当 Andrej Karpathy 在播客里说出那句话时,Garry Tan 追问的却是另一件事:一个人怎么才能像一个 20 人团队那样持续交付?gstack 就是他的答案。
Garry Tan 现在是 Y Combinator 的 President & CEO,早年在 Palantir 做过工程、产品和设计,也联合创办过 Posterous,还做过 YC 内部社交网络 Bookface。在 gstack 的 README 里,他把自己最近一段时间的产出写得很重:
- 过去 60 天,
600,000行生产代码 - 其中约
35%是测试 - 每天
10,000–20,000行 - 同时还在全职运营 YC
这套说法当然带有很强的个人方法论宣传色彩,重点还是 Garry 给出的工作方式。README 里还举了另一个例子:Peter Steinberger 几乎独自用 AI agents 构建了 OpenClaw。按 GitHub API 在 2026-04-13 的查询,openclaw/openclaw 当时已经有 356,016 stars。
下面只抓一个核心问题:gstack 到底靠什么,把 Claude Code 从“能写代码的助手”推成“像一个虚拟工程团队”的工作流?
gstack 是什么
Garry 对它的定义非常直接:gstack 要把 Claude Code 变成一个虚拟工程团队。这句话对应的就是整个仓库的组织方式。
它把不同阶段的职责拆成一组 slash commands:
- 有人负责重新定义问题
- 有人负责锁架构和测试边界
- 有人负责设计审查
- 有人负责代码 review
- 有人负责打开真实浏览器做 QA
- 有人负责安全审计
- 也有人负责把 PR 发出去、等部署、再看生产健康
按照当前 README,这套仓库由 23 个 specialist roles 和 8 个 power tools 组成,全部以 Markdown 技能形式分发,开源协议是 MIT。
GitHub 数据
按 2026-04-13 查询到的 garrytan/gstack 仓库数据:
Stars:70,992Forks:9,987开源协议:MIT主语言:TypeScript创建时间:2026-03-11
这些数据本身也说明了一件事:gstack 在极短时间里就形成了话题和扩散。
Sprint 流程:思考 → 计划 → 构建 → 审查 → 测试 → 发布 → 复盘
理解 gstack,先看这句话:gstack is a process, not a collection of tools. 它把整个软件交付链条按 sprint 的顺序收成:Think → Plan → Build → Review → Test → Ship → Reflect,也就是:思考需求 → 形成计划 → 开始构建 → 做代码审查 → 进入真实测试 → 完成发布 → 最后复盘。
关键还在于前一个技能会把产物交给下一个技能。例如:
/office-hours写出的 design doc 会被/plan-ceo-review继续读/plan-eng-review产出的测试计划会被/qa继续使用/review找出的风险,会在/ship阶段继续被验证
gstack 和“装一堆提示词模板”之间的区别也在这里——它把软件团队里容易断掉的交接面,写成了明确流程。
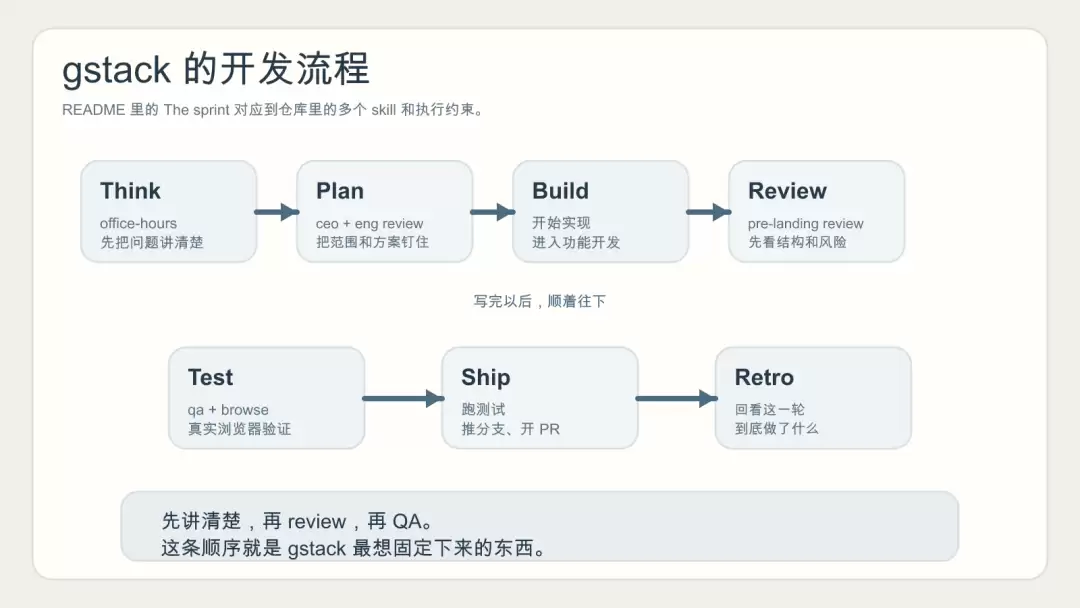 gstack 主流程图
gstack 主流程图
23 个专家角色,先看分工
23 个角色可以按几类分工来理解。
1. 规划角色
这一层负责把模糊需求压成可执行计划。
/office-hours用 6 个强制问题追问你的真实痛点、目标用户和隐藏前提,然后生成 design doc。/plan-ceo-review站在 CEO / founder 视角重新审需求,支持 Expansion、Selective Expansion、Hold Scope、Reduction 四种模式。/plan-eng-review从工程经理视角锁定架构、数据流、边界情况、测试矩阵和失败路径。/plan-design-review审设计本身,核心目标是揪出 AI slop 和模板化输出。/autoplan把 CEO → 设计 → 工程审查连成一条自动流水线。
2. 设计角色
这一层负责从“想法”走到“可交付界面”。
/design-consultation从零整理设计系统、风格方向和产品视觉语言。/design-shotgun一次生成多版视觉方案,放进浏览器里做对比,再根据反馈继续迭代。/design-html把选中的设计稿直接变成可交付 HTML/CSS。/design-review审完直接修,保留前后对比。
3. 构建与审查角色
这一层负责在“代码已经能跑”之后,把高风险问题揪出来。
/review找的是那种 CI 绿了但线上会炸的 bug,比如 SQL safety、LLM trust boundary、条件分支副作用。/investigate用系统化根因调试方法处理复杂问题,强调“没有调查,就没有修复”。/devex-review把开发者体验当成可测试对象,实际去走 onboarding、getting started 和文档路径。
4. QA 与安全角色
这一层把“写完”推进到“敢上线”。
/qa打开真实浏览器、点击流程、发现 bug、修 bug、重新验证,还会为修复补回归测试。/qa-only保留相同 QA 方法,但只出报告,不改代码。/cso用 OWASP Top 10 和 STRIDE 做安全审计,强调低误报和高置信度。
5. 发布与辅助角色
这一层把交付继续往上线推进。
/ship同步主分支、跑测试、看覆盖率、推送、开 PR。/land-and-deploy从“PR 已批准”一路做到“生产已验证”。/canary发布后继续盯性能、控制台报错和页面失败。/benchmark对比前后 Core Web Vitals 和资源体积。/document-release自动更新 README 和其他文档,防止代码发了、文档没跟上。/retro做按团队节奏组织的周期复盘。/learn管跨会话记忆,累积项目模式、坑点和偏好。
6. Power tools
power tools 的作用是给这套流程加护栏和额外能力。
/codex用 OpenAI Codex CLI 做第二意见审查。/careful在破坏性命令前弹安全警告。/freeze把修改范围锁定在一个目录。/guard—/careful+/freeze组合。/unfreeze解开编辑边界。/open-gstack-browser启动 GStack Browser。/setup-deploy为/land-and-deploy做部署配置。/gstack-upgrade升级 gstack 到最新版本。
这套角色和工具叠在一起,最后得到的是一套团队分工模型。
 gstack 的命令分层
gstack 的命令分层
几个关键能力
1. /qa:把真实浏览器拉进工作流
这是 gstack 里很显眼的一项能力。/qa 直接去:打开真实 Chromium,实际点页面,发现真实交互 bug,修复以后再跑一遍,顺手补回归测试。当 Agent 能直接看到坏掉的页面、点到错误的交互、修完再验证,它的工作边界就从代码编辑器扩到真实产品了。
2. /design-shotgun + /design-html:把视觉迭代接到工程输出
传统 AI 原型流程的问题是:你用文字描述愿景,然后赌模型理解对了。gstack 这里的流程接近真实设计评审:先生成 4-6 个变体,在浏览器中并排比较,选方向、给反馈、继续迭代,选定后再交给 /design-html,输出接近可发布状态的 HTML/CSS。这套链路把“想法到界面”接成了一条完整流程,直接连到工程输出。
3. 智能审查路由
README 对这一点的解释是按分工来路由审查:CEO 不必看基础设施 bug,设计审查不必覆盖纯后端改动,不同变更需要不同审查组合。gstack 不默认每次都全角色齐上,它会试图判断当前改动更适合哪类审查。
4. 把测试覆盖率和回归测试写进流程
gstack 对测试的态度很硬:/ship 会审覆盖率,如果项目还没测试框架,会尝试引导你补起来;/qa 发现并修复 bug 后会顺手补回归测试。这让“vibe coding”从纯速度导向,开始往“可回归、可持续交付”收。
5. /codex:跨模型第二意见
当 /review 用 Claude 看过一遍 diff,/codex 再用 OpenAI Codex CLI 独立看一遍时,你得到的是一份交叉审查结果:哪些问题两个模型都看到了,哪些是 Claude 才看到的,哪些是 Codex 才指出来的。这和真实团队里的交叉审查相似。
6. /pair-agent:多 Agent 协调
/pair-agent 解决的是另一个问题:如果你同时跑多个不同供应商的 Agent,怎么让它们共享同一个浏览器环境,在同一套上下文里协作?它的做法是让多个 Agent 通过同一个 GStack Browser 协调工作,各自拥有隔离标签页。这类设计适合多 Agent 协作。
实际使用示例:8 条命令跑完一条闭环
下面这条链路,基本就是 gstack 想推广的工作方式。
- 你说:我想做一个日历每日简报应用
- 运行
/office-hours - 系统先追问你的真实痛点和替代方案
- 它把“daily briefing app”重新解释成“personal chief of staff AI”
- 运行
/plan-ceo-review - 再运行
/plan-eng-review - 计划批准后开始实现
- 跑
/review - 跑
/qa https://staging... - 最后跑
/ship
在 README 的示例里,这条链能走到:先有设计文档,再有 CEO 审查,再有工程审查,再进入实现,再做代码 review,再做真实浏览器 QA,最后产出 PR。README 想强调的是这条链路覆盖了从需求到 PR 的完整分工。
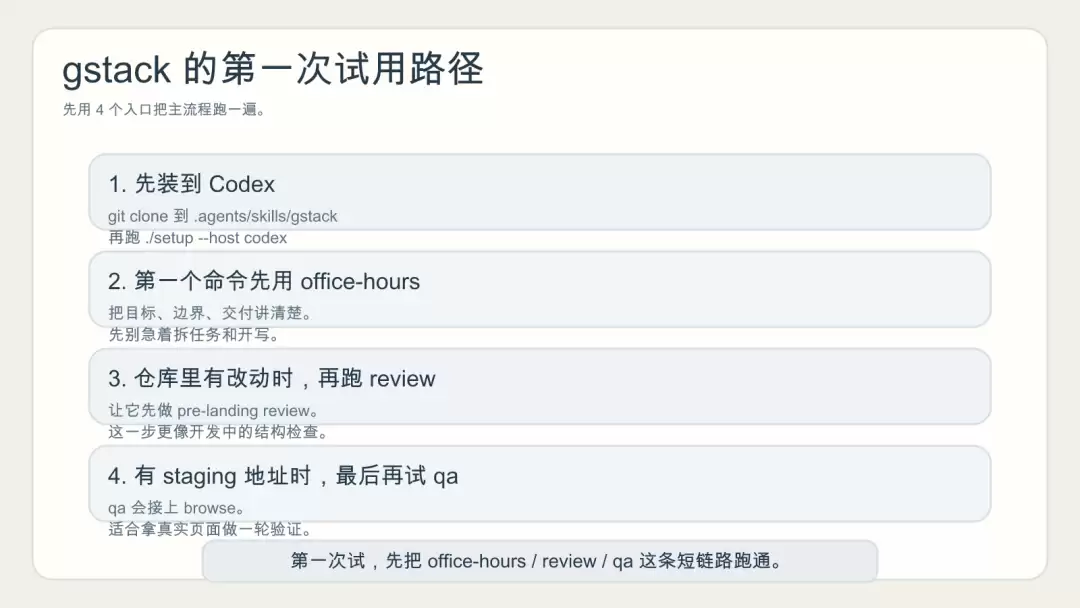 gstack 的最短试用路径
gstack 的最短试用路径
安装:30 秒起步
按当前 README,最简单的安装要求是:Claude Code、Git、Bun v1.0+,Windows 额外需要 Node.js。
Claude Code 安装命令
git clone --single-branch --depth 1 https://github.com/garrytan/gstack.git ~/.claude/skills/gstack
cd ~/.claude/skills/gstack
./setup
其他 AI 编程 Agent
gstack 当前明确支持 8 类 AI coding agents。README 里列出的典型宿主包括:
Claude Code— 全局安装到~/.claude/skills/gstackOpenAI Codex CLI— 用./setup --host codexOpenCode— 用./setup --host opencodeCursor— 用./setup --host cursorFactory Droid— 用./setup --host factorySlate— 用./setup --host slateKiro— 用./setup --host kiroOpenClaw— 通过 ACP 与 Claude Code 侧接入
想先判断它适不适合自己,README 给出的最短试用路径很简单:安装 → 跑 /office-hours → 跑 /plan-ceo-review → 在有代码改动的分支上跑 /review → 手上有 staging URL 时跑 /qa。
并行 Sprint:为什么它适合多 Agent
gstack 还有一个特点:它不只适合单线程。README 里直接把这个场景写成:一个会话跑 /office-hours,一个会话跑 /review,一个会话做实现,一个会话在 staging 跑 /qa,其他会话在别的分支继续推进。Garry 自己把这种模式描述成 10-15 个并行 sprint。
这种并行能成立,原因在于 sprint 结构先被固定了。没有流程时,10 个 Agent 是 10 个混乱源。有了 Think → Plan → Build → Review → Test → Ship 这条顺序后,每个 Agent 才知道自己现在该做什么、该在什么时候停。
隐私与遥测
这部分也值得单独提一下。按当前 README,gstack 的 telemetry 是:默认关闭,首次运行才会询问是否开启;开启后发送的只包括技能名、耗时、成功/失败、gstack 版本、操作系统;不发送代码、文件路径、仓库名、分支名、提示词和用户内容。随时可以用下面这条命令关闭:gstack-config set telemetry off。
总结
gstack 的关键在于它试图把一个软件团队的节奏写进 Agent 工作流。它把下面这些原本容易散掉的东西重新拢到一起:产品定义、范围控制、工程审查、设计迭代、浏览器 QA、安全审计、发布与文档更新。
如果你只是想让 Agent 帮你快一点写一个函数,gstack 会显得很重。但如果你关心的是:一个人怎么借助 Agent,把从想法到上线的整条链条收成团队级交付流程,它给出了一套完整的答案。gstack 开源的是一整套 AI 时代的软件工厂组织方式。
Sources
garrytan/gstackGitHub READMEgarrytan/gstackGitHub APIopenclaw/openclawGitHub API- Fortune / No Priors 中 Andrej Karpathy 的引述(经 gstack README 引用)




