AI工具的技能(Skill)系统,初次体验确实令人满意,但长期使用后,你会发现一个尴尬的问题:每次写出的“指令”似乎大同小异,甚至某些操作重复了很多次,却始终未能沉淀下来。这其实是一种资源的浪费。
今天我们来探讨一种更高级的玩法——Skill进化系统。它要解决的核心议题是:如何让AI的Skill从“写完后闲置吃灰”,转变为“越用越顺手、越来越贴合你的需求”。

这套系统覆盖的三个层次价值,分别对应三类读者:
- 个人层:将编程时的高频操作固化成一条指令,打造专属的AI助手
- 团队层:从协作中提炼共识,让团队成员配合更默契
- 组织层:使知识资产持续增值,新人从“无从下手”到“快速上手”,成长周期大幅缩短
一、为什么需要Skill进化系统
静态Skill的困境

你可能也有过类似经历:编写了一个不错的Skill,使用几次后发现它开始跟不上变化。新项目规范变了、团队流程调整了、甚至你自己的工作习惯也在迭代。但那个Skill依然停留在原地——你说它不好用吧,它也不算错;你说它好用吧,又总觉得哪里不对劲。
这种静态的Skill模式,隐藏着不少隐患:指令不清晰导致AI偏离预期、边界条件未覆盖全使结果不可靠、缺少示例让AI难以理解你的真实意图……久而久之,你宁愿手动输入一遍,也不愿费心去修改那个Skill。
进化的本质:从“写好就用”到“越用越好”
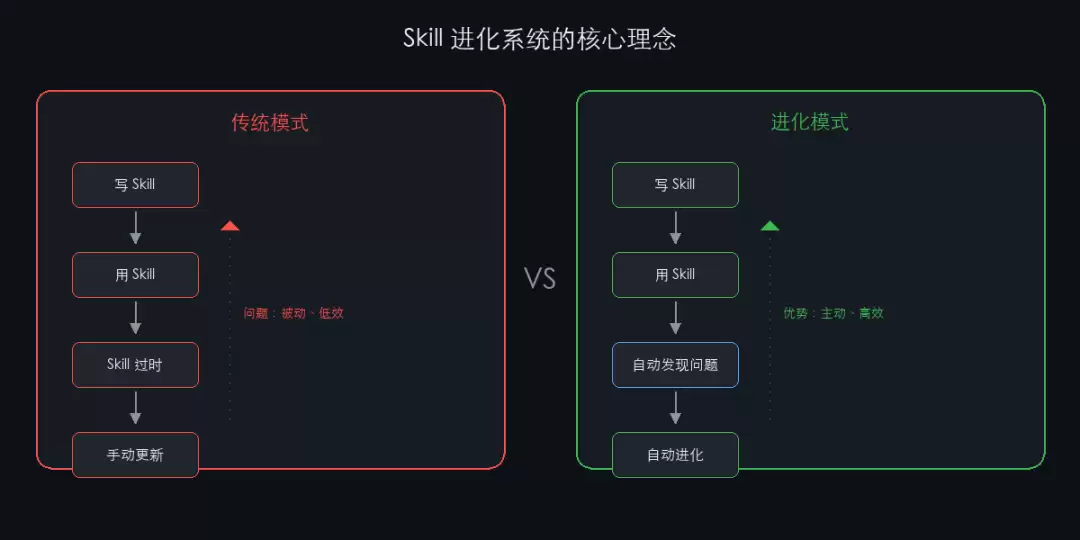
关键转变在哪里?
- 被动等待 → 主动发现:系统可以自动扫描你的会话和代码,定位可优化的环节
- 手动维护 → 智能迭代:基于实际使用数据,自动生成优化建议
- 个人孤岛 → 知识流动:一个人的经验,自动沉淀为团队的资产
三层价值,对应三类读者
| 读者 | 关注点 | 获得价值 |
|---|---|---|
| 开发者 | 个人效率 | 高频操作指令化,节省时间 |
| 技术负责人 | 团队协作 | 协作效率提升,新人上手周期缩短 |
| 管理者 | 组织资产 | 知识流失率降低,最佳实践可复制 |
二、Skill自我进化机制:从问题中学习
核心流程

问题溯源三板斧
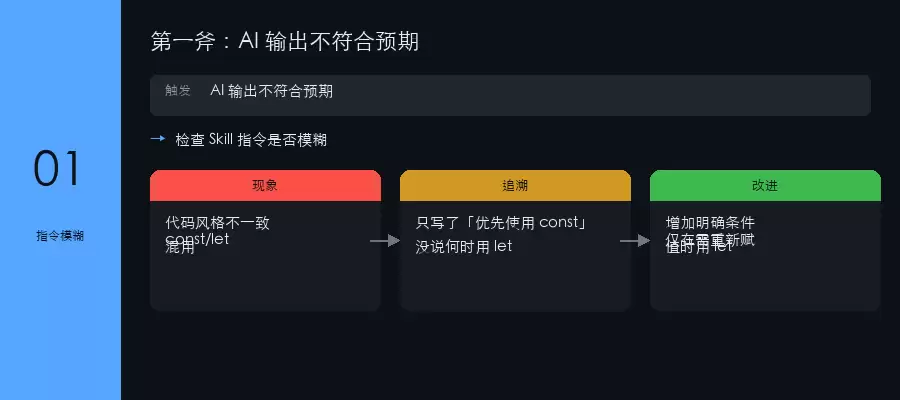
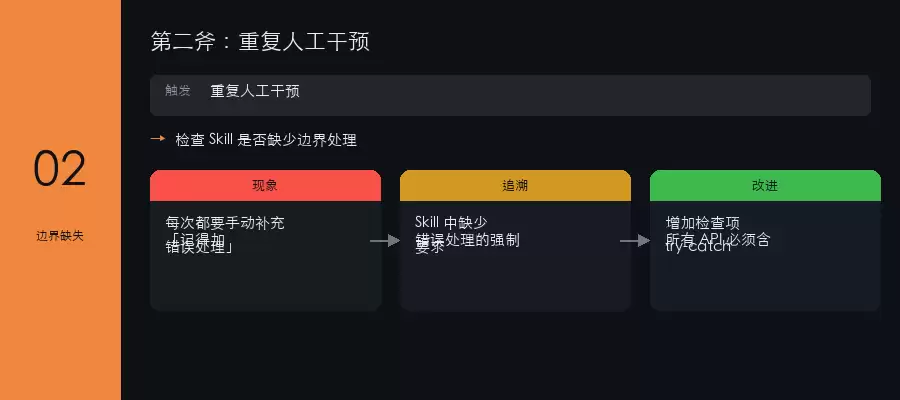

简而言之,AI给出的结果不符合预期,原因通常逃不出这三类:你表达的意图不够明确、AI该做什么不该做什么的边界未划清、或者缺少一个可供参考的示例。找到根因后,问题便迎刃而解。
安全升级原则
Skill进化的底线是保证向后兼容。不能为了新功能,破坏原有好用的部分。核心原则有三个:
原则一:增量扩展,而非覆盖重写
举一个代码中的例子。原先你的“测试要求”Skill是这么写的:
## 测试要求
所有代码必须有单元测试,覆盖率80%以上现在团队发现集成测试也很重要,不要直接删掉重写,而是在原有基础上新增:
## 测试要求
- 基础要求:单元测试覆盖率80%以上(原有)
- 增强要求:关键路径必须有集成测试(新增)原则二:变更日志,追溯每次进化
在每个Skill文件末尾维护一个进化日志,就像Git的commit记录一样:
## Evolution Log
### v2.1.0 (2024-03-15)
- 新增:关键路径集成测试要求
- 触发:项目复盘发现线上bug源于集成测试缺失
### v2.0.0 (2024-02-01)
- 重构:按开发阶段重新组织结构原则三:兼容性验证
升级后,必须通过三类测试:旧场景回归测试、新场景验证测试、边界压力测试。改完不是终点,验证通过才是。
三、个人开发风格沉淀:从会话中提炼Skill
核心流程

会话挖掘四步法
第一步:扫描——遍历历史对话,标记高频模式。
用LLM分析会话日志,找出那些你反复询问、反复修改、反复调整的内容。这些东西,就是Skill的种子。
第二步:聚类——按意图分类。
将这些模式分组:调试类、重构类、文档类、部署类……分门别类,便于后续处理。
第三步:提炼——抽象为标准化工作流。
把对话序列转化为结构化的Skill文件。例如你每次进行代码防御性编程检查,都可以抽象成这样一个模板:
---
name: defensive-check
description: 代码防御性编程检查
---
## 检查清单
### 1. 边界检查
- 空值处理:所有入参是否判空
- 类型检查:类型转换是否安全
### 2. 异常处理
- try-catch覆盖:是否捕获可能异常
- 错误传播:异常是否有意义的错误信息
### 3. 并发安全
- 线程安全:共享资源是否加锁第四步:命名——生成可记忆的命令别名。
给每个Skill起个好记的名字,比如:defensive-check → /defchk,review-checklist → /review。下次要用,只需输入几个字母即可。
从提示词到命令的转化示例
每次Code Review前都要手动检查一堆项目,特别麻烦。你就可以把它沉淀为一个叫review-checklist的Skill:
---
name: review-checklist
description: Code Review前的自查清单
---
## 核心检查项
1. **边界条件**:空值、越界、异常输入
2. **性能影响**:复杂度、数据库查询、内存
3. **测试覆盖**:单元测试、集成测试下次要用了,直接输入/review,清单就出来了,无需再费力回想还有哪些未检查。
个人Skill库的积累效应
| 阶段 | Skill数量 | 覆盖场景 |
|---|---|---|
| 初期 | 3-5个 | 60%高频场景 |
| 中期 | 10-15个 | 80%日常工作 |
| 成熟期 | 20+个 | 90%+场景 |
就像练级一样,一开始只有几个核心技能,随着使用越来越多,你的Skill库会不断完善,覆盖的场景也会越来越广。
四、团队开发风格建模:从协作中提炼Skill
核心流程
项目完成 → PR/代码分析 → 风格模式提取 → 团队Skill生成 → 共享与迭代
个人Skill搞定了,团队级的怎么弄?道理其实是一样的,只不过分析的对象从“你的对话”变成了“团队的PR和代码”。
团队风格识别三维度
维度一:代码风格层——命名约定、文件组织、注释习惯、错误处理
维度二:协作流程层——PR描述模板、Review关注点、分支命名规范、合并策略
维度三:决策模式层——技术选型倾向、重构时机判断、测试覆盖要求
PR分析挖掘示例
假设你分析了团队过去3个月的PR数据:
- PR描述分析:80%的PR包含了“影响范围”章节,75%的PR包含了“测试方案”章节
- Review评论分析:“是否有性能影响”出现了45次,“测试是否充分”出现了52次
这些数据和模式,足以沉淀成一个团队级的Skill:
---
name: team-pr-workflow
description: 团队PR提交与审查工作流
---
## PR提交前自查
- [ ] **影响范围**:说明变更涉及的模块
- [ ] **测试方案**:描述如何验证变更正确性
## Reviewer关注清单
- 是否有性能影响
- API变更是否同步更新文档团队Skill vs 个人Skill的分层管理
.claude/skills/
├── personal/ # 个人Skill(不提交Git)
├── team/ # 团队Skill(Git共享)
└── org/ # 组织Skill(跨团队通用)| 层级 | 覆盖范围 | 更新频率 |
|---|---|---|
| Personal | 个人习惯 | 随时 |
| Team | 团队共识 | 每月 |
| Org | 组织标准 | 每季度 |
分层管理的好处是:个人的习惯不影响团队,团队的共识只沉淀大部分人认可的内容,组织的标准更加稳定。这样既保留了灵活性,也保证了统一性。
五、落地实施:从零开始搭建Skill进化系统
5.1 Claude Code的目录结构
~/.claude/
├── history.jsonl # 全局会话历史
├── projects/ # 按项目分目录存储
├── skills/ # Skill文件目录
└── plugins/ # 插件形式的Skill5.2 会话日志分析脚本
用一个脚本就能扫描所有历史会话,找出高频模式:
python analyze_conversations_v2.py --all --min-count 3 --output analysis.json --report
python create_skill_v2.py --from-analysis analysis.json --top 5第一行分析,第二行直接生成前5个最值得提炼的Skill。效果立竿见影。
5.3 Skill文件创建脚本
v2版本为每种意图类型预定义了完整模板,包括Workflow、Checklist、Examples、Common Pitfalls。直接套用即可,省去从头编写的功夫。
5.4 团队风格分析脚本
分析团队仓库的代码和PR:
python analyze_team_style_v2.py --repo . --since "3 months ago" --report --skill5.5 Skill迭代更新脚本
python evolve_skill.py --skill review-checklist --add-check "性能影响评估" --reason "复盘发现性能问题遗漏"
python evolve_skill.py --skill review-checklist --validate有了问题就加上,加完就做验证,形成闭环。
5.6 团队协作流程
启动阶段(第1周)
mkdir -p ~/.claude/skills/{personal,team,org}
python analyze_conversations.py --all --min-count 3 --output my-patterns.json
python create_skill.py --from-analysis my-patterns.json --top 5运行阶段(每周)
- 周一扫描:分析上周会话,找出新模式
- 周三评审(30分钟):审核提案、讨论改进、投票采纳
- 周五发布:验证Skill、提交Git、通知团队
每周花30分钟开会讨论,就能让团队的技能持续进化,效率越来越高。
项目复盘阶段
python analyze_conversations.py --project /path/to/project --output project-patterns.json
python evolve_skill.py --skill team-pr-workflow --add-check "回滚方案是否明确" --reason "复盘发现线上问题无法快速回滚"5.7 架构设计
┌─────────────────────────────────────────────────────────────┐
│ Skill进化Agent │
│┌─────────────┐┌─────────────┐┌─────────────┐ │
││ 会话分析器 ││代码风格分析器││ Skill生成器 │ │
│└─────────────┘└─────────────┘└─────────────┘ │
│ ↓ │
│ ┌─────────────────┐ │
│ │ 兼容性验证器 │ │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────────────┘
↑
┌──────────┼──────────┐
项目完成触发 周度触发 手动触发5.8 实施路线图
第一阶段(第1周):跑通最小闭环——安装脚本、创建目录、首次分析、手动创建第一个Skill
第二阶段(第2-4周):团队协作——创建团队Skill Git仓库、建立周度流程、完成3个团队Skill
第三阶段(持续):智能进化——CI/CD集成、A/B测试、跨团队复用
六、效果度量
度量指标
个人层面:高频操作指令化率、重复提示词减少比例、单任务耗时下降
团队层面:PR首次通过率提升、Review轮次减少、新人上手周期缩短
组织层面:Skill复用率、知识流失率降低、最佳实践覆盖率
预期收益
个人开发者:减少重复操作时间,能够更专注于创造性工作,且个人经验可以持续积累
技术团队:协作效率提升,沟通成本降低,代码风格更加统一
组织整体:知识流失率降低,新人培养周期缩短,最佳实践可复制
常见问题
Q: Skill太多会不会造成选择困难?
A: 通过分层管理和智能推荐解决。个人、团队、组织三层隔离,Agent会根据上下文主动提示你该用哪个,长期不用的Skill自动标记为“待归档”。无需担忧。
Q: 团队Skill如何平衡不同成员的风格差异?
A: 只沉淀共识部分。团队Skill仅包含大家明确同意的内容,个人偏好保留在个人Skill中。不强行统一。
Q: 如何防止Skill过时?
A: 持续进化机制保证活性——周度扫描、项目复盘检查、使用频率监控。过时的内容,系统会自动标记出来,让你决定是否更新或归档。
七、从今天开始
说再多,不如动手做。从今天开始,只需三步,就能跑通你的第一个Skill进化闭环:
第一步:运行分析脚本
python analyze_conversations.py --all --min-count 3 --output my-patterns.json第二步:创建第一个Skill
python create_skill.py --from-analysis my-patterns.json --top 1先只生成一个,别贪多。用起来,看看效果。
第三步:验证效果
在下一个项目中使用这个Skill,记录耗时和遗漏率的变化。你会发现,一个精心打磨的Skill,真的能让你的工作效率提升一个台阶。
长期目标
- 短期:减少重复劳动,提升个人效率
- 中期:团队协作更顺畅,知识可传承
- 长期:AI越用越懂你,真正成为你的智能助手




