ShardingJDBC actual-data-nodes 动态扩展功能自测验证
先说下测试背景:本次实验的核心目标,是验证 ShardingJDBC 中 actual-data-nodes 的动态扩展能力——在配置阶段预先定义好分片规则后,应用启动过程中能否通过 API 动态修改节点列表,从而实现无需重启服务即可调整分片范围的效果。下面将详细记录整个测试过程、配置细节以及实践中的关键注意事项。
动态修改 actual-data-nodes 的配置类实现
package com.shardingjdbc.shardingjdbcstu.config;
import lombok.AllArgsConstructor;
import org.apache.shardingsphere.core.yaml.config.sharding.YamlTableRuleConfiguration;
import org.apache.shardingsphere.shardingjdbc.spring.boot.sharding.SpringBootShardingRuleConfigurationProperties;
import org.springframework.stereotype.Component;
import ja vax.annotation.PostConstruct;
import ja va.util.Map;
/**
* @author qb
* @version 1.0
* @since 2022/3/11 16:48
*/
@AllArgsConstructor
@Component
public class TestConfig {
private final SpringBootShardingRuleConfigurationProperties shardingRuleConfigurationProperties;
@PostConstruct
public void init(){
Map tables =
shardingRuleConfigurationProperties.getTables();
YamlTableRuleConfiguration order = tables.get("order");
String actualDataNodesTo = order.getActualDataNodes();
//TODO: 可以查询数据库,根据数据关联表
StringBuilder stringBuilder = new StringBuilder("ds0.order$->{[");
stringBuilder.append("202101,202102");
stringBuilder.append("]}");
order.setActualDataNodes(stringBuilder.toString());
String actualDataNodes = order.getActualDataNodes();
System.out.println(actualDataNodesTo);
System.out.println(actualDataNodes);
System.out.println(tables);
}
}
这段代码的设计思路非常直接:在 Bean 初始化阶段(通过 @PostConstruct),获取 ShardingJDBC 自动注入的配置属性对象,然后直接修改 order 表的 actualDataNodes,将原本 YAML 中配置的 ds0.order$->{0..1} 替换为 ds0.order$->{[202101,202102]}。需要注意,setActualDataNodes 方法接收的是字符串参数,节点写法必须符合 ShardingJDBC 的表达式语法规则。代码中还预留了一个 TODO 标记:实际生产场景下,可以从数据库实时查询已存在的动态表名,再拼接成节点列表,实现自动化扩展。
分片规则 YAML 配置文件详解
spring:
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的ds1,ds1任意取名字
names: ds0
# 给master-ds1每个数据源配置数据库连接信息
ds0:
#配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ksd_order_db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBeha vior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置ds1-sla ve
# ds1:
# type: com.alibaba.druid.pool.DruidDataSource
# driver-class-name: com.mysql.cj.jdbc.Driver
# url: jdbc:mysql://192.168.100.110:3306/ksd_order_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
# username: root
# password: 123456
# maxPoolSize: 100
# minPoolSize: 5
# 配置默认数据源ds0
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,
#那么就会把三个节点都当做从sla ve节点,新增,修改和删除会出错。
default-data-source-name: ds0
# 配置分表的规则
tables:
# ksd_order 逻辑表名
order:
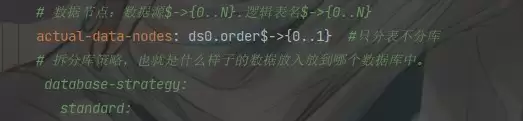
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds0.order$->{0..1} #只分表不分库
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
# database-strategy:
# standard:
# shardingColumn: tenantId # 分片字段(分片键)
# preciseAlgorithmClassName: com.shardingjdbc.shardingjdbcstu.algorithm.TenantShardingAlgorithm
# # 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
# database-strategy:
# inline: #inline 行表达时分片策略(核心,必须要掌握)
# sharding-column: age # 分片字段(分片键)
# algorithm-expression: ds$->{age % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
standard:
shardingColumn: userid #tenantId # 分片字段(分片键)
preciseAlgorithmClassName: com.shardingjdbc.shardingjdbcstu.algorithm.TenantShardingAlgorithm
#需求:用户变1000W的数据,对用户的数据进行分表和分库的操作,根据年龄单数储存在user1 偶数储存在user0
#同时age单数
YAML 配置采用了只分表不分库的方案,数据源仅配置了 ds0。actual-data-nodes 初始值设置为 ds0.order$->{0..1},对应物理表 order0 和 order1。分片策略选用 standard 精确分片,分片键为 userid,算法类为自定义的 TenantShardingAlgorithm。配置注释中保留了之前尝试分库以及 inline 表达式的历史痕迹,但本次测试的重点仅在于验证表节点列表的动态扩展能力,不涉及库维度分片。
分表节点配置验证:从 0..1 到动态节点列表
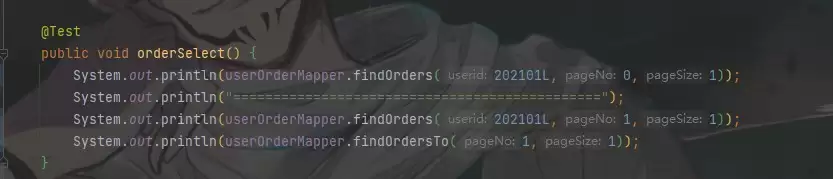
按照预期设计,当通过代码动态修改 actualDataNodes 后,对逻辑表 order 的查询应当路由到 order202101 和 order202102 这两张物理表,而不再访问原始的 order0 和 order1。为了验证这一结果,编写了两条 SQL 测试语句:
@Select("select * from order where userid = #{userid} limit #{pageNo},#{pageSize}")
List findOrders(
@Param("userid") Long userid,
@Param("pageNo") Integer pageNo,
@Param("pageSize") Integer pageSize
);
@Select("select * from order limit #{pageNo},#{pageSize}")
List findOrdersTo(
@Param("pageNo") Integer pageNo,
@Param("pageSize") Integer pageSize
);
第一条 SQL 携带分片键 userid,会触发精确分片算法;第二条 SQL 不带分片键,采用全表扫描方式。看一下实际执行结果:
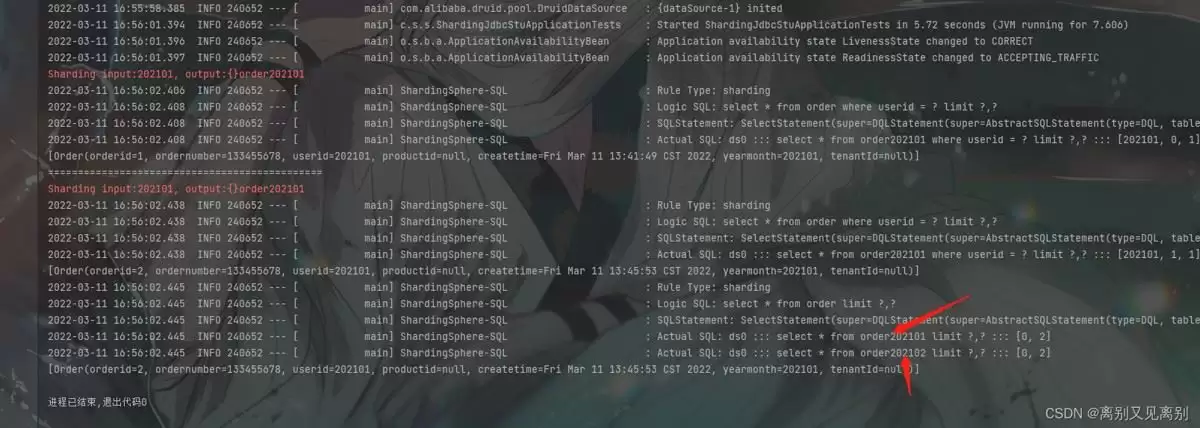
从执行结果可以清晰看出:最后一次查询原本期望路由到 order0 和 order1,但实际路由行为完全遵循了 Config 中动态设置的 ds0.order$->{[202101,202102]}。这表明通过 @PostConstruct 修改 actualDataNodes 的方法完全生效,ShardingJDBC 在初始化完毕后会使用最新的节点配置进行路由决策。
测试总结与生产实践建议
本次测试记录了一个关键结论:ShardingJDBC 的 actual-data-nodes 支持在运行时通过 API 动态修改,且修改后立即生效(前提是在初始化阶段完成配置覆盖)。这一特性对于需要动态增加分片表或调整分片范围的场景具有重要参考价值——例如基于时间维度的分表时,应用可以在启动过程中从数据库读取已存在的表名列表,替换掉固定的节点配置,从而避免每次新增表都需重启应用。当然,本测试中使用的 @PostConstruct 仅是一种简单实现方式,实际生产环境还可结合配置中心、热加载机制等更灵活的方案来达到动态扩展的目的。




