最近调研了不少 Agent 项目,发现一个颇有意思的现象:许多自称 multi-agent 的应用,实际上不过是将一个大任务拆解给几个“角色”,让它们在同一个会话中轮流发言。
这种设计确实能体现出“分工”的感觉,但离真正的团队协作,仍有不小的差距。
一个真实的团队,至少需要满足三个要素:
• 拥有清晰的角色定义
• 具备共享的决策机制
• 能够跨会话保留工作记忆
在深度体验了 bradygaster/squad 之后,最大的感触是:它的目标并非“再包装一个多 Agent 对话系统”,而是将 GitHub Copilot 打造成一支真正扎根在仓库里的开发团队。
它的关键词不是聊天、提示词或编排演示,而是:把团队状态写入仓库,把协作规则存进文件,让后续所有会话都建立在这套文件之上。
先说结论:Squad 最值得关注的,不是 Agent 数量,而是 .squad/ 目录
Squad 的定位写得很清晰:
这句话里,最关键的其实不是“One command”,而是后半句:A team that grows with your code。
翻译成大白话就是:它不希望每次你都重新开启一个“智能体会话”,而是希望这支团队能与你的仓库共同演进。
这也是它与许多以“多角色分工”为卖点的 Agent 项目相比,更具特色的地方:
• 它最自然的入口是 GitHub Copilot
• 它会把团队结构写入 .squad/ 目录
• 它将决策、历史、技能、路由全部落地为文件
• 它假设你会把这些文件一并提交进 Git
README 里甚至明确写到:.squad/ 应该提交到版本库。
这已经不是“聊天助手”的思路了,而是“将 Agent 组织结构视为项目资产”的思路。
最快验证路径
这类项目最怕一件事:概念宏大,第一次上手却看不到真实效果。
Squad 在这方面做得比较克制。它在文档里给出了一条非常简短的验证路径,你可以先完全不了解内部架构,看看它是否真的会把“团队”写进仓库。
这里有一个细节需要注意:
• 根 README 采用全局安装方式:npm install -g @bradygaster/squad-cli 然后直接 squad init
• five-minute-start 则采用项目内安装:npm install --save-dev @bradygaster/squad-cli 然后 npx squad init
如果只是首次尝试,更推荐走第二条路径。它对当前项目更友好,也方便将这次验证记录留在仓库里。
如果你的 GitHub CLI 尚未登录,先执行一次:
gh auth login
最短验证路径大致如下:
npm install --save-dev @bradygaster/squad-cli
npx squad init
ls .squad/
npx squad status
gh auth status
如果想先看一眼安装完成后的实际界面,可以参考这张截图:
 Squad 安装完毕后的真实界面展示
Squad 安装完毕后的真实界面展示
继续往下推进,README 里给出的 GitHub Copilot 启动命令为:
copilot --agent squad --yolo
这条路径最值得留意的,不是命令本身,而是验证信号:
1. npx squad init 之后,仓库中会出现 .squad/ 目录
2. .squad/ 并非空目录,而是包含 team.md、routing.md、decisions.md、agents/ 等团队文件
3. 再将项目描述交给 Copilot / Squad,它通常会先给出 team member proposals;你确认后,它们才开始执行
这一步至关重要,因为它将“Agent 团队”从抽象概念,变成了你可以在仓库中实际触摸到的内容。
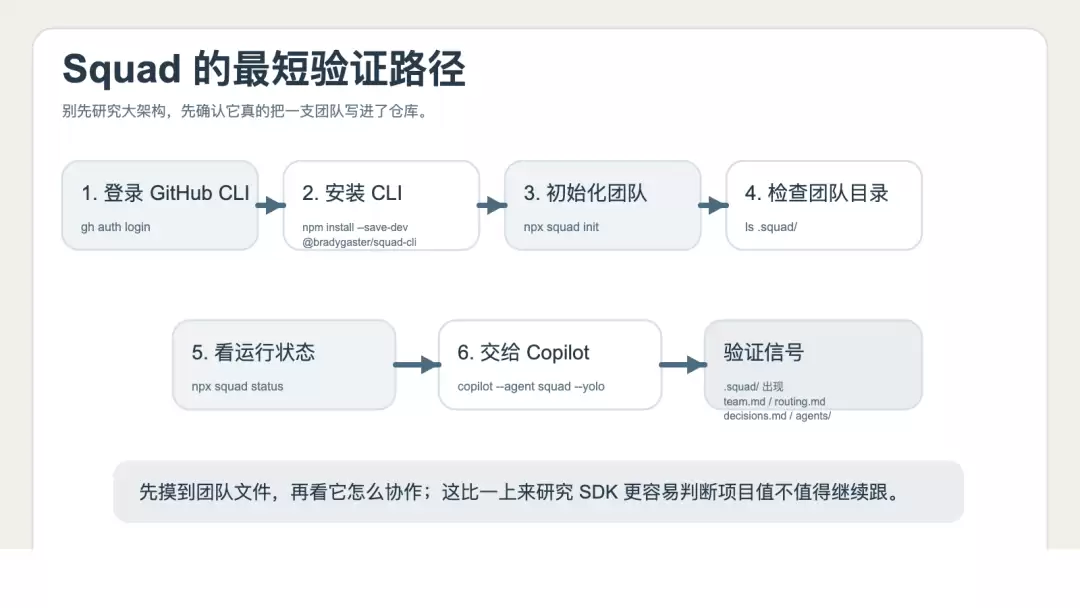 Squad 最简验证流程示意图
Squad 最简验证流程示意图
第一次到底怎么用
前面那条路径解决的是“它有没有安装成功”的问题。但真正决定你是否会继续使用它的,是安装完成后第一轮该如何开口。
README 里给出的第一轮话术,已经非常贴近实际用法了。你可以直接这样开始:
I'm starting a new project. Set up the team.
Here's what I'm building: a recipe sharing app with React and Node.
这句话的作用,不是让 Squad 立刻写代码,而是先让它做两件事:
1. 根据你的项目描述提出 team member proposals
2. 将这些角色写入 .squad/agents/ 和相关团队文件
也就是说,第一轮更像是“组队”,而不是“开工”。
等它给出团队提案,你确认之后,再下第一条真正的任务会更合适。 README 中的示例是:
Team, create a basic Express server with a /health endpoint.
如果想用更贴近日常开发的话语,也可以这样下达:
• Team, build the login page
• Team, implement the first API route
• Team, analyze this project's architecture
它的思路不是“你点名某个 Agent 干活”,而是你先把目标交给团队,再由协调者决定如何分发。
如果想先确认自己是否真正切换到了 Squad agent,可以查看类似这样的界面:
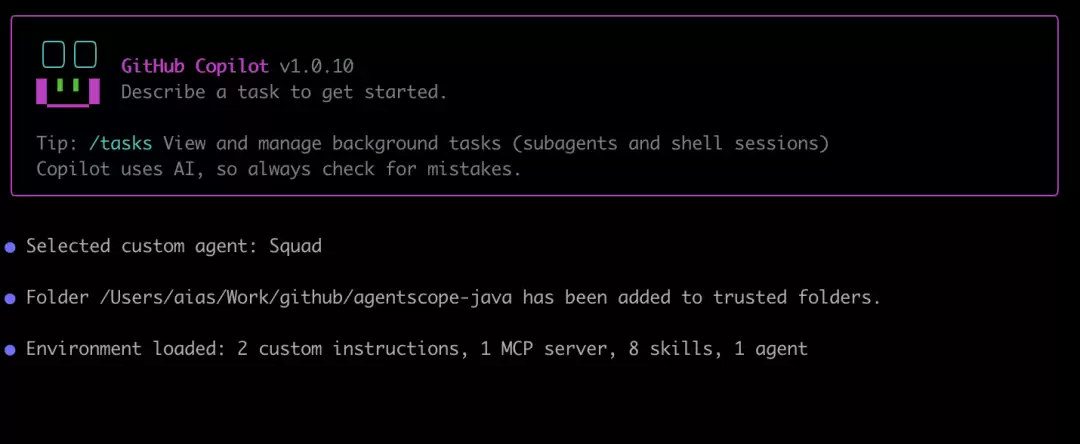 Copilot 已成功切换到 Squad agent 的界面
Copilot 已成功切换到 Squad agent 的界面
再进一步,如果 Copilot 终端里已经明确显示 "Selected custom agent: Squad",那就说明入口已经切换正确,接下来就可以将项目描述真正交给它了:
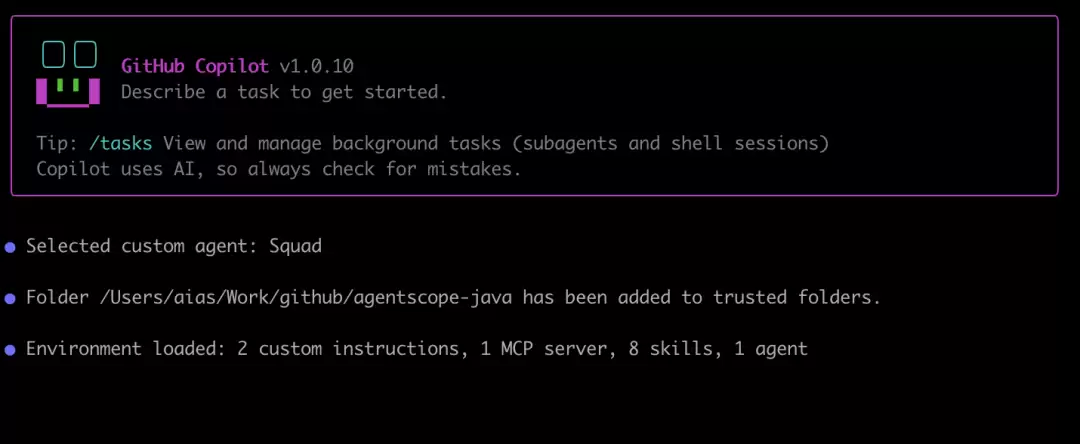 Copilot 中已选中 Squad agent 的效果
Copilot 中已选中 Squad agent 的效果
用起来之后,最该看哪几个反馈点
很多人第一次试用这类项目,会一直盯着聊天窗口。但 Squad 真正有信息量的反馈,其实不只在对话中。
第一轮任务跑完后,建议重点查看以下 4 个地方:
1. team.md:看这支团队最终如何组建,角色是否与你当前项目所需分工匹配。
2. routing.md:看任务路由规则是否合理,后续哪些工作可能会被分配给谁。
3. decisions.md:看它是否真的把关键决策记录下来,而不仅是在聊天中说过就完。
4. agents/{name}/history.md:看某个 Agent 是否开始积累自己的项目记忆。
如果这 4 个位置仍然是空的、混乱的、或者只是模板,那说明它还没有真正进入“团队工作”状态。如果这些文件已经开始与你的真实项目绑定,Squad 才算真正开始发挥作用。
不想每次都重新输入一串命令,可以直接进入 Shell
README 中还有一个很实用但容易被忽略的入口:squad shell
你可以直接输入:
squad
进入后会看到:
squad >
这时候你就不再是运行单个命令,而是与整支团队进行持续对话。
比较实用的几个 shell 命令包括:
• /status:查看当前团队状态
• /agents:查看现有成员
• /history:查看最近消息
• /sessions:查看保存下来的会话
• /resume :恢复旧会话
真正下任务时,你有两种方式:
1. 直接对整个团队说话,例如:Build the login page
2. 明确点名某个 Agent,例如:@Keaton, analyze the architecture of this project
这也是它与普通 CLI 工具不太一样的地方:它不是执行一条命令就结束,而是在仓库中维持一个持续工作的团队上下文。
.squad/ 才是 Squad 的真正核心
README 中给出的 .squad/ 结构非常值得研究:
• team.md
• routing.md
• decisions.md
• ceremonies.md
• casting/
• agents/{name}/charter.md
• agents/{name}/history.md
• skills/
• identity/now.md
• identity/wisdom.md
• log/
如果把这些文件翻译成更工程化的表述,它们大致对应:
• team.md:这支团队包含哪些角色
• routing.md:什么任务应该分配给谁
• decisions.md:全体共享的项目决策
• agents/*/charter.md:每个 Agent 的职责边界
• agents/*/history.md:每个 Agent 自己的工作记忆
• skills/:团队掌握的能力
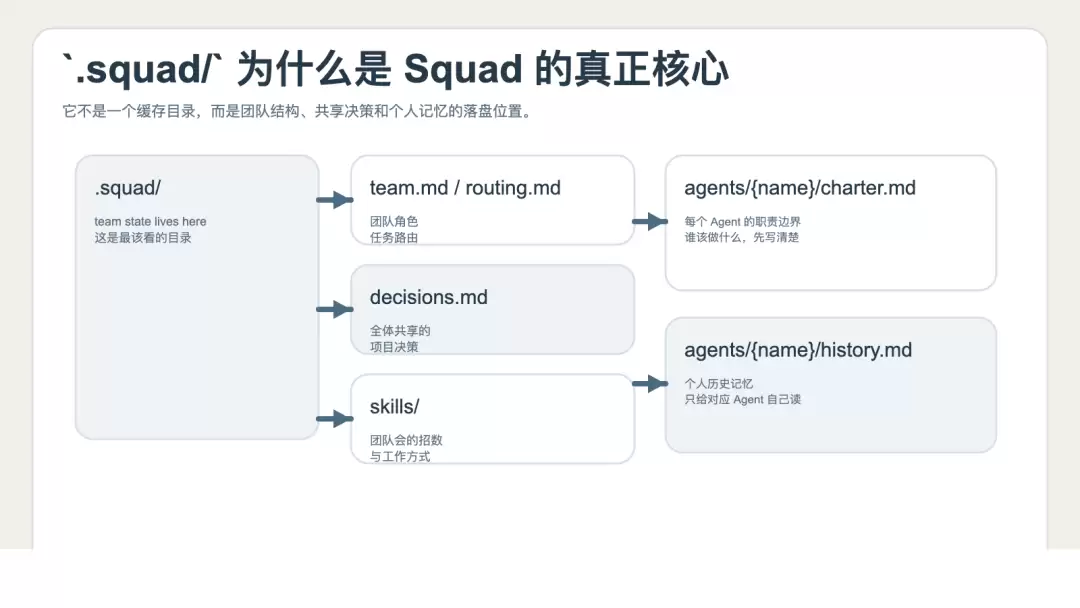 .squad 目录结构图示
.squad 目录结构图示
这里最聪明的一点,是它将“共享记忆”和“个人记忆”区分开来。
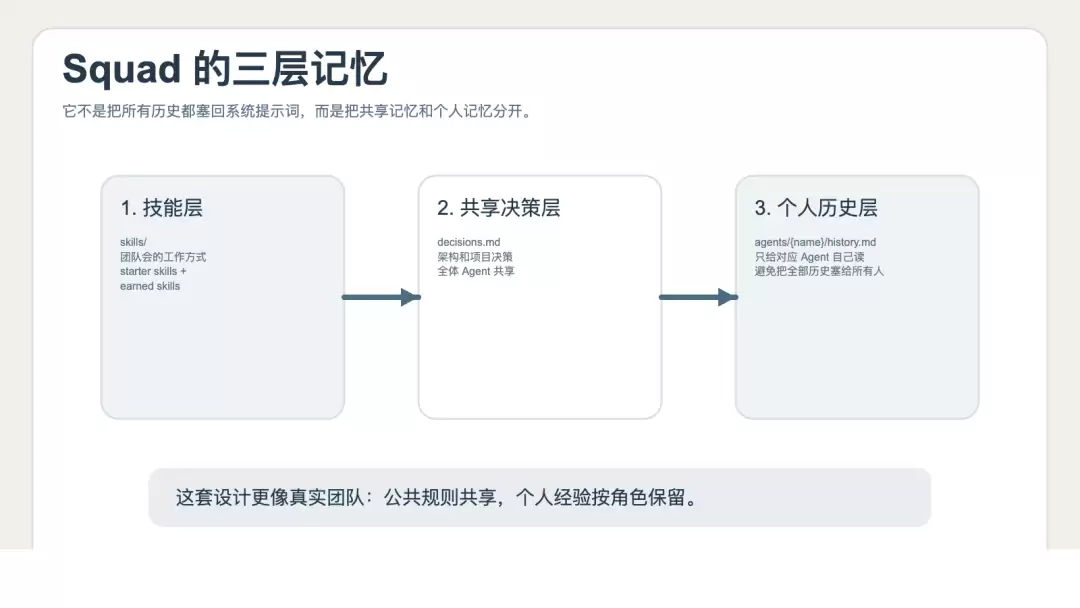
在 memory-and-knowledge 文档中,Squad 明确把记忆拆分为三层:
1. 技能层:skills/
2. 共享决策层:decisions.md
3. 个人历史层:agents/{name}/history.md
而且它还规定:
• decisions.md 是所有 Agent 共享的
• history.md 只有对应 Agent 自己会读取
 Squad 三层记忆结构图解
Squad 三层记忆结构图解
这套设计很像真实团队:架构决策是大家都要遵守的,但某个成员自己的经验积累,不需要强行塞给所有人。这比“把所有历史都塞回系统提示词”要清晰得多,也更容易持久化。
它为什么不像普通的“多角色对话”
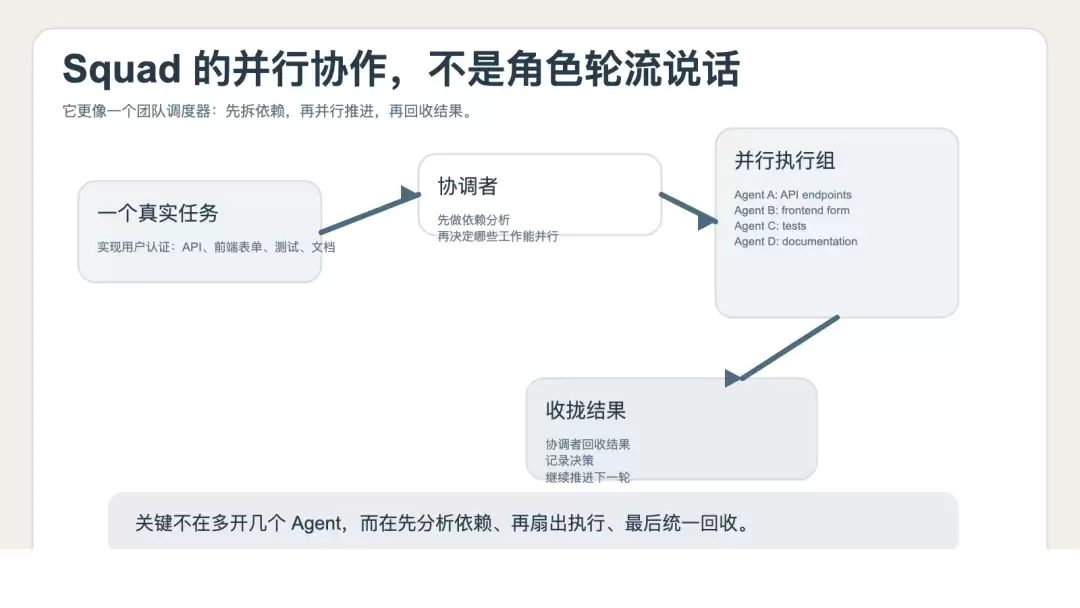
Squad 还有一个很值得关注的点:它把“并行工作”写成了默认行为,而不是演示功能。
在 parallel-work 文档中,它讲得很明确:Squad 默认会并行启动独立工作。
文档里的示例任务可以自行参考。它的处理方式不是让一个 Agent 从头做到尾,而是由协调者去分析任务,将其拆解为可以并行推进的几块,然后再把结果汇总回来。
这个思路的价值在于:
• 不是简单地“多开几个 Agent”
• 而是先做依赖分析,再决定哪些工作可以扇出
• 再由协调层负责汇总和回收
 Squad 并行协作工作流示意图
Squad 并行协作工作流示意图
这才像一个真正的团队调度器。如果只是在一个上下文里让几个人轮流讲话,你得到的往往是“表面分工”。而像 Squad 这样,把角色、路由、决策、日志都落到仓库里,再配上协调者做扇出和汇总,你才开始接近“工程团队”的味道。
Squad 最值得学习的,不是命令,而是它对“长期协作”的理解
这类项目最容易被误读的地方,是大家会把注意力放在命令数量上。
当前 README 中已经列出十多个命令,里面有一些一眼就透着“团队化”的名字:
• squad init
• squad status
• squad triage
• squad doctor
• squad shell
• squad export
• squad import
• squad plugin marketplace ...
• squad upstream ...
• squad nap
• squad aspire
这些命令当然重要,但它们不是这个项目最核心的部分。
更值得注意的是:Squad 在试图回答一个很多 Agent 工具都没有认真回答的问题——如果一个 AI 团队要在同一个仓库里连续工作很多天,它的记忆、分工、决策和恢复机制应该放在哪里?
Squad 的答案是:不放在一次性会话里,不放在一段巨长的系统提示词里,而是放在 repo 里的结构化文件中。
这也是为什么它后来会继续向前长出这些能力。
从 changelog 来看,0.9.0 这一轮新增的许多能力,都不是“让单个 Agent 更聪明”,而是明显偏向团队运行层:
• Personal Squad governance layer
• Worktree spawning & orchestration
• Cross-squad orchestration
• Persistent Ralph
• Cooperative rate limiting
• Economy mode
• Session recovery skill
• token usage visibility
这些名称看起来五花八门,但方向是一致的:它在补充一支 AI 团队长期运行时真正会遇到的问题。
例如:如何在不同的工作区中隔离任务、如何跨 squad 协作、如何控制额度和成本、如何从中断的会话里恢复、如何查看 token 用量。这说明它已经不满足于“能跑一个 demo”,而是在往“能长期驻场”那个方向推进。
这项目为什么值得继续关注
squad 值得关注的原因,不是它已经成熟到可以无脑上生产,而是它把一个很重要的方向说清楚了:下一代 AI 编程工具,可能不只是更强的单兵助手,而是能在仓库里形成组织结构的协作系统。
尤其是它与 GitHub Copilot 的结合方式,极具代表性。很多项目自己做一整套入口,要求你改变工作方式。Squad 的做法则是尽量贴着现有的 Copilot 使用习惯,把“团队层”叠加上去。这使它更像一个真实工作流的扩展,而不是一个完全平行的新工具。
但也要看清楚它当前存在的边界
这篇文章如果只讲优点,会有点不诚实。Squad 现在最需要一起看到的,是它的野心和它的边界。
先说边界:
1. 它还处于 alpha 阶段。README 和 quick start 都明确写了 "Experimental" / "alpha software"。这意味着命令、API、行为都可能继续变化。
2. 文档里的环境要求还不完全一致。five-minute-start 写的是 "Node.js 20+",但仓库根 package.json 和 CLI / SDK 包里的 engines 写的是 ">=22.5.0"。这类不一致本身就说明项目还在快速迭代期,上手时最好按更保守的高版本 Node 来准备环境。
3. 它目前明显依赖 GitHub Copilot 生态。这不是一个完全中立的“任意模型 runtime”。它现在最自然的使用方式,仍然是挂在 GitHub Copilot 上。
4. SDK-first 还不是最稳的主线路。README 已经明确说了,SDK-first mode 还是实验性的,而 markdown-first 仍然是默认、也是更稳妥的路径。
这四点不一定是坏事,但它们决定了一个更准确的判断:Squad 现在更像一个值得认真跟进的新方向,而不是一个已经打磨完毕的团队操作系统。
建议的深入阅读顺序
如果最近只想挑一个 Agent 仓库深入研读,可以将 Squad 放进候选名单。
不是因为它的 stars 最多,也不是因为它 slogan 最响。而是因为它触及了一个非常真实的问题:当 AI 编程从“单轮回答”进入“持续驻场”,你迟早要处理这些事情:
• 谁负责什么
• 哪些决策要共享
• 哪些经验只属于某个 Agent
• 并行工作怎么调度
• 会话中断后如何恢复
• 这些状态到底存放在哪里
Squad 不是第一个谈论这些问题的项目,但它是少数把答案落成了仓库结构和 CLI 约定的项目。
因此如果今天去阅读它,最建议的顺序不是从源码深处开始,而是:
1. 先读 README,确认它想解决的问题
2. 再走一遍 npx squad init -> ls .squad/ -> npx squad status
3. 然后重点看 .squad/ 目录结构
4. 再看 parallel-work 和 memory-and-knowledge
5. 最后才去看 changelog 和 SDK
因为真正让这个项目有辨识度的,不是它“有几个 Agent”,而是它开始认真回答:一支 AI 开发团队,应该怎样在一个仓库里留下长期可继承的协作痕迹。
仓库信息
仓库名:bradygaster/squad
截至 2026 年 3 月 26 日,GitHub 仓库页大约显示:
• 1.4k+ stars
• 180+ forks
当前公开信息里比较值得一起阅读的文件有:
• README.md
• five-minute-start.md —— 这篇是最快的上手入口,先看它如何跑通第一轮验证。
• parallel-work.md —— 这篇专门解释协调者如何并行派工、回收结果。
• memory-and-knowledge.md —— 这篇最适合用来理解三层记忆和 .squad/ 持久化。
• CHANGELOG.md —— 用来判断这个项目最近几个月重点在补充哪些能力。
• package.json —— 用来核对 Node 版本要求、monorepo 入口和脚本布局。
如果准备自己尝试,建议优先按更保守的环境预期来:Git 仓库、GitHub CLI 已登录、Node.js 高版本、GitHub Copilot 可用。




