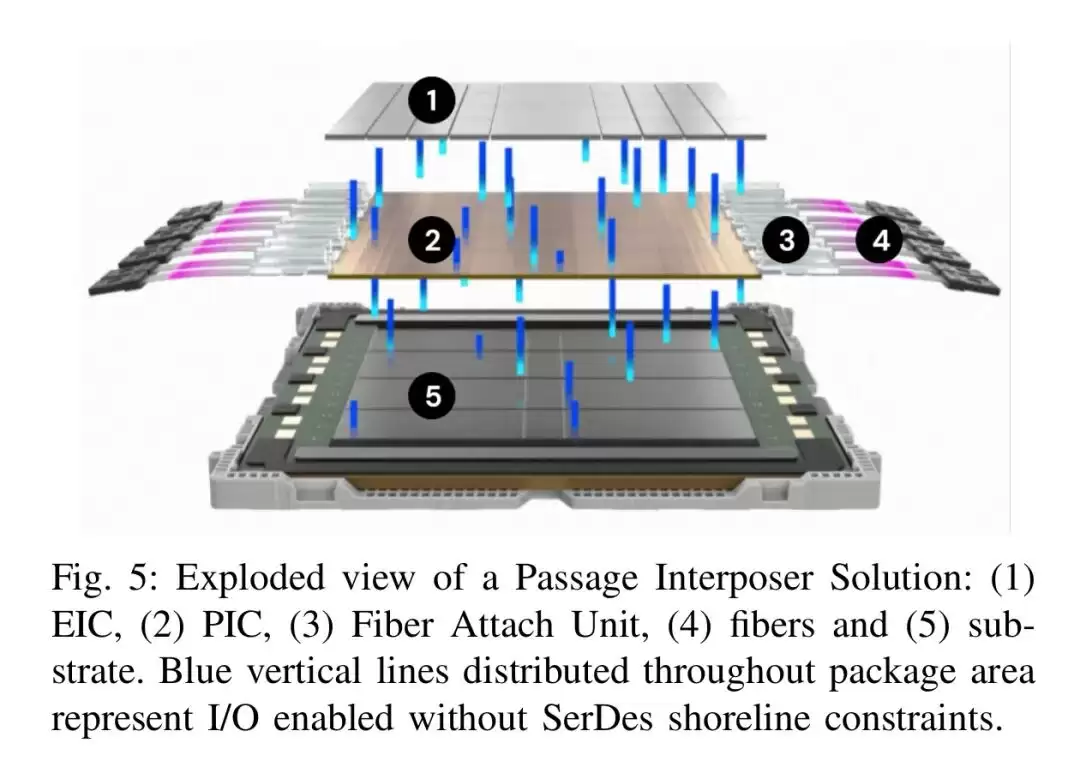
**2. 高密度波分复用(WDM)**:采用微环调制器(MRM)阵列,单根光纤能同时传输16个波长。在112Gb/s PAM-4调制下,单纤带宽达到1.792Tb/s——是传统单波长CPO方案的8倍。同时支持双向传输,光纤利用率更高。
**3. 片上光交换(OCS)**:集成了马赫-曾德尔干涉仪(MZI)构成的2×2光开关单元,可实现可编程的片上光路重配置。这不仅带来了组件级的容错能力,还支持跨掩模版的波导拼接,为晶圆级计算架构打下基础。
**4. 外部激光器设计**:激光器模块独立于GPU或交换机封装之外,通过专用光纤为系统供光。散热和可靠性问题迎刃而解,激光器损坏可单独更换,且其功耗不计入封装内的功率预算——等于为计算资源多留了些功率余量。
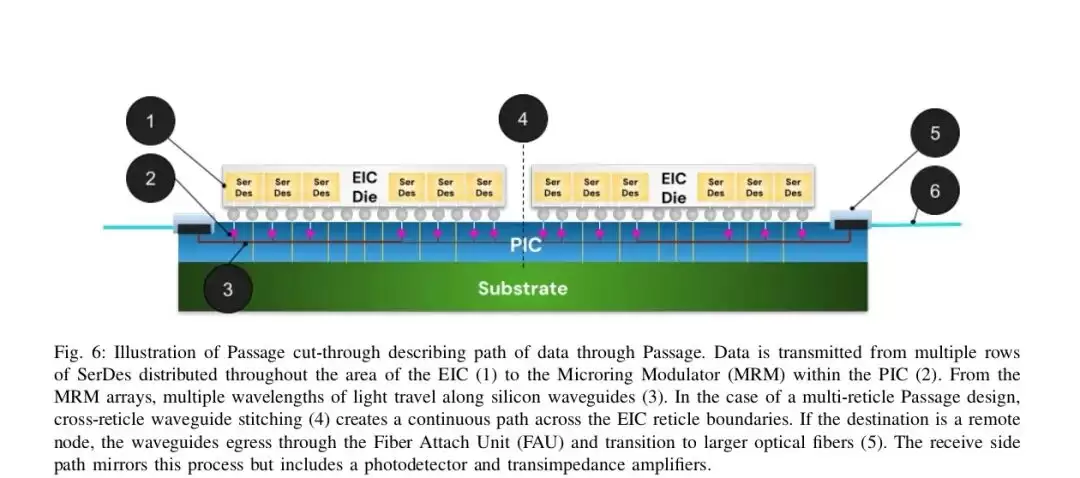
这几项技术叠加后,Passage实现了4.3pJ/bit的总系统能效(包括PIC、激光器和SerDes)。这个数字不仅远优于所有传统光学方案,甚至比带DSP的铜互连方案还要低。带宽密度则达到了160Gb/s/平方毫米——分别是LPO的123倍、2.5D CPO的6.6倍。
系统级设计优势:能效碾压与面积革命
为验证Passage在实际系统中的表现,研究团队对比了三条技术路线来构建512个GPU包的scale-up pod:LPO、2.5D CPO,以及Passage光中介层。所有方案均采用448Gb/s的端口带宽和单层交换(SLS)拓扑。

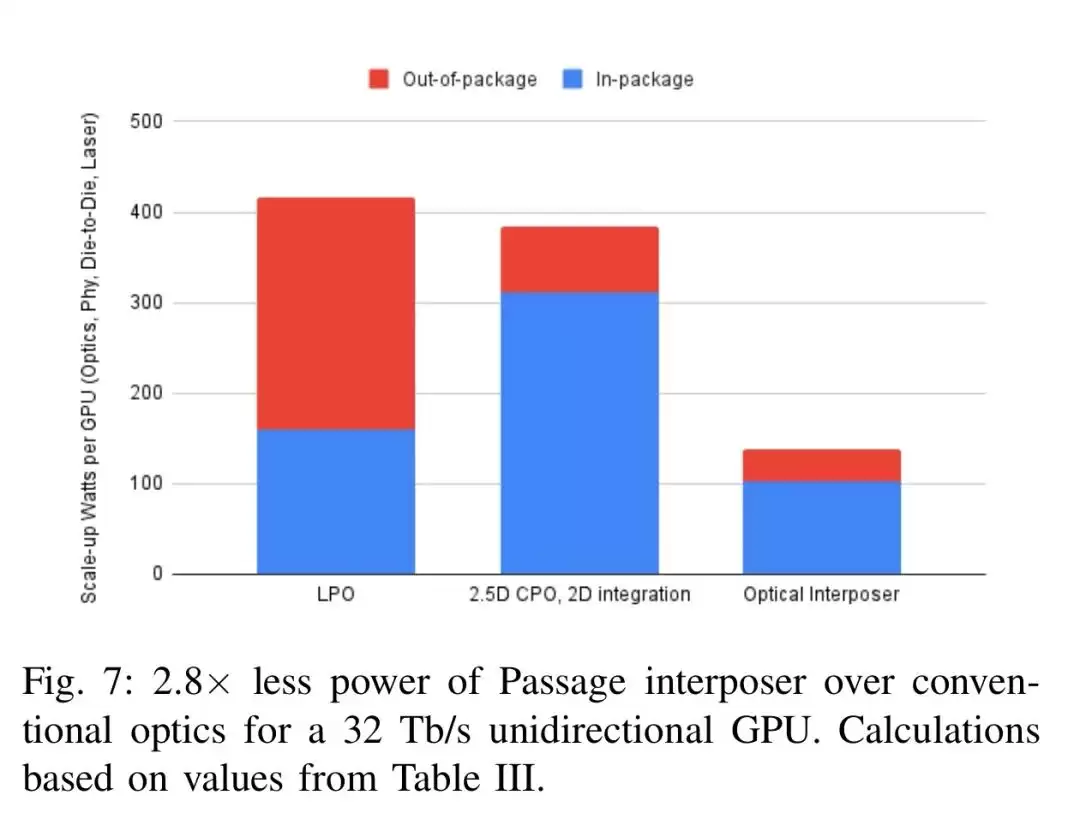
在能效方面,对于32Tb/s单向带宽的GPU,Passage的总功耗仅为传统光学方案的1/2.8。具体来看,LPO的总能耗为13pJ/bit,2.5D CPO为12pJ/bit,而Passage只有4.3pJ/bit。其中Passage的片内能耗为3.2pJ/bit,片外激光器仅1.1pJ/bit,且这部分不占用GPU的功率预算。
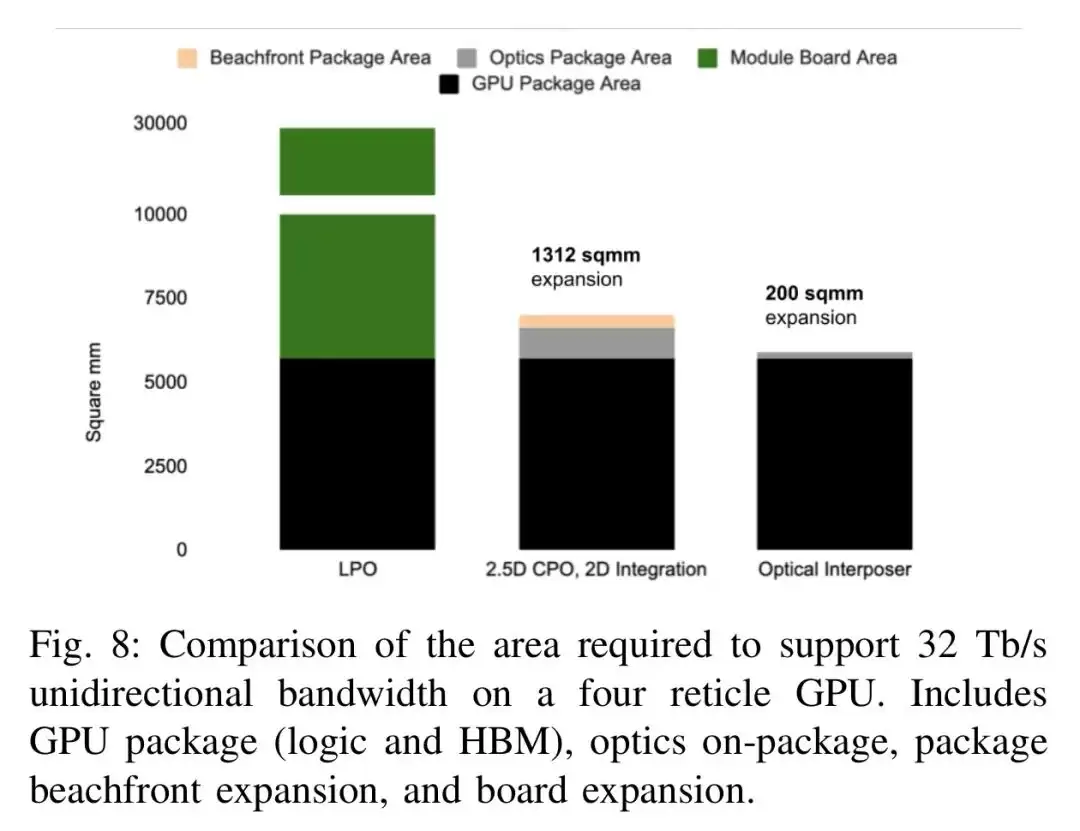
面积上的差距更为显著。要实现32Tb/s单向带宽,LPO方案需要10个OSFP-XD模块,占据超过20000平方毫米的板级面积;2.5D CPO方案需要3个12.8T光引擎,导致GPU封装面积增加23%;而Passage光中介层仅额外增加200平方毫米的面积,GPU封装面积仅增加3.5%,几乎可以忽略不计。
在交换机设计上,Passage的优势同样一目了然。要构建512端口、200Tb/s的单层交换机,LPO和2.5D CPO方案因岸线资源紧张,均需采用4个全掩模版设计;而Passage将SerDes分散到整个芯片面积上,在更小的封装内即可实现相同带宽,每台交换机还能节省1.5kW功耗。
万亿参数MoE训练实测:2.7倍加速的底层逻辑
研究团队开发了一套专用的LLM训练性能分析工具,对一个4.7T参数的MoE模型进行了建模验证。该模型为120层解码器-only架构,模型维度12288,128个注意力头,训练配置了32768个GPU,张量并行度16,数据并行度256,流水线并行度8,全局批量大小4096,序列长度8192,训练数据量13T tokens。
对比测试设置了两类系统:传统电互连系统,scale-up pod大小144个GPU包,单GPU单向带宽14.4Tb/s;Passage光学系统,scale-up pod大小512个GPU包,单GPU单向带宽32Tb/s。同时测试了四种不同的专家配置,从1/32(激活1个/共32个专家)到8/256(激活8个/共256个专家),基本覆盖了当前主流MoE模型的架构特征。
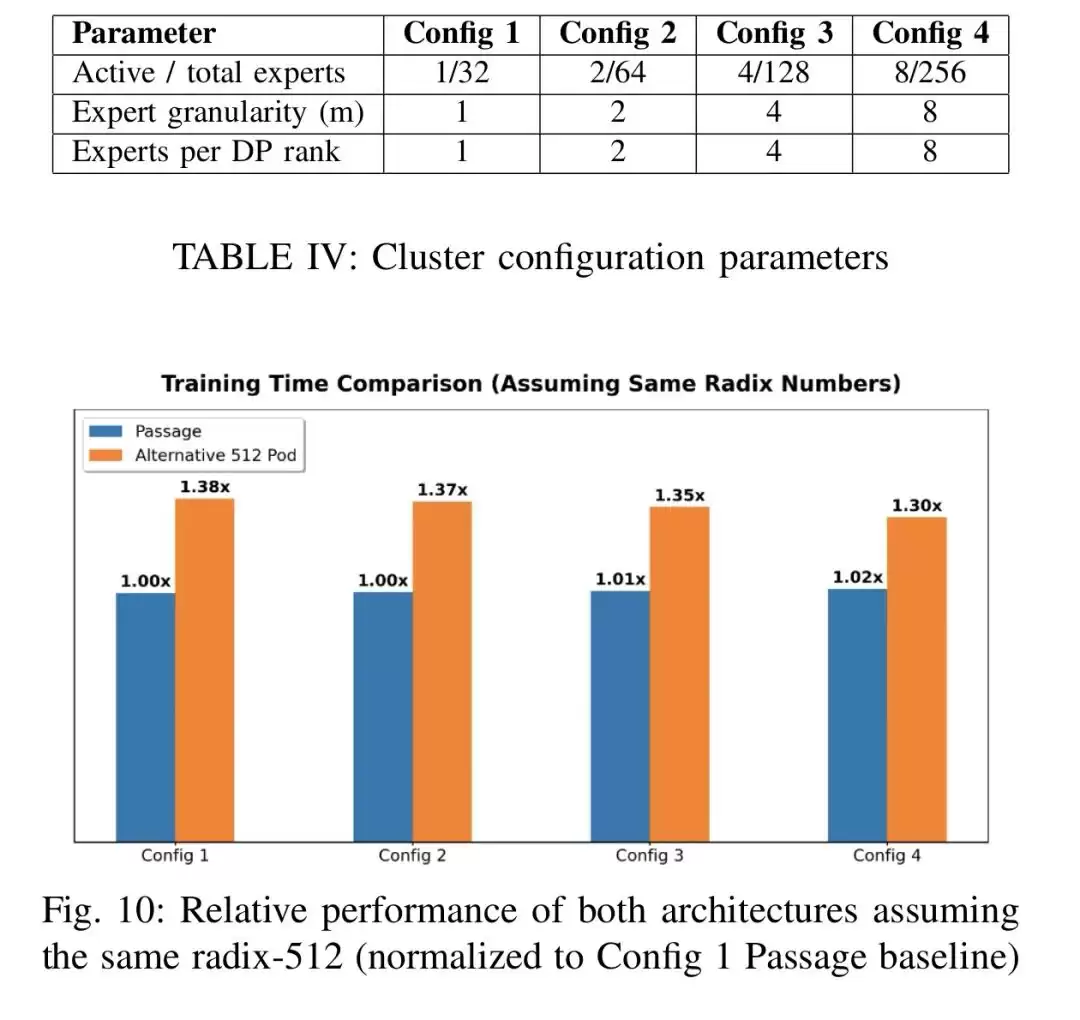
测试结果颇具启发性。当两种系统都采用512 radix的相同拓扑时,Passage凭借更高的带宽优势,在所有专家配置下都能获得1.3到1.4倍的训练加速。而在实际系统配置下,随着专家粒度变细、激活数量增多,Passage的优势呈指数级放大:在1/32专家配置下加速1.6倍,在最复杂的8/256专家配置下,加速比直接飙升至2.7倍。
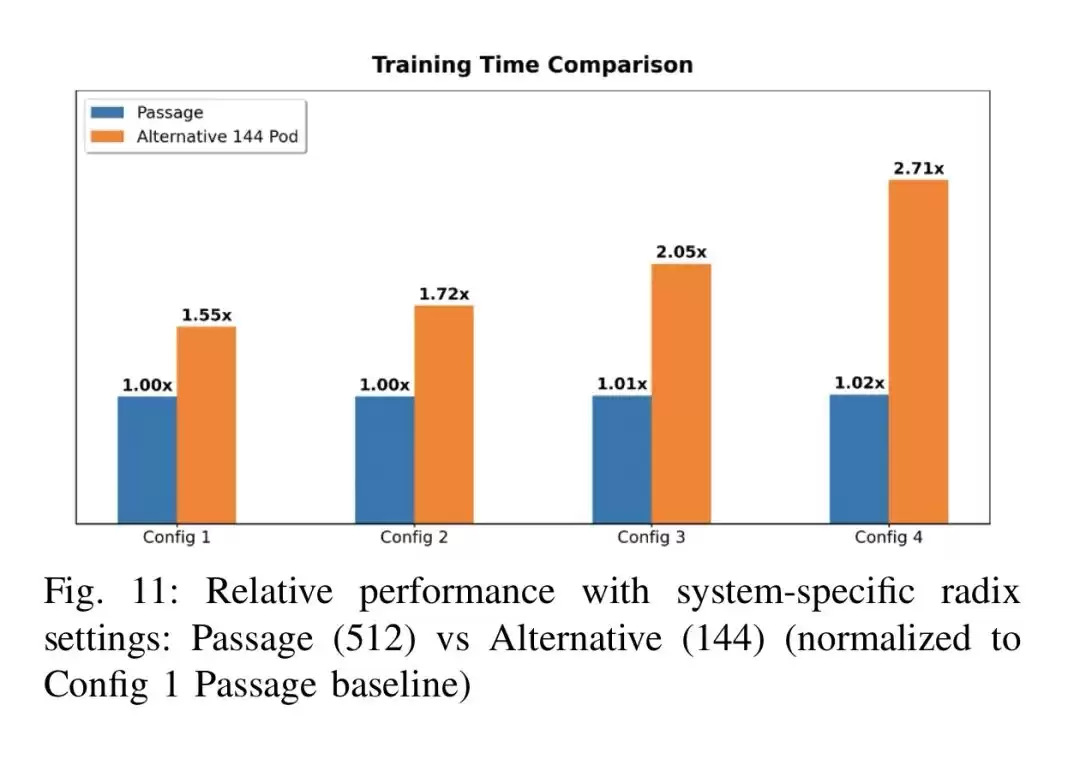
这背后的逻辑其实不难理解:Passage将scale-up域的规模从144个GPU包扩展至512个,原本需通过低速scale-out网络传输的专家并行通信,现在能在高速scale-up域内完成。在传统系统里,专家并行通信受限于scale-up域的大小,大部分流量不得不走1.6Tb/s的以太网链路,成为性能的“肠梗阻”;而Passage系统能容纳更多专家并行组在高速域内,这一瓶颈自然消除。再加上高带宽的加持,即使专家粒度更细、通信量更大,依然能保持接近线性的扩展效率。
更值得一提的是,Passage的架构优势还简化了MoE模型的训练流程。传统系统为防网络拥塞,需设计复杂的负载均衡策略和设备限制路由;而Passage的高带宽和大scale-up域让这些限制变得不再必要,专家可更灵活地被调度和利用,系统整体效率进一步提升。
结论与未来
Lightmatter的这项研究,首次系统性地证明:3D集成光学是突破AI训练集群scale-up瓶颈的终极方案。Passage平台凭借革命性的3D堆叠设计,同时实现了能效、带宽密度和扩展能力的跨越式提升——scale-up域规模翻了8倍,万亿参数MoE模型的训练速度提升了2.7倍。而且,随着模型规模和专家复杂度的持续增长,这一优势只会愈发明显。




