引言:运维的三个时代
在运维领域的发展历程中,业界通常将其划分为三大关键阶段。
首先是手工时代。那时运维工程师需要手动登录服务器,逐条敲入命令,完全依赖个人经验与记忆来排查故障。随后进入自动化时代,脚本、CI/CD流水线、配置管理工具成为主流,批量操作逐渐普及。如今,我们已迈入第三个阶段——智能运维时代。在这一阶段,AI Agent开始承担日常运维决策,能够自主感知环境、分析数据并做出响应。
今天要探讨的核心议题,正是第三阶段:AI Agent究竟如何重塑运维工作模式。
传统运维 vs AI Agent 运维
场景:服务响应变慢
先看一个最常见的情景:服务响应突然变得迟缓。
传统方式下,整个处理流程大致如下:收到告警 → 登录服务器 → 查阅日志 → 紧盯监控面板 → 开始分析定位 → 可能还需反复排查多轮 → 最终算下来,半小时已经过去。
换成AI Agent方式呢?用户仅需简单描述问题 → Agent自动采集指标、分析日志、定位根因 → 给出建议方案 → 用户确认 → 执行修复 → 验证完成。整个流程走下来,大约只需2分钟。
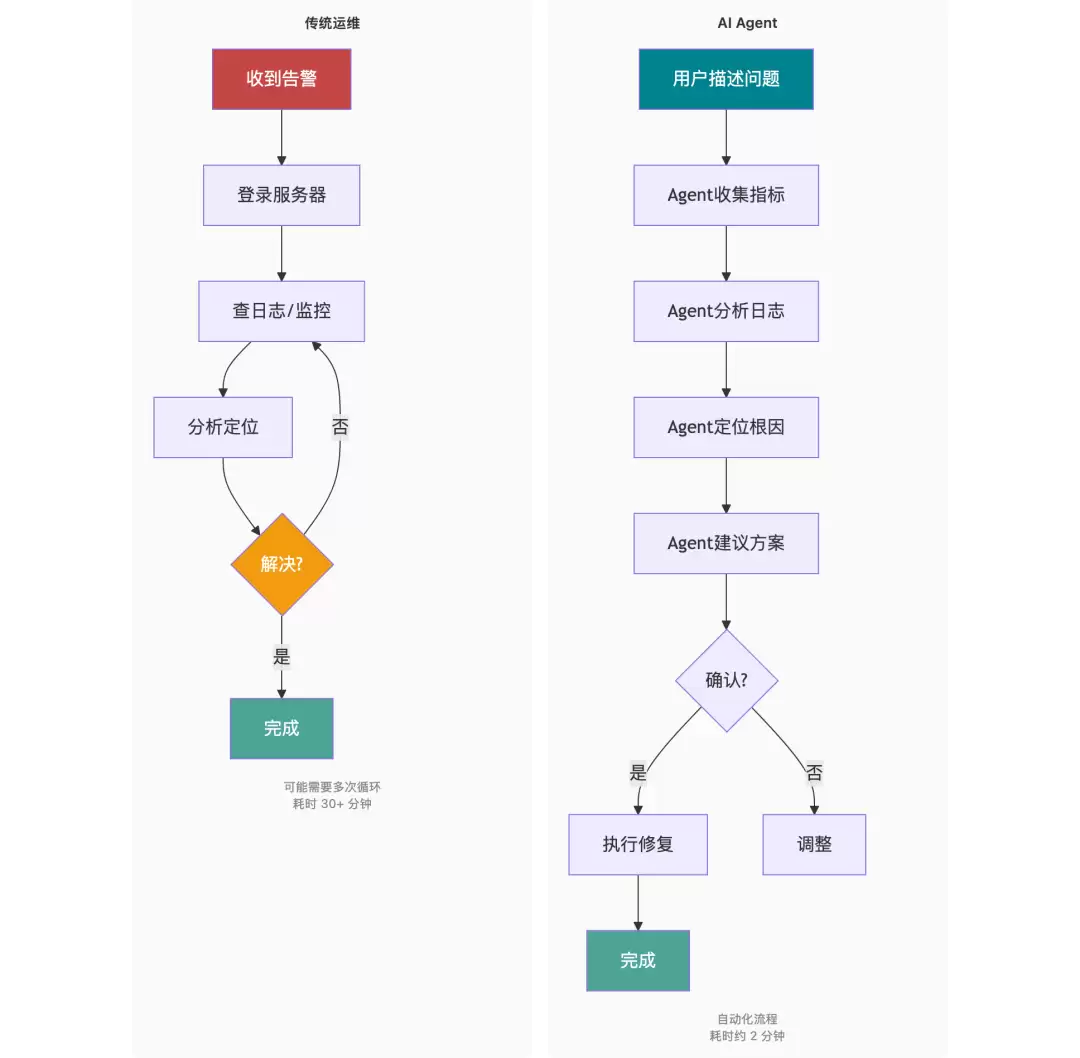 传统运维 vs AI Agent
传统运维 vs AI Agent
时间对比非常直观:传统方式需要30分钟,AI Agent仅需2分钟。
AI Agent 核心能力
能力一:结构化故障诊断
Agent在执行故障诊断时,遵循一套标准化的4阶段流程:
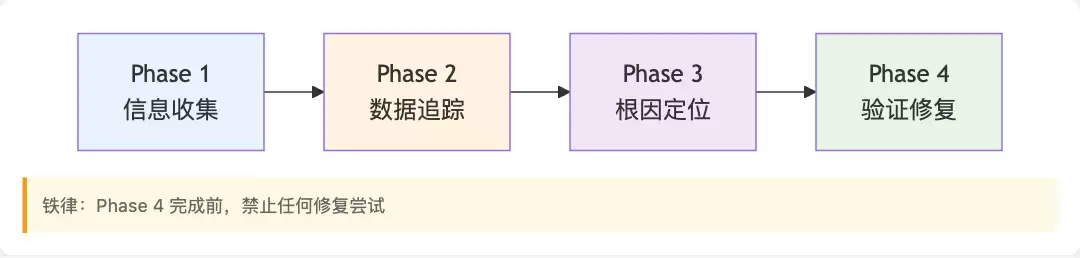 故障诊断4阶段
故障诊断4阶段
Phase 1: 信息收集——读取错误信息、确认复现步骤、检查近期变更、按需添加边界日志。
Phase 2: 数据追踪——追溯错误值的来源,定位完整的调用链路。
Phase 3: 根因定位——对比不同版本的差异,识别关键不同点,排除无关干扰因素。
Phase 4: 验证修复——形成假设、用最小化测试进行验证、确认修复效果、确保未引入副作用。
这里有一条铁律:在Phase 4完成之前,禁止执行任何修复尝试。先想清楚,再动手。
能力二:验证驱动的操作
每次执行操作后,Agent都会自动进行验证。这一点至关重要,因为"做了"不等于"做好了"。
操作 | 验证命令 | 期望结果 | 失败处理 |
|---|---|---|---|
部署服务 | rollout status | rolled out | 自动回滚 |
扩容 | get deployment | 数量匹配 | 告警 |
重启 | curl /health | status=healthy | 重试3次 |
能力三:并行处理多故障
凌晨3点,手机突然被6条告警同时炸醒。这种情况,传统运维只能逐一排查,运气不好就是"拆东墙补西墙"。但Agent可以这样应对:
1. 先做相关性分析——比如CPU高和响应慢是关联问题,Redis和MySQL归为数据库组,证书过期和磁盘空间不足属于维护任务。
2. 并行处理——让3个Agent进程同时处理不同类型的告警。
3. 汇总结果——整体耗时只需4分钟,而传统串行方式大约需要15到20分钟。
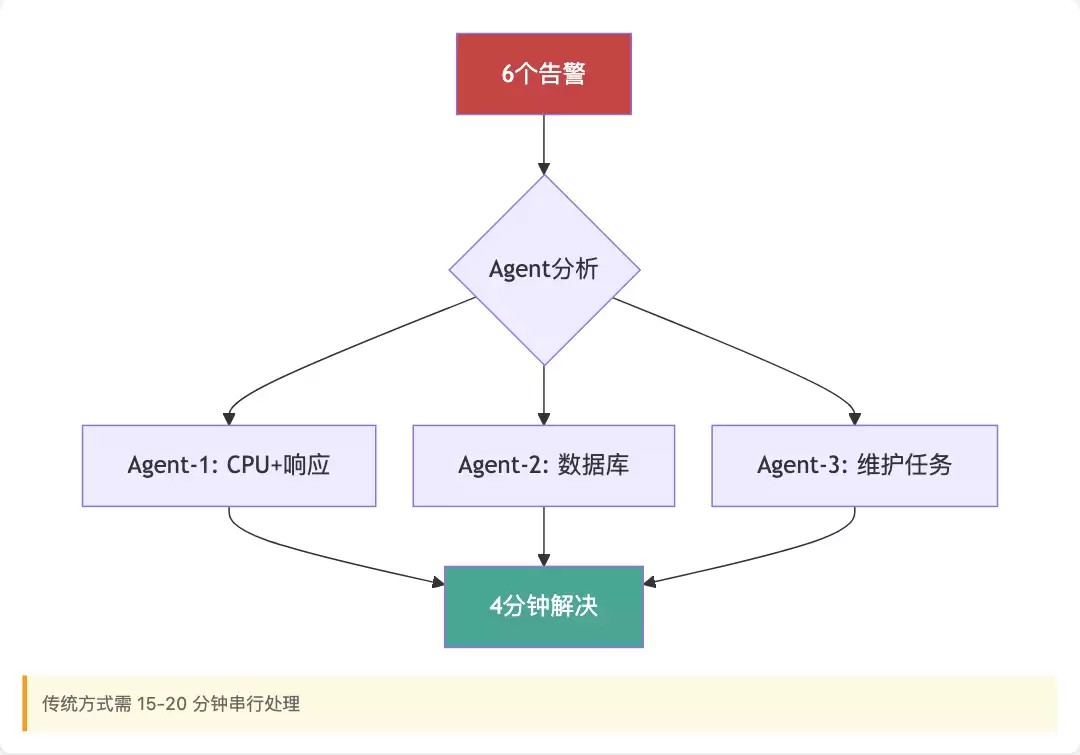 并行处理多故障
并行处理多故障
Skills:运维能力的模块化
Skill 1:系统化调试
触发条件包括:服务失败、测试失败、性能异常。核心原则与上文一致——在找到根因之前,不做任何修复尝试。
Skill 2:CI/CD 部署
部署流程为:预检查 → 滚动更新 → 健康检查 → 生成报告。支持dry-run预演、分批发布、自动回滚等能力。
Skill 3:定时巡检
• 每日健康检查(9:00):检查Pod状态、资源使用情况、错误日志。
• 每周备份验证(周日2:00):检查备份文件、执行恢复测试。
• 每日证书检查(0:00):到期提醒、自动续期。
Skill 4:安全边界控制
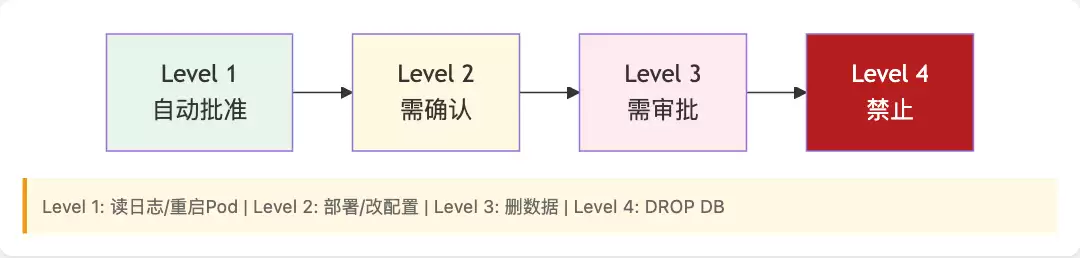 安全边界4级权限
安全边界4级权限
Level 1 自动批准:读取日志、重启Pod、清理缓存、小范围扩缩容。这些操作风险极低,交给Agent全自动处理即可。
Level 2 需确认:部署新版本、修改配置、数据库变更。Agent提出方案,用户点击确认。
Level 3 需审批:删除数据、修改安全组、跨环境操作。这类操作需要更高级别的审批流程。
Level 4 禁止:DROP DATABASE、rm -rf /、删除备份。这些是红线,Agent绝对不能触碰。
Skill 5:告警分诊
优先级分类清晰明确:P0紧急(5分钟内响应)、P1高(15分钟)、P2中(1小时)、P3低(4小时)。
自动响应策略也预设了具体规则:CPU超过90%时收集profile,内存超过85%时检查泄漏,错误率超过1%时分析日志。
真实场景演示
场景一:生产服务OOMKilled
 OOMKilled排查流程
OOMKilled排查流程
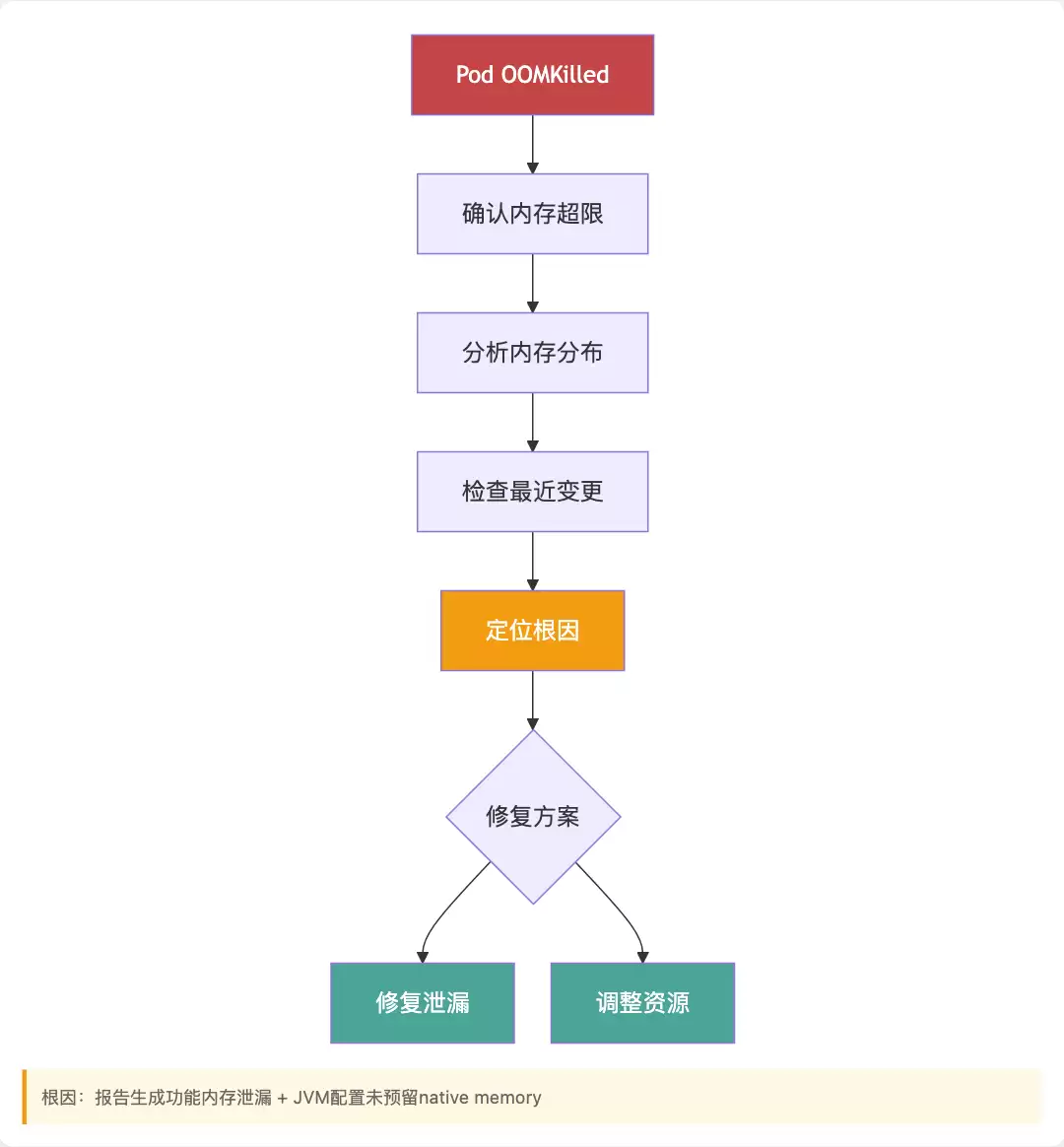
凌晨2:17,Agent收到告警:某个Pod发生OOMKilled。
Agent自动启动排查流程:
02:17:03 → 读取事件:Pod内存使用超过限制(2.1Gi/2Gi)。
02:17:08 → 分析内存组成:堆内存1.8GB,元空间300MB,线程数250。
02:17:15 → 检查变更历史:v1.2.3版本在2小时前部署,涉及报表生成功能。
02:17:28 → 定位根因:报表生成功能存在内存泄漏,JVM没有预留native memory空间。
Agent随后输出诊断报告。
人工确认后,Agent自动创建PR修复泄漏代码,同时调整资源配置。
整个过程耗时4分钟。(传统方式人工排查通常需要20到30分钟)
场景二:数据库连接池耗尽
 连接池耗尽排查流程
连接池耗尽排查流程
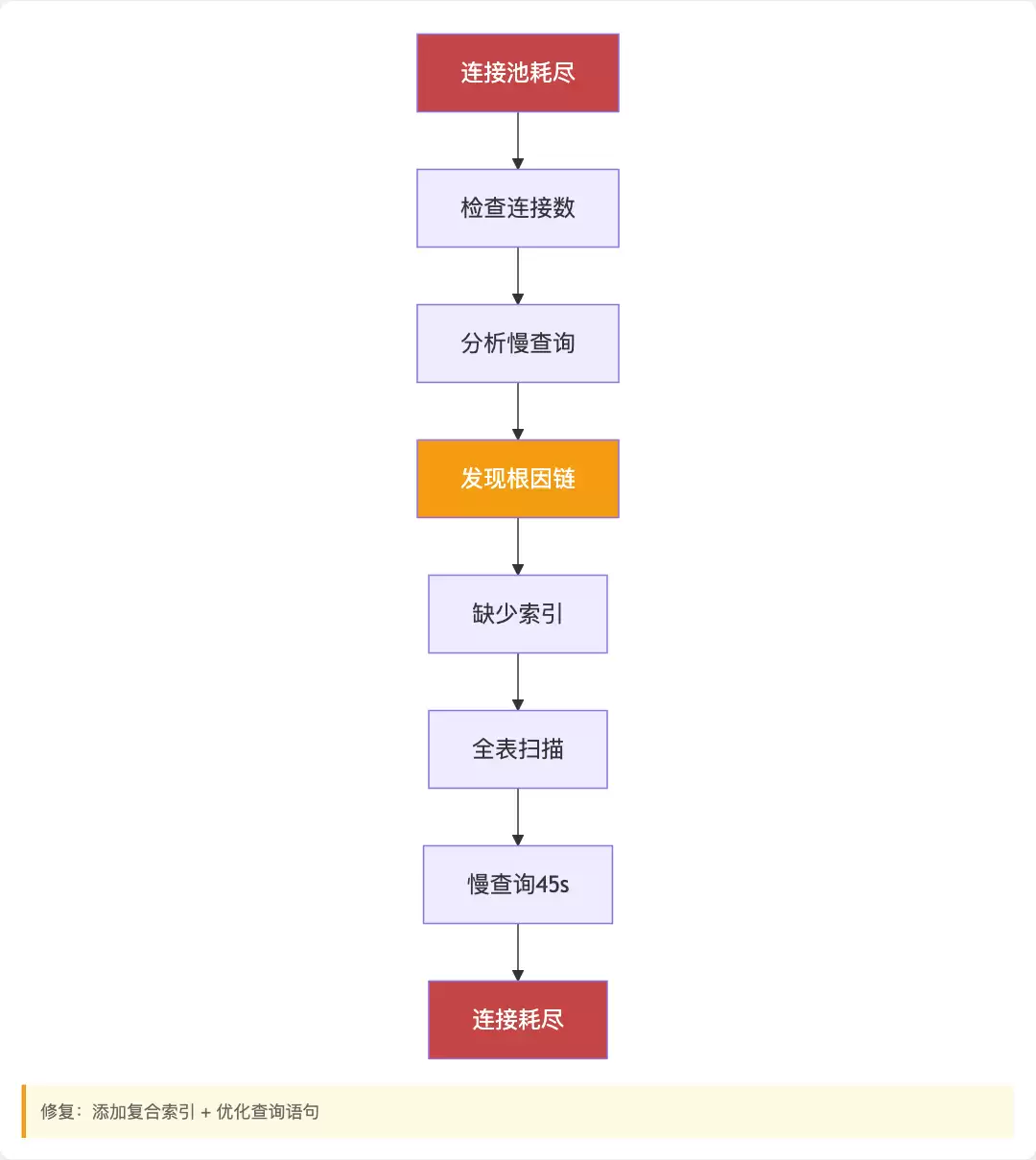
上午10:23,Agent检测到连接池告警。
Agent自动执行排查:
10:23:05 → 确认问题:连接数达到148/150,错误频率127次/10分钟。
10:23:12 → 检查数据库:执行SHOW PROCESSLIST,发现连接数接近上限。
10:23:18 → 分析来源:所有api-server实例都在占用连接。
10:23:25 → 检查慢查询:发现一个耗时45秒的慢查询,EXPLAIN显示为全表扫描。
Agent输出诊断报告。
人工确认后,Agent先执行紧急扩容,然后添加索引,最后验证连接数恢复正常。
整个过程耗时3分钟。(传统方式通常需要15到25分钟)
AI Agent 运维的核心优势
效率对比
指标 | 传统运维 | AI Agent | 提升 |
|---|---|---|---|
故障响应时间 | 5-15分钟 | 30秒-2分钟 | 5-10x |
故障定位时间 | 15-30分钟 | 2-5分钟 | 10x |
多告警处理 | 串行处理 | 并行处理 | 3-5x |
重复性工作 | 人工执行 | 自动执行 | 100x |
知识沉淀
传统方式有一个让人头疼的问题:运维A处理过某个故障 → 运维A离职了 → 知识随之丢失。下次遇到类似问题,又得从头查起。
Agent的方式则完全不同:处理过故障 → 记录到知识库 → 下次直接调取 → 持续积累。知识是沉淀的,不会因为人员变动而流失。
规模化能力
传统运维模式下,100台服务器需要10个人,1000台就需要100个人,几乎是线性增长。
而Agent运维模式下,100台服务器只需1个Agent实例,1000台还是1个Agent实例。边际成本趋近于零,这才是真正的规模化能力。
实施路径
 实施路径4阶段
实施路径4阶段
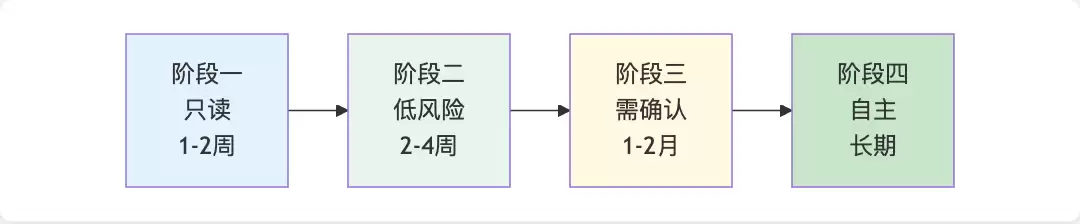
阶段一:只读模式(1-2周)——读取日志、检查配置、分析问题、提供建议。这个阶段的目标很简单:建立信任。让团队看到Agent的推断是可靠的。
阶段二:低风险操作(2-4周)——允许Agent执行重启Pod、清理缓存、小范围扩缩容等操作。目标是验证Agent在真实环境中的可靠性。
阶段三:需确认操作(1-2月)——Agent可以提出部署版本、修改配置、数据库变更等建议,但需要人工确认才能执行。这个阶段的核心是"人机协作"。
阶段四:自主运维(长期)——Agent自动处理P2/P3级别的问题、执行常规维护、完成自动扩缩容。最终目标是让Agent处理80%的日常运维工作。
结语
AI Agent运维的真正价值,并非要完全取代运维人员,而是构建一种全新的协作模式。
 人机协作分工
人机协作分工
运维的终极目标,可以理解为"智能协作"——让Agent处理那些它擅长的重复性、标准化工作,而让人真正聚焦于那些需要创造力和判断力的复杂决策。
技术的价值不在于它有多么先进,而在于它解决了什么问题。AI Agent运维,正以智能化的方式,解决运维领域最棘手的效率与稳定性难题。
延伸阅读
运维工具
这些工具值得关注:versus-incident(内置AI SRE的事件管理平台)、datadog-agent(监控Agent)、alertmanager(Prometheus告警管理)、CUA(Computer Use Agent基础设施)。
学习资源
如果想深入了解,可以看看微软的AI Agents for Beginners入门教程,以及PagerDuty的Incident Response事件响应最佳实践文档。
技术的价值不在于多么先进,而在于解决了什么问题。AI Agent 运维,正以智能化的方式,解决运维中最棘手的效率与稳定性难题。




