Skills开发规范:4原则5维度5层检查,告别不稳定触发
时间:2026-06-16 18:59
基于官方规范,从内容准确性、结构清晰性、工程可测试性、安全配置及可维护性五个维度检查Skill质量,分析描述模糊、结构不清、缺少边界和验证四种失败模式,并指出上下文窗口变化、指令模糊和过拟合是稳定性问题的根源,强调设计层面的质量管控。
## Skills 开发规范:4 原则、5 维度、5 层检查,告别不稳定触发
封面图:Skill 质量检查五大维度概览
*图 1:Skill 质量检查五大维度概览*
你在写 Claude Skill 的时候,可能遇到过这些情况:
写了个 Skill,第一次跑效果不错,换个输入就完全不对了
description 认真写了,但 Claude 就是不主动触发它
SKILL.md 越写越长,改了一处发现另一处又出问题
测试用例跑全过,实际使用还是翻车
这些问题看起来五花八门,但根源往往指向同一个方向:Skill 的质量瓶颈在设计层面,不在模型层面。
Anthropic 官方发布的 skill-creator 本身就是一套完整的开发-测试-评估-迭代工作流。它的源码里藏着大量关于 Skill 质量管理的工程实践。结合官方文档和最佳实践文档,可以把 Skill 的质量检查整理成五个维度。下面逐个拆解。
### 1. Skill 不是提示词,是执行规范
先说一个容易混淆的点:很多人把 Skill 当成一段加长版的 prompt,写完就觉得大功告成。但官方文档对 Skill 的定位远不止于此。
官方文档原文说得很清楚:
> 注意这里的用词:程序。Skill 不是一段静态的描述文本,而是一个有输入、有处理逻辑、有预期输出的执行单元。
翻开 skill-creator 的源码,这个定位就很具体了。SKILL.md 文件定义了完整的工作流程:明确目标 → 编写草稿 → 创建测试用例 → 并行评估(with-skill vs baseline)→ 分析结果 → 迭代重写 → 扩大测试集再次验证。这和写一段提示词丢给模型,完全是两回事。
Skill 还有一个常被忽略的特性:持久性。官方文档明确指出:
> 换句话说,Skill 的内容一旦加载,就会在整个会话中持续存在。你写的不是一次性的指令,而是一份会反复生效的常设规范。所以 Skill 的设计必须考虑长期稳定性和一致性,不能只盯着单次执行的效果。
### 2. Skill 的四种失败模式
在拆解检查维度之前,先看看 Skill 在实际使用中最容易怎么翻车。从 skill-creator 源码和官方文档中,可以归纳出四种典型的失败模式。
#### 描述模糊:该触发时不触发
description 是决定 Claude 是否调用 Skill 的主要依据。官方文档说得很直白:Claude 使用它从可能超过 100 个可用 Skill 中选择正确的 Skill。
但实际写的时候,常见的坑包括:description 缺少关键触发词,导致 Claude 根本不调用;description 过于宽泛,比如写成 `Helps with documents`,触发率不稳定;description 超过 1,024 字符上限被截断,触发逻辑丢失。
skill-creator 的 SKILL.md 里专门有一章讲 Description Optimization,用了一套 60% 训练集 + 40% 留出测试集的优化流程,每个查询运行 3 次获取可靠触发率,最多迭代 5 次,才选出触发效果最好的描述。这说明描述设计不是拍脑袋的事。
#### 结构不清:内容堆成一坨
官方文档建议 SKILL.md 正文控制在 500 行以内。接近这个限制时,应该拆分内容到单独的文件,在 SKILL.md 中用清晰的指引引用它们。
实际中经常遇到的问题是:SKILL.md 超过 500 行没有拆分;references 文件存在但 SKILL.md 里没有说明什么时候该读取它;超过 300 行的参考文件缺少目录索引。这些都会导致 Claude 在需要详细信息时找不到正确的来源。
#### 缺少边界条件:没说不能做什么
官方最佳实践文档提到一个核心原则 - Principle of Lack of Surprise:
> Skill 的行为不应该让用户感到意外。要做到这一点,Skill 必须明确界定边界:什么情况做什么,什么情况不做什么。
常见的缺失包括:未处理边缘情况(空输入、错误格式);缺少错误恢复指导;没有说明什么不该做(负面边界)。没有负面边界的 Skill,就像没有护栏的高速公路,看起来畅通无阻,实际上随时可能跑偏。
#### 缺少验证:没有测试就没有信心
skill-creator 内置了一套完整的评估系统,核心是 evals.json 结构。每个测试用例包含 prompt(执行的任务)、expected_output(预期结果)、expectations(可验证的断言列表)。
但很多 Skill 开发者完全跳过了测试环节。更隐蔽的问题是:测试用例写了但没有区分度。skill-creator 的 Analyzer Agent 专门检查这种情况 - 某断言在有 Skill 和没 Skill 时都总是通过?说明这个断言无法区分 Skill 的价值,等于没测。
### 3. 五个维度的质量检查
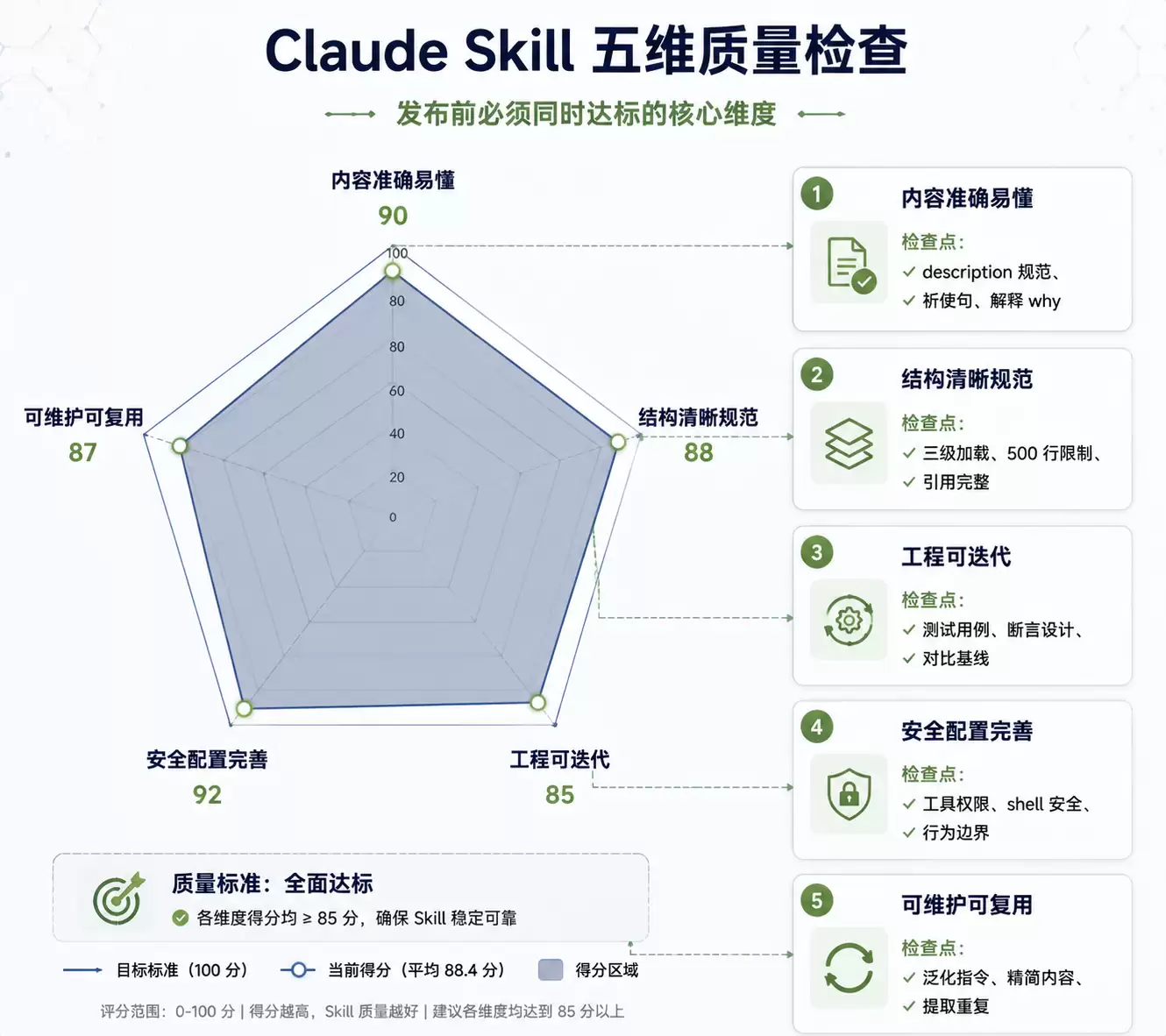
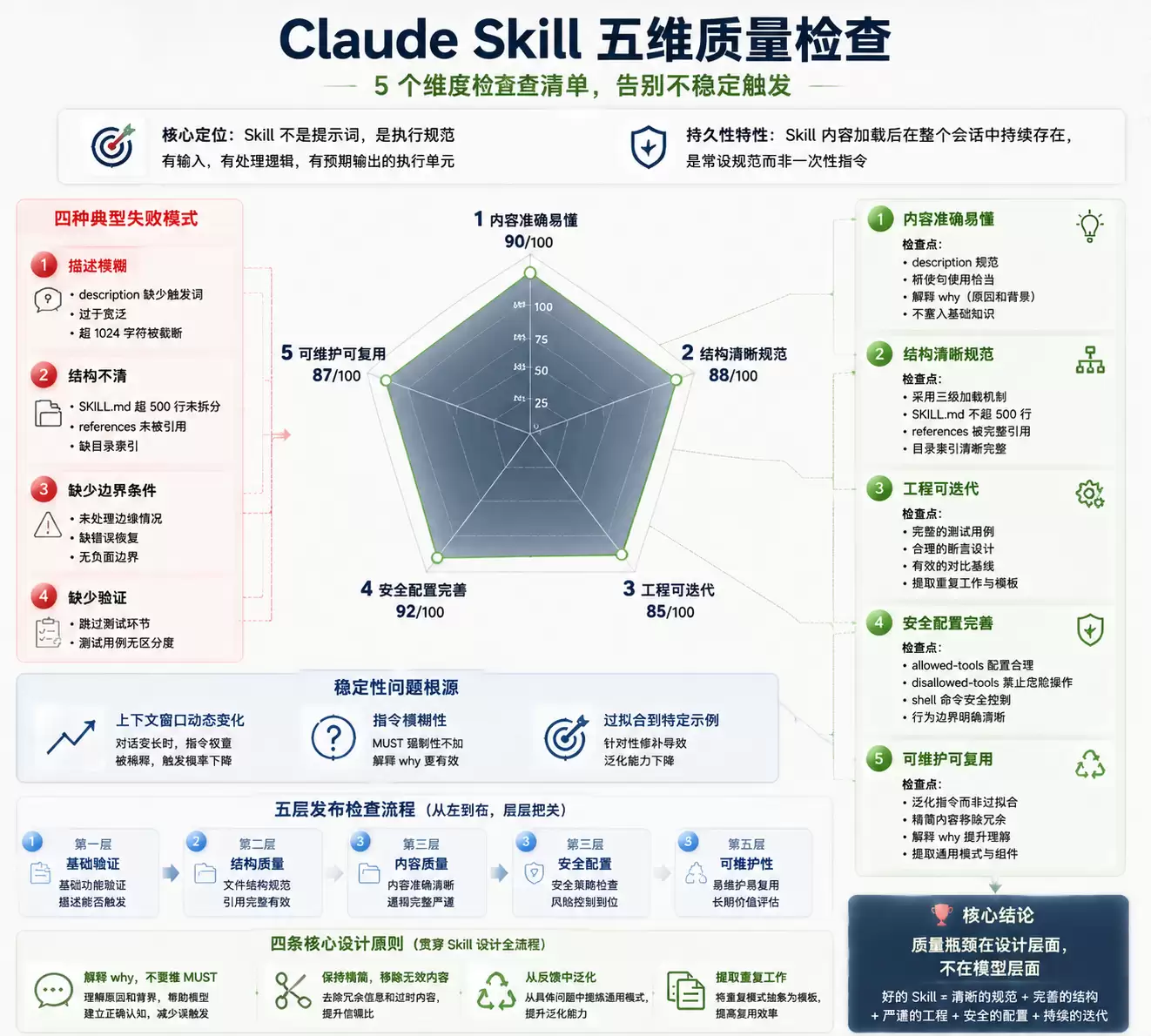
五维质量雷达图
*图 2:Claude Skill 五维质量检查雷达图*
上面四种失败模式,可以归结为五个质量维度的缺失。下面逐个展开,每个维度都包含检查标准、常见问题和对输出质量的影响。
#### 维度一:内容是否准确易懂
先看 Skill 的指令本身是否写得清楚。
| 检查项 | 检查标准 | 来源 |
|---|---|---|
| description 内容 | 包含 Skill 做什么 + 何时使用,第三人称,不超过 1024 字符 | 官方文档 frontmatter 规范 |
| 指令语言 | 使用祈使句,避免 ALWAYS/NEVER 全大写 | SKILL.md Writing Style |
| 解释 why | 解释背后的原因,而非堆砌强制规则 | SKILL.md 改进原则 |
| 默认假设 | Claude 已经很智能,不需要解释基础概念 | 官方最佳实践文档 |
常见问题:description 用第一人称写(`I can help you...`),导致在系统提示中显得突兀;指令里塞了太多 Claude 本来就知道的基础知识,浪费上下文窗口。
官方最佳实践给了个很直观的对比:解释 PDF 是什么、为什么用 pdfplumber、如何安装,这些内容大约消耗 150 个 token,而 Claude 其实根本不需要这些解释。直接给代码,50 个 token 就够了。
对输出质量的影响:内容不准确会导致 Claude 执行偏差,内容不简洁会挤占上下文窗口中其他信息的空间。官方文档说得很明确:上下文窗口是一种公共资源。Skill 与对话历史、系统提示、其他 Skill 元数据共享这个空间。多写的废话,就是在偷别的信息的空间。
#### 维度二:结构是否清晰规范
再看 Skill 的文件组织是否符合 Progressive Disclosure(渐进式加载)原则。
Progressive Disclosure 是 Skill 的三级加载体系:
| 层级 | 内容 | 加载时机 | 建议体量 |
|---|---|---|---|
| 元数据 | name + description | 始终在上下文中 | 约 100 词 |
| 正文 | SKILL.md body | Skill 触发时加载 | 小于 500 行 |
| 捆绑资源 | scripts / references / assets | 按需加载 | 无硬限制 |
常见问题:把所有内容塞进 SKILL.md,不使用 references 拆分;references 文件存在但 SKILL.md 没有写明何时读取;超过 300 行的参考文件没有目录。
对输出质量的影响:结构混乱的 Skill 会导致 Claude 在执行时遗漏关键步骤,或者在上下文压缩后丢失重要信息。官方文档提到,自动压缩时会保留每个 Skill 的最近调用,但只有前 5,000 个 token,多个 Skill 共享 25,000 个 token 的组合预算。如果 SKILL.md 太长,关键信息很可能在压缩时被截断。
#### 维度三:工程设计是否支持迭代维护
第三个维度看的是 Skill 是否具备可测试、可对比、可迭代的工程基础。
| 检查项 | 检查标准 | 来源 |
|---|---|---|
| 测试用例 | 至少 2-3 个真实用户会说的测试提示 | 官方最佳实践 |
| 断言设计 | 客观可验证,有描述性名称,在 benchmark viewer 中一目了然 | SKILL.md evals 规范 |
| 对比基线 | with-skill vs baseline 并行测试 | skill-creator 评估系统 |
| 重复工作 | 多个测试用例独立写的类似逻辑,应提取为脚本 | SKILL.md 改进原则 |
常见问题:没有 evals.json,完全靠手动测试;断言只检查文件名不检查内容,通过率虚高;没有 baseline 对比,无法判断 Skill 到底有没有价值。
对输出质量的影响:没有测试的 Skill 在修改时会引入回归问题。skill-creator 的 Grader Agent 有一条关键原则:不确定时,举证责任在通过方(When uncertain: The burden of proof to pass is on the expectation)。如果没有明确证据证明断言通过了,就按失败处理。这个标准很严格,但正是这种严格才能保证 Skill 在迭代中不会悄悄退化。
#### 维度四:安全配置是否完善
第四个维度看 Skill 的工具权限和行为边界配置。
| 检查项 | 检查标准 | 来源 |
|---|---|---|
| allowed-tools | 预先批准 Skill 需要的工具 | 官方文档 frontmatter |
| disallowed-tools | 从工具池中移除不需要的工具 | 官方文档 frontmatter |
| disable-model-invocation | 不需要自动触发时设为 true | 官方文档 |
| shell 命令安全 | `!` 命令注入的 shell 命令不含危险操作 | 官方文档动态注入 |
常见问题:allowed-tools 和 disallowed-tools 都没配,Skill 默认拥有所有工具权限;`!` 动态注入的 shell 命令没有审查;信任第三方仓库时没有先查看其项目 Skills(官方文档明确提示:skill 可授予自己广泛的工具访问权限)。
对输出质量的影响:安全配置缺失不一定影响单次输出质量,但会导致 Skill 在长期使用中间出现不可控行为。一个没有工具限制的 Skill,可能在某些场景下执行了用户不期望的操作。官方文档的建议是:信任存储库前需查看项目 skills。
你在开发 Skill 时有没有踩过安全方面的坑?比如 Skill 自动执行了意料之外的 shell 命令?欢迎在评论区聊聊。
#### 维度五:可维护性与复用性是否达标
最后一个维度,看的是 Skill 在长期使用中的可维护性。skill-creator 的 SKILL.md 里有四条改进原则,直接关系到这一点。
原则一:从反馈中泛化,不做过拟合的小修小补,而是尝试不同的隐喻或工作模式。
原则二:保持 prompt 精简,移除不起作用的内容。判断方法不是看最终输出,而是读执行转录 - 模型在哪个环节犹豫了、绕弯了,那些地方往往就是指令不够清晰或多余的。
原则三:解释 why,避免 ALWAYS/NEVER 全大写。官方说法是 this is a tell - 全大写是过拟合的黄牌信号。
原则四:寻找重复工作。如果多个测试用例独立写了类似的辅助脚本,说明这个脚本应该直接捆绑到 Skill 的 scripts 目录中。
常见问题:指令过拟合到特定示例,换一个输入就不工作;每次发现问题都加一条 MUST 规则,Skill 越来越臃肿;没有版本管理意识,改了之后不知道改了什么。
对输出质量的影响:可维护性差的 Skill 会随着时间推移越来越不稳定。每次修补都在增加复杂度,而不是解决根本问题。最终的结果是:改不动,删可惜,重写又来不及。
### 4. 稳定性问题的根源
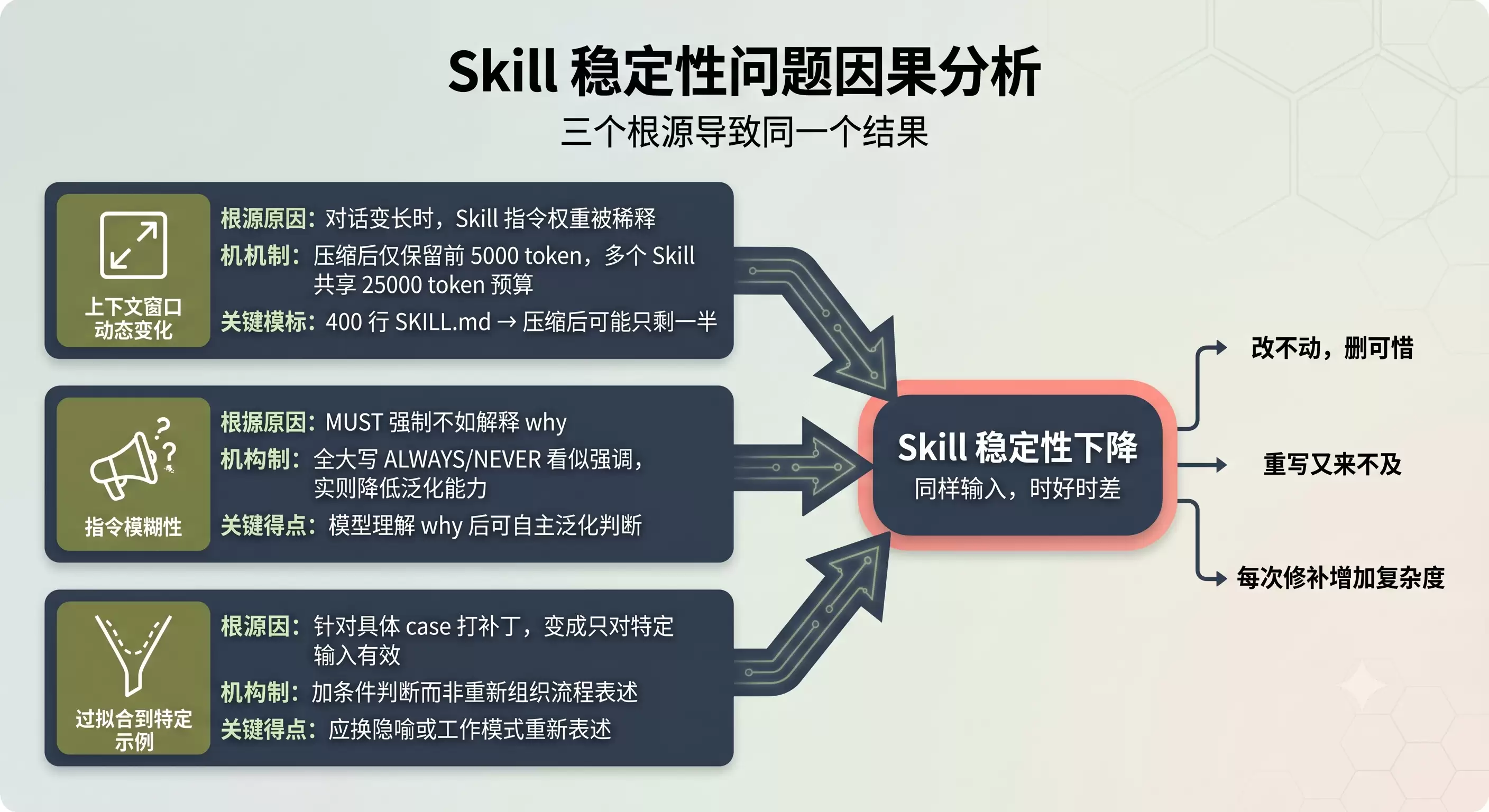
Skill 稳定性问题因果分析图
*图 3:Skill 稳定性问题因果分析*
上面五个维度检查的是 Skill 的静态质量。但在实际使用中,还有一个更让人头疼的问题:稳定性。同一个 Skill,同样的输入,为什么有时好有时差?
从源码和文档分析,稳定性问题的来源主要有三个。
#### 上下文窗口的动态变化
官方文档说得很清楚:SKILL.md 内容作为单个消息进入对话后,会在会话其余部分保持。但会话长度不固定。对话短的时候,Skill 的指令占比高,模型遵守得好;对话长了,其他内容挤进来,Skill 指令的权重就被稀释了。
自动压缩流程也影响稳定性。压缩后只保留每个 Skill 最近调用的前 5,000 个 token,多个 Skill 共享 25,000 个 token 预算。如果你的 SKILL.md 有 400 行,压缩后可能只剩下一半内容。
这就是为什么官方反复强调 SKILL.md 要控制在 500 行以内 - 不只是加载效率的问题,更是压缩后信息完整性的问题。
#### 指令的模糊性
skill-creator 的 Writing Style 章节有一段很关键的话:
> 与其用 MUST 强制,不如解释为什么重要。因为模型理解了 why 之后,可以在不同场景下做出合理的泛化判断;而只遵循 MUST 的模型,一旦遇到 MUST 没覆盖的情况就会卡住。
这就是为什么官方建议避免全大写的 ALWAYS/NEVER - 它们看起来强调力度强,实际上反而降低了 Skill 的泛化能力,导致稳定性变差。
#### 过拟合到特定示例
SKILL.md 的改进原则第一条就是从反馈中泛化。如果每次遇到问题都是针对具体 case 打补丁,Skill 就会变成一个只对特定输入有效的怪物。
官方的说法更直接:don't do narrow surgical fixes that overfit。解决过拟合的方法是换一种工作模式或隐喻来重新表述指令,而不是加更多的条件判断。举个思路:如果模型总是跳过某个步骤,与其加一条 `MUST NOT skip step 3`,不如重新组织整个流程的表述方式,让步骤三的逻辑自然地嵌入整体流程中。
### 5. 发布前的标准检查流程
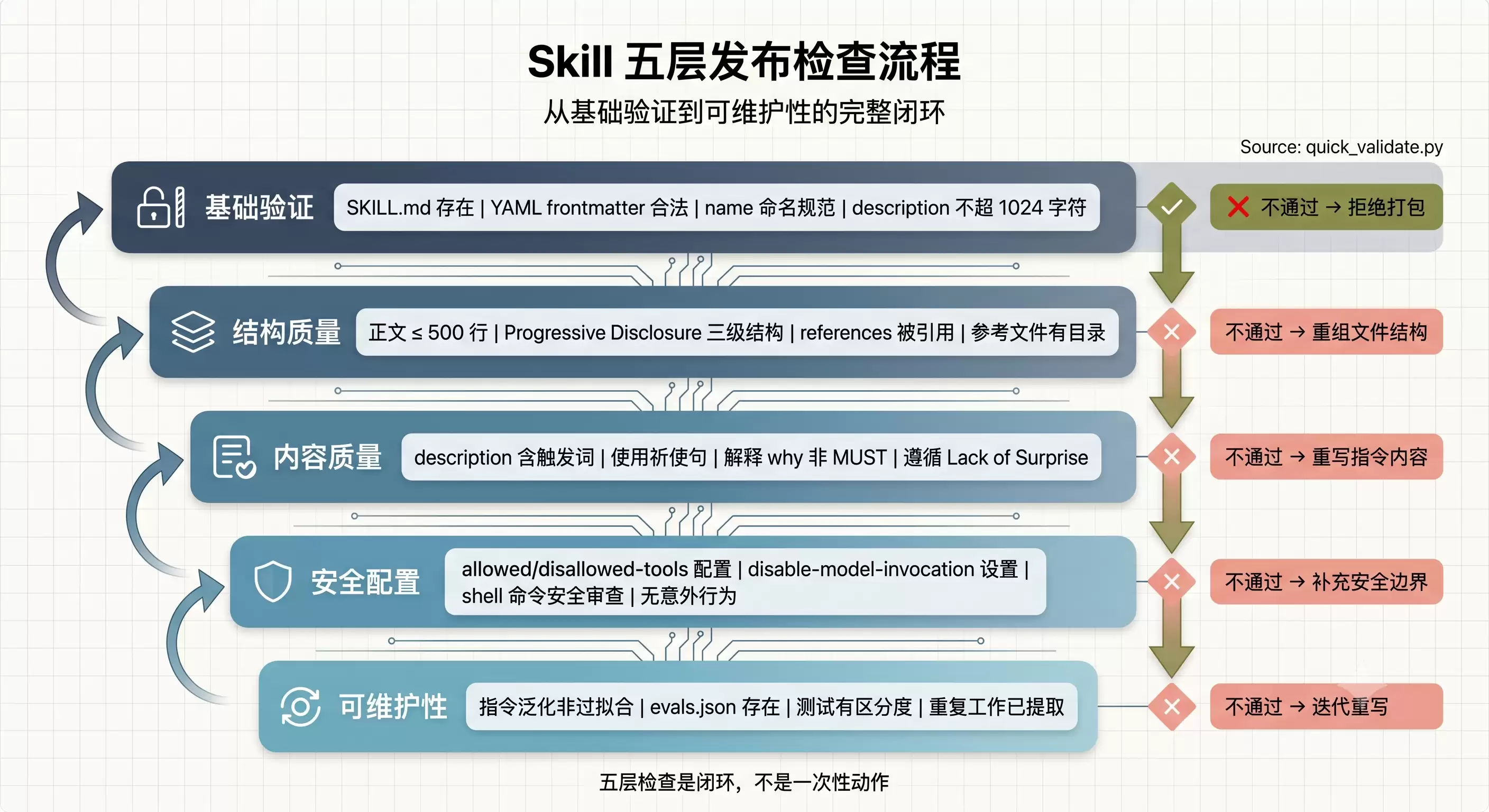
五层发布检查流程图
*图 4:五层发布检查流程*
把上面的分析落地,可以整理出一套分层的发布前检查流程。这套流程参考了 skill-creator 的 quick_validate.py 脚本和官方文档的综合要求。
#### 第一层:基础验证
这是 quick_validate.py 的检查逻辑,是 Skill 能被打包的硬性门槛。package_skill.py 在打包前会自动调用 quick_validate,验证不通过直接拒绝打包:
```
# quick_validate.py 的核心检查项(来源:skill-creator 源码)
# 1. SKILL.md 必须存在
# 2. 必须有 YAML frontmatter(以 --- 开头)
# 3. frontmatter 必须是合法 YAML 字典
# 4. name 必须存在,kebab-case,最大 64 字符
# 5. name 不能以连字符开头/结尾或包含连续连字符
# 6. description 必须存在,不含尖括号(< 或 >),最大 1024 字符
# 7. compatibility(可选)必须是字符串,最大 500 字符
# 8. 无非法 frontmatter 属性
```
注意 name 的命名规范:不能包含保留词 `anthropic` 和 `claude`,推荐使用动名词形式(verb-ing),比如 `processing-pdfs`、`analyzing-spreadsheets`。避免使用 `helper`、`utils`、`tools` 这类没有信息量的名字。
#### 第二层:结构质量
过了基础验证后,检查 Skill 的文件组织:
- SKILL.md 正文是否在 500 行以内
- 是否使用了 Progressive Disclosure 三级结构
- references / scripts / assets 是否被合理引用
- 超过 300 行的参考文件是否有目录
#### 第三层:内容质量
结构没问题后,检查指令内容本身:
- description 是否包含触发关键词和何时使用的上下文
- 指令是否使用祈使句
- 是否解释了 why 而非堆砌 MUST
- 是否包含示例和输出格式定义
- 是否遵循 Lack of Surprise 原则
#### 第四层:安全配置
确认 Skill 的工具权限配置:
- allowed-tools / disallowed-tools 是否合理配置
- disable-model-invocation 是否正确设置
- `!` 动态注入的 shell 命令是否安全
- 是否包含可能让用户意外的行为
#### 第五层:可维护性
最后一层,检查 Skill 的长期可维护性:
- 指令是否泛化而非过拟合
- 是否有 evals.json 测试用例
- 测试用例是否有区分度(不是 always pass 或 always fail)
- 重复工作是否已提取为脚本
这五层不是可选的。skill-creator 的工作流明确要求:编写草稿 → 创建测试 → 运行评估 → 分析结果 → 迭代重写 → 扩大测试集再次验证。这是一个闭环,不是一次性动作。
不同模型也需要交叉验证。官方最佳实践文档指出:对 Opus 完美有效的内容可能需要为 Haiku 提供更多细节。如果你的 Skill 需要支持多个模型层级,至少在 Haiku 和 Sonnet 上各跑一轮测试。
### 6. 降低维护成本的四个设计原则
最后说说怎么从设计阶段就降低 Skill 的维护成本。这四条原则直接来自 skill-creator 的 SKILL.md,每一条都对应一类具体的维护问题。
#### 解释 why,不要堆 MUST
与其写 `ALWAYS use error handling`,不如写 `错误处理很重要,因为它能防止一个文件的失败中断整个批处理流程`。模型理解了原因,自然会在合适的场景做出正确判断。官方的说法是:全大写的 MUST 是 overfitting 的黄牌信号。
#### 保持精简,移除无效内容
判断哪些内容不起作用?skill-creator 的方法是读执行转录,而不只是看最终输出。转录会告诉你模型在哪个环节犹豫了、绕弯了,那些部分往往就是指令不够清晰或者多余的地方。移除这些内容,Skill 反而更稳定。
#### 从反馈中泛化
遇到问题时,不要做手术刀式的针对性修补。官方建议是尝试不同的隐喻或工作模式来重新表述指令,让模型从逻辑层面理解任务,而不是通过堆叠规则来约束行为。
#### 提取重复工作
如果多个测试用例独立写了类似的辅助脚本,说明这个脚本应该直接捆绑到 Skill 的 scripts 目录中。这和普通软件工程中的 DRY 原则一致 - 重复代码是维护成本的根源。
### 总结
回到开头的问题:Skill 的质量瓶颈到底在哪?
答案很明确:在设计层面,不在模型层面。模型已经很智能了,但再智能的模型也需要清晰的规范来约束行为。一个合格的 Skill 必须在内容准确性、结构规范性、工程可维护性、安全配置、可复用性这五个维度上同时达标。
官方的 skill-creator 给出了很好的参考实践:基础验证有 quick_validate.py 做硬性约束,测试评估有 evals.json + Grader Agent + Comparator Agent 做量化对比,迭代改进有四条设计原则做方法论指导。
说到底,写 Skill 和写代码是一样的道理。你不能写完功能就说做完了,还得有测试、有 review、有迭代。区别只在于,Skill 的测试对象是 AI 模型的行为,而不是函数的输入输出。
五个维度里你觉得哪个最难做到?是描述设计、结构拆分,还是测试评估?欢迎在评论区聊聊你的经验。




