你有没有好奇过,为什么 Claude Code 或 Codex CLI 用起来,比在聊天界面直接调用同一个模型要强大得多?
很多人直觉上会觉得,这是“模型更强”或“做了特殊优化”。但 Sebastian Raschka 博士的最新文章点出了关键:真正的差异在于 Agent Harness——那个围绕模型的软件框架。
Raschka 是《Build a Large Language Model From Scratch》和《Build a Reasoning Model From Scratch》的作者。这篇文章把编程 Agent 的核心架构拆解得相当清晰,特别适合用来理解 Claude Code、Codex CLI 这类工具到底是怎么工作的。
一、核心概念:LLM、推理模型与 Agent
在深入技术细节之前,先理清几个容易混淆的概念。
1. LLM(大语言模型)
这是最底层的“下一词预测”引擎,是所有智能体系统的发动机。
2. 推理模型
推理模型本质上还是 LLM,但经过特殊训练,在推理时会投入更多计算资源进行中间推理、验证和搜索。你可以把它理解成升级版引擎——更强,也更贵。
3. Agent(智能体)
Agent 是架在模型之上的控制层。给定目标后,它需要决定:下一步检查什么?调用哪些工具?如何更新状态?何时停止?
4. Agent Harness
这是围绕 Agent 的软件脚手架,负责管理上下文、工具使用、提示词、状态和控制流。
5. Coding Harness
Agent Harness 的特化版本,专门针对软件工程任务——管理代码上下文、工具、执行和迭代反馈。
 概念关系图
概念关系图
二、一个形象的比喻
Raschka 用了一个相当直观的比喻:
LLM就像汽车引擎推理模型就是升级版引擎,更强但更耗油Agent Harness则像是驾驶系统,帮你把车真正开起来
这个比喻不算完美——LLM 也可以独立使用——但它抓住了核心:模型决定“能跑多快”,Harness 决定“能开多远”。
更重要的是,在各大模型能力逐渐拉近的今天,Harness 往往成为体验差异的决定性因素。Raschka 甚至推测,如果把 GLM-5 放进类似 Claude Code 的 Harness 里,它的实际体验很可能不输给 GPT-5.4。
三、编程 Agent 的六大核心组件
Raschka 把编程 Agent 拆解为六个核心组件:
 六大组件总览
六大组件总览
组件一:实时代码库上下文
这是最显而易见,也最关键的一层。
当用户说“修复测试”时,模型需要知道:这是不是一个 Git 仓库?当前在哪个分支?项目有什么结构?有没有 AGENTS.md 或 README 说明?
为什么这么重要?因为“修复测试”不是一个自包含的指令。如果 Agent 看到了项目文档,就能知道该运行哪个测试命令;如果了解了仓库布局,就能在正确的位置查找,而不是盲目猜测。
实现要点通常是:在开始工作前先收集一组稳定事实,包含 Git 状态、分支、最近提交,而且这些信息不需要每次都从零重建。
组件二:提示词形状与缓存复用
编程会话往往是重复性的:Agent 规则基本不变,工具描述基本不变,工作区摘要基本不变。真正在变的,主要是用户请求、对话历史和短期记忆。
聪明的设计不会每次都重建一个巨大的提示词。
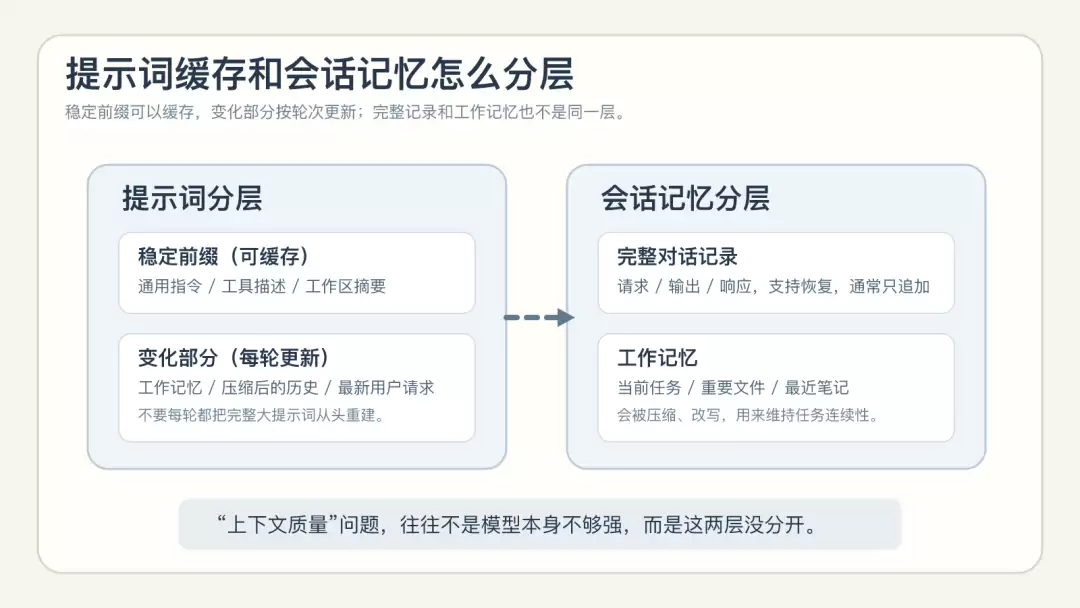 提示词与记忆分层
提示词与记忆分层
核心洞见在于:收集仓库事实,和打包缓存事实,是两个独立的步骤。
组件三:工具访问与使用
这是从“聊天”变成“智能体”的关键一步。
普通模型只能用自然语言给你建议命令,而编程 Agent 会实际执行命令、获取结果,并将结果反馈到下一轮推理中。
当然,也不是让模型完全放飞。实际流程更接近这样:
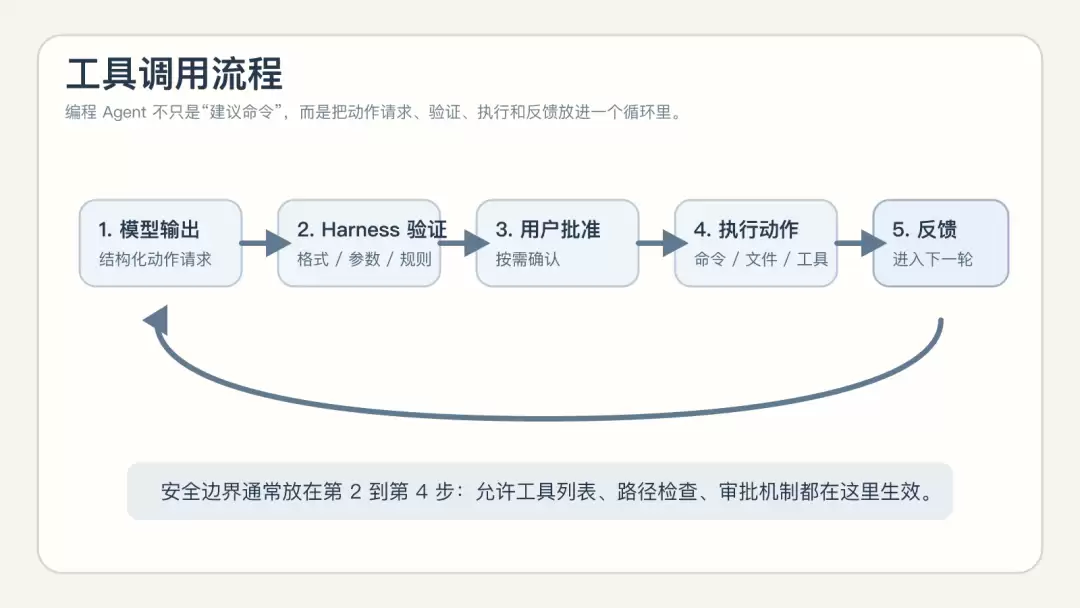 工具调用流程
工具调用流程
安全边界一般包括:预定义的允许工具列表、路径检查(只在仓库内操作)、用户审批机制。这些看似限制的规则,实际上是提高可靠性和可用性的关键。
组件四:最小化上下文膨胀
上下文膨胀是 LLM 的通病,而编程 Agent 尤其容易遇到:重复的文件读取、冗长的工具输出、大量的日志信息……如果保留所有内容,上下文窗口很快就会被耗尽。
这里有两种核心压缩策略:
- 截断:缩短长文档、截断大输出、压缩记忆笔记
- 对话压缩:将历史转为摘要,保持最近事件更详细
额外技巧还包括:对旧文件读取去重,避免重复看到同一内容;保持最近事件更详细;对旧事件做更激进的压缩。
原文有一句话很值得记住:很多看似模型能力的问题,本质上其实是上下文质量问题。
组件五:结构化会话记忆
这一层与上一组件紧密相关,但关注点不同。
 压缩对话历史与工作记忆
压缩对话历史与工作记忆
两层状态管理可以概括为:
- 完整对话记录:存储所有请求、输出、响应,只追加,不修改,支持会话恢复
- 工作记忆:小型、精炼的状态,记录当前任务、重要文件、最近笔记,会被修改和压缩
组件六:委托与有界子智能体
为什么要委托?原因很实际:并行化子任务,避免单一循环承载所有工作——比如查找符号、检查配置、诊断测试失败。
核心挑战是如何绑定子智能体。子智能体需要继承足够的上下文才能工作,但同时必须有边界:
- 只读模式:子智能体不能修改文件
- 递归深度:限制子智能体再启动子智能体
- 工作范围:限制操作的目录或文件
原文对这一点的总结很到位:继承足够上下文才能有用,但必须设置约束边界防止失控。
四、完整架构总览
把这六个组件整合起来,大致是这样一个分层结构:
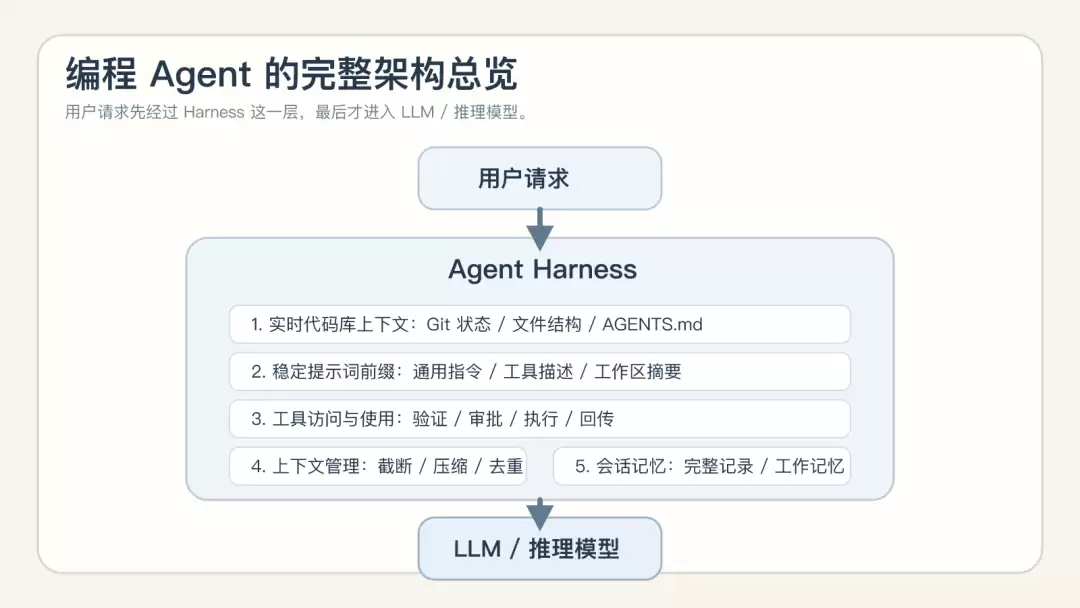 完整架构图
完整架构图
这张总览图最重要的信息在于:它把 harness 放在了模型外面整整一层。也就是说,用户请求不是直接扔给模型,而是先经过代码库上下文、稳定提示词前缀、工具访问与使用、上下文管理、会话记忆、子智能体委托,最后才会进入 LLM 或推理模型。
五、编程 Agent vs 通用 Agent 平台
Raschka 还对比了编程 Agent(如 Claude Code)与通用 Agent 平台(如 OpenClaw):
 编程 Agent 与通用 Agent 平台
编程 Agent 与通用 Agent 平台
核心差异在于:编程 Agent 优化的是“一个人在仓库中工作”的场景,而 OpenClaw 优化的是“跨多个聊天、通道、工作区运行多个长期 Agent”。编程只是其中一种工作负载。
六、核心洞见总结
1. 模型不是全部
在很多实际应用中,围绕模型的系统和模型本身同样重要。这也是为什么同一个模型放进 Claude Code 后,体验会和聊天界面相差甚远。
2. Harness 是差异化因素
在模型能力逐渐拉近的背景下,Agent Harness 往往就是体验差异的来源。一个设计良好的 Harness,能让模型的能力更稳定地释放出来。
3. 上下文质量 = 模型表现
很多看起来像模型能力的问题,最后都会落到上下文质量上。
4. 边界即自由
预定义工具、路径检查、审批机制——这些边界看起来像限制,实际上却能提高可靠性和实用性。
七、实践建议
如果你想构建自己的编程 Agent,或者想更深入地理解现有系统:
- 从最小实现开始
- 重视上下文管理
- 工具设计要有边界
- 会话记忆要分层
- 提示词缓存尽量复用




