AI Agent模型的推理能力持续增强,这是事实。然而,其输入的信息依然来源于传统为人类视觉设计的搜索系统——金融数据、法律文书、学术引用、安全威胁情报等。这些完成专业任务所必需的高质量数据,大多未被常规搜索引擎有效覆盖。正是这些隐藏在日常开发工作中的痛点,导致Agent与AI工作流在执行复杂任务时,常常需要多次搜索。更严重的是,更新滞后、来源不可靠的低质量信息,往往将后续推理引向错误的方向。
针对这一挑战,一家初创企业发布了专为AI Agent设计的搜索层服务——AnySearch。该产品于5月11日正式上线,上线首月即吸引全球超过10万名开发者接入使用,累计搜索调用量突破400万次,GitHub Star数超过4000。来自亚太、北美、欧洲等多个地区的开发者,已陆续将AnySearch设置为Agent的默认搜索层工具。
上线仅一周,AnySearch便登顶Agent技能市场Skills.sh热榜首位。6月3日,AnySearch发布V2.1.0版本,完成了自上线以来在算法层与架构层的核心升级。
面向Agent需求:重构传统搜索逻辑
AnySearch致力于解决的核心问题,在于现有搜索体系与AI Agent需求之间的严重错位:过去三十年,搜索引擎全部围绕人类视觉习惯设计,以Top-K相关性为主要优化目标。然而,Agent并非人类——它拥有更宽、更平缓的信息接收能力,可在短时间内处理大量输入,搜索结果将直接进入推理链路,成为分析与决策的依据。针对人类优化的相关性排序,对Agent而言已是一套过时的机制。
“一个共识正在逐步形成:未来Agent的竞争,不仅局限于模型能力的比拼,更是信息获取能力的较量。”AnySearch联合创始人韩广彤指出。

图丨 AnySearch 团队成员(来源:AnySearch)
AnySearch的核心团队由资深AI开发者组成。在产品研发初期,他们围绕AI Agent信息获取这一主题,深度访谈了超过100位开发者,归纳出三大共性需求:搜索过程需高效,减少调用次数与上下文消耗;相比单纯覆盖更多网页,开发者更希望直接获取金融、法律、学术、安全等专业领域的多维数据;他们需要的并非又一个搜索引擎,而是一套适配Agent与AI工作流的信息获取基础设施。
全链路智能搜索:少量调用即可完成复杂专业调研
基于对开发者需求的深入洞察,AnySearch构建了一套全新的搜索体系。当一条查询进入AnySearch,第一步并非直接检索,而是进行查询理解。
以企业尽职调查场景为例:用户在Agent中输入查询某公司股权结构、涉诉记录和专利布局的指令后,系统首先识别这是一项企业研究任务,并将其拆解为多个维度的信息需求。随后进入路由编排阶段——股权结构查询走企业工商数据源,涉诉记录查询走法律数据库,专利布局查询走知识产权数据库,实现多路并行检索。

图丨 AnySearch 的查询检索流程(来源:AnySearch)
结果返回后,系统对不同来源的数据进行归一化、重排序与结构化融合,将股权关系、经营记录、诉讼信息和专利数据映射至同一家企业实体。最终向Agent交付的是一份附带来源标注的结构化尽调结果,Agent可直接基于该结果生成报告。
同样的路由逻辑也适用于AI编程、学术研究等垂直领域。其价值不仅在于信息更精准,还在于减少无效检索带来的延迟与资源浪费。
这种效率差异是可以量化的。在AnySearch近期进行的一次搜索能力测试中,多个接入不同搜索工具的Agent执行相同的代码研究任务,所有方案均找到了正确答案,但AnySearch仅用了1次搜索调用,而其他工具分别需要7次、16次和28次。有开发者在实际测试中反馈,平台输出的金融数据精确到了具体数值,而非模糊的“大幅增长”。
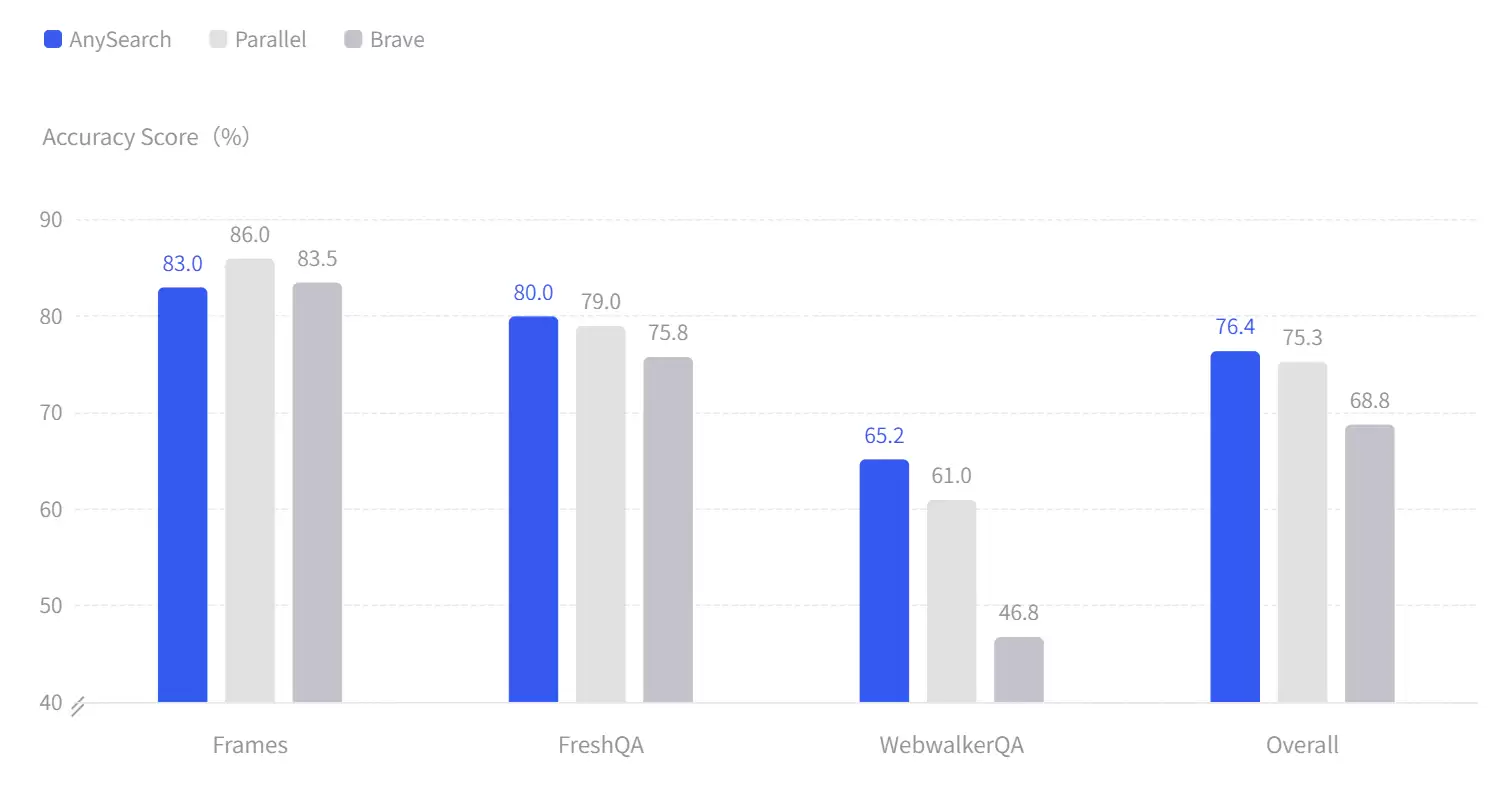
图丨 AnySearch 在三个基准数据集上的准确率表现(来源:AnySearch)
V2.1.0版本的升级重点同样集中在这条链路上:算法层引入了融合语义相关性与时效性信号的混合排序机制,架构层重构了领域划分与路由逻辑。韩广彤指出,此前最大的瓶颈并非单纯的延迟或准确率,而是搜索质量的稳定性——当Agent开始处理日益复杂的跨领域任务时,系统需要持续返回正确的结果。
自建数据管线的深耕,构筑信息护城河
专业数据的来源决定了产品质量。AnySearch采用自建索引与外部数据源接入相结合的联邦架构。针对金融、法律、学术、安全、企业工商等高价值领域,团队构建了自有数据管线,覆盖从采集、清洗到索引构建的端到端流程;核心数据实现完全自主可控,规避了第三方API可能带来的质量、更新频率与稳定性问题;通用场景与长尾需求则通过外部数据源进行补充。
针对金融、司法等高容错率场景,平台建立了多源交叉验证机制,所有结构化数据均保留来源信息与可追溯链路,避免Agent因依赖单一来源而做出误判。
然而,真正的挑战在于日常维护。专业数据运维是一项需要长期投入的系统性工作:不同领域的数据更新节奏差异显著,接口协议与质量信号完全异构,跨领域之间缺乏天然可比的质量标准。此外,Agent获取结果后的推理效果如何,搜索系统无法直接感知,只能依赖间接指标持续优化。韩广彤感叹:“这是一块永远滚不到山顶的石头”。
Skill接入方式走红,社区生态自然生长
AnySearch同时支持Skill、MCP、API三种接入方式。其中,几乎零配置、易于部署的Skill方案率先出圈,赢得了社区广泛认可。AnySearch上线仅一周,便登顶Agent技能市场Skills.sh热榜首位。
图丨 AnySearch 的 GitHub 主页(来源:GitHub)
韩广彤表示,尽管AnySearch Skill在GitHub上的关注度高于MCP,但这并不代表实际使用量领先。在团队的产品定位中,Skill适用于个人轻量化场景,而MCP与API更适配企业级深度集成与生产环境部署,本地化MCP方案也在持续探索中。
除了增长速度超出预期,更令团队意外的是其扩散方式。越来越多的开发者自发为AnySearch编写第三方工具与工作流,在一些团队原本未重点关注的Agent框架中,也出现了社区贡献的集成项目。
商业模式清晰,持续验证信息质量的价值
生态的自发生长解决了从0到1的认知问题。AI搜索能否实现商业化?先行者已经给出了肯定的答案。
放眼全球,美国AI原生搜索厂商Exa以22亿美元估值完成融资,印证了该赛道的广阔前景。而AnySearch则走出了一条差异化路线:相较于将网页搜索做得更精准,AnySearch押注于网页之外的专业数据。
目前,产品对个人开发者完全免费,Pro付费版与企业定制方案也在同步推进中。全程无广告、无用户数据追踪,查询处理完毕即销毁——以信息质量本身构建商业壁垒。
上线首月,10万开发者对AnySearch的产品力给予了积极反馈。未来,AnySearch将持续迭代技术与数据能力,目标是成为Agent与AI工作流的默认信息获取基础设施,并不断验证高质量信息服务的商业化价值。




