对深度依赖AI辅助开发的数据产品经理来说,WorkBuddy堪称一款令人又爱又恨的工具。爱的是它确实能大幅提升工作效率,恨的是积分消耗速度一度让人心疼到不敢轻易提需求。不过经过一个多月的反复磨合,不少用户已经成功走出“积分焦虑”。下面就来拆解两个最典型的使用痛点,以及经过验证的解决策略。
痛点一:积分如流水,需求还没改完
刚开始使用WorkBuddy时,很多人像点外卖一样频繁提交需求——每次对话动辄消耗50到100积分,一天下来几百积分就没了,可实际交付的仪表盘却总存在偏差。后来经验表明,关键策略必须调整:不再“边想边问”,而是“先撰写完整的PRD文档,再一次性投喂”。把数据源字段、计算逻辑、交互细节、甚至异常边界都写清楚,一次性粘贴给WorkBuddy。虽然准备文档需要花费一些时间,但单次需求积分消耗从平均80分降到了30分左右——因为AI不再需要反复追问上下文,回答准确率显著提升,总积分消耗反而降低了60%。
痛点二:改一个板块,连带崩三个板块,数据还丢失
这是最让人崩溃的场景。曾经在“销售看板”里新增一个同比环比指标,结果WorkBuddy在调整时连带把“区域排行”和“趋势图”的过滤逻辑也改了,甚至有一次直接清空了之前配置好的数据集关联,不得不花大量积分重新沟通恢复。可行的应对方案是:版本化沟通 + 范围锁定。每次提新需求时,明确加上一句:“仅调整【XX板块】的【YY指标】,其他所有板块逻辑保持不变,请勿改动。”如果涉及数据结构变更,先要求WorkBuddy输出“影响范围清单”,确认无误后再执行。同时,定期手动导出关键配置作为备份——出问题后能快速回滚,不再依赖AI回忆历史。
现在,每月积分消耗稳定在初始额度的70%以内,且产出质量更加可控。WorkBuddy依然是得力助手,但用好它的关键在于“清晰的边界定义与前置规划”。希望这些经验能帮到同样面临积分消耗问题的同行们。

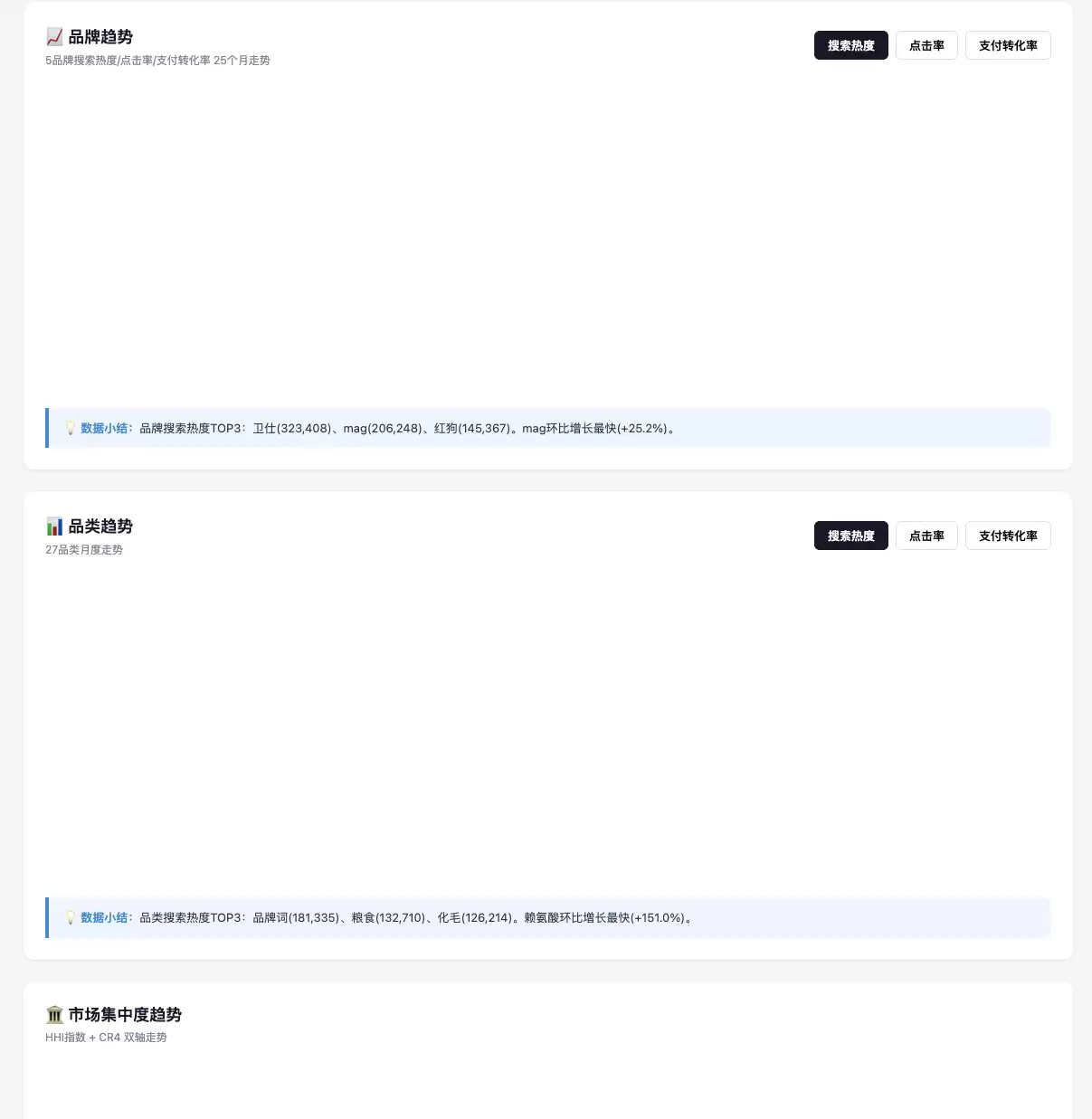 修改后经常出现空白,需要重新运行数据,额外消耗大量积分
修改后经常出现空白,需要重新运行数据,额外消耗大量积分
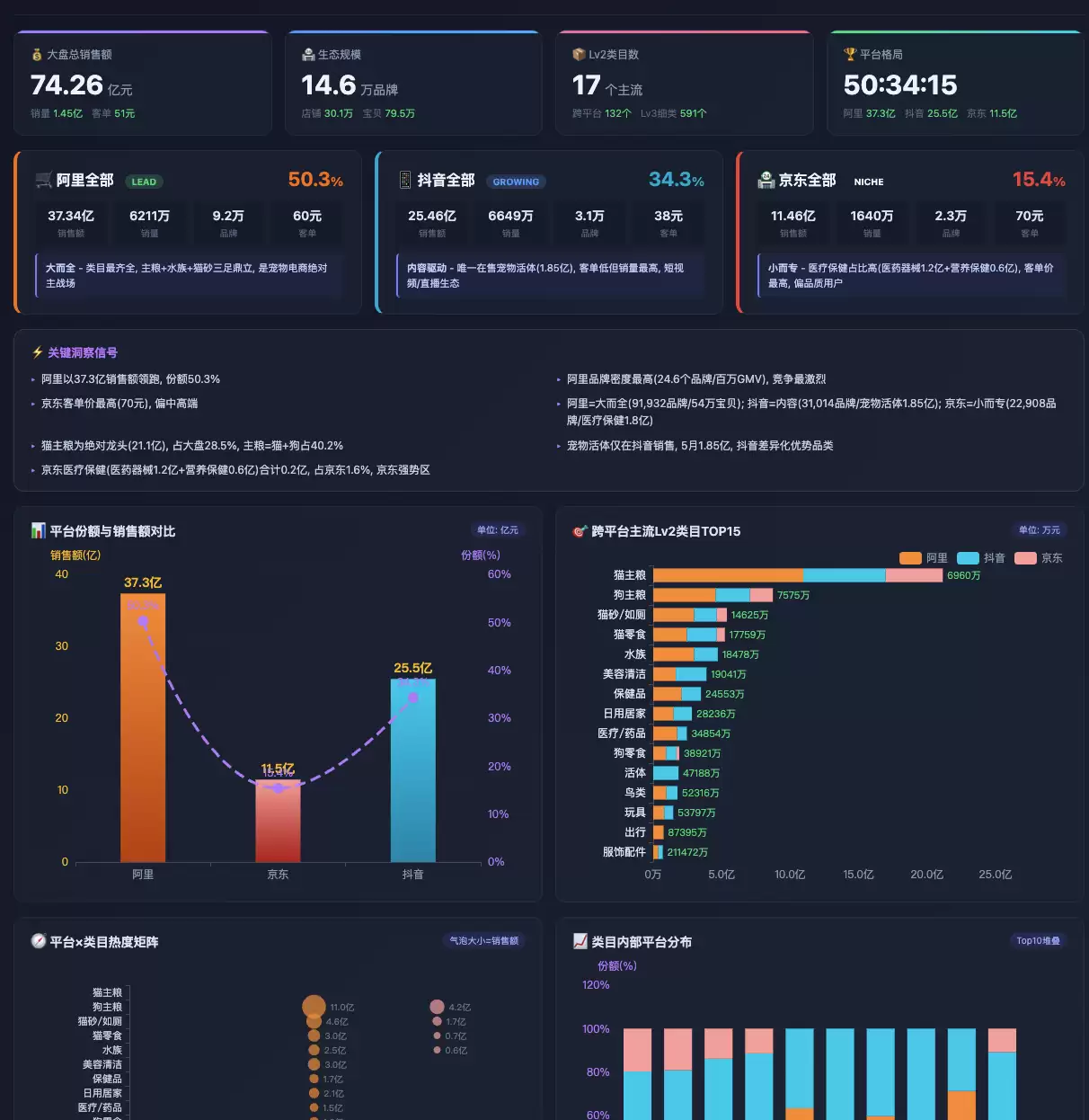 展示一张已完成的管理看板
展示一张已完成的管理看板




