一、核心概念
1. 传统智能体的瓶颈
在SKILL架构出现之前,大模型智能体基本就是个“一体式定制手机”——打电话、拍照、导航、聊天,所有功能都硬生生写死在系统核心代码里。想加个翻译功能?得去修改手机底层系统,还随时可能把原有的功能搞崩。想把拍照能力借给第三方应用用?想都别想,代码跟系统绑得死死的,根本解不开。更麻烦的是,功能边界模糊得很,大模型根本搞不清什么时候该查数据、什么时候该生成文本,经常逻辑错乱、数据报错。

这就是传统智能体的四大工程死xue:
1. 强耦合:能力跟核心代码深度绑定,牵一发而动全身;2. 难扩展:想加新功能就得改底层逻辑,开发周期长、风险还高;
3. 难复用:每个智能体都是定制开发,能力模块跨不出项目、跨不出场景;
4. 难维护:功能迭代没有独立版本,出了问题排查成本极高。
2. SKILL架构核心定义
SKILL架构,简单说就是面向大模型智能体的能力解耦与编排架构。核心动作只有两个:原子化拆分,标准化封装。
原子化拆分,就是把智能体的所有能力,拆成最小可用、功能闭环的独立单元,也就是SKILL单元。拆分的时候严格遵循单一职责原则,保证每个单元只负责一个明确的功能领域。
标准化封装,就是给每个SKILL单元统一数据格式、触发规则、依赖管理,让所有能力都能像乐高积木一样自由拼接。标准化搞定了,技能之间的互操作性和可复用性也就有了保障。
几个核心概念值得拎出来说说:
输入输出Schema校验:这是给数据定规矩。比方说规定输入必须是“用户ID + 日期”,输出必须是“JSON格式的统计结果”,这样就能避免技能之间数据乱码;触发规则:大模型判断什么时候该调用哪个SKILL,支持关键词、上下文、意图、置信度多维度匹配,可不是简单的关键词匹配;
技能依赖链:多个SKILL按逻辑顺序调用,比如“数据采集→数据清洗→数据分析→报告生成”,前一个的输出就是后一个的输入;
标准化组装:不用写核心代码,通过配置SKILL的组合方式,就能快速搭出新的智能体。
一个标准的SKILL单元结构是这样的:输入校验 + 核心逻辑 + 输出校验 + 触发规则 + 依赖声明。
单元模块详细介绍:
1. 输入校验:定义和验证输入参数的类型、格式、必填项等2. 核心逻辑:具体的业务处理逻辑
3. 输出校验:验证并格式化输出结果
4. 触发规则:定义何时以及如何调用此技能
5. 依赖声明:声明所需的前置技能或外部服务
SKILL单元可以是最小功能,比如手机号校验,也可以是复杂任务,比如多步骤数据分析,但必须满足这些特性:
边界清晰:每个技能都有明确的功能边界和责任范围独立运行:不依赖其他非声明的外部状态或服务
可单独迭代:可以独立测试、优化和更新
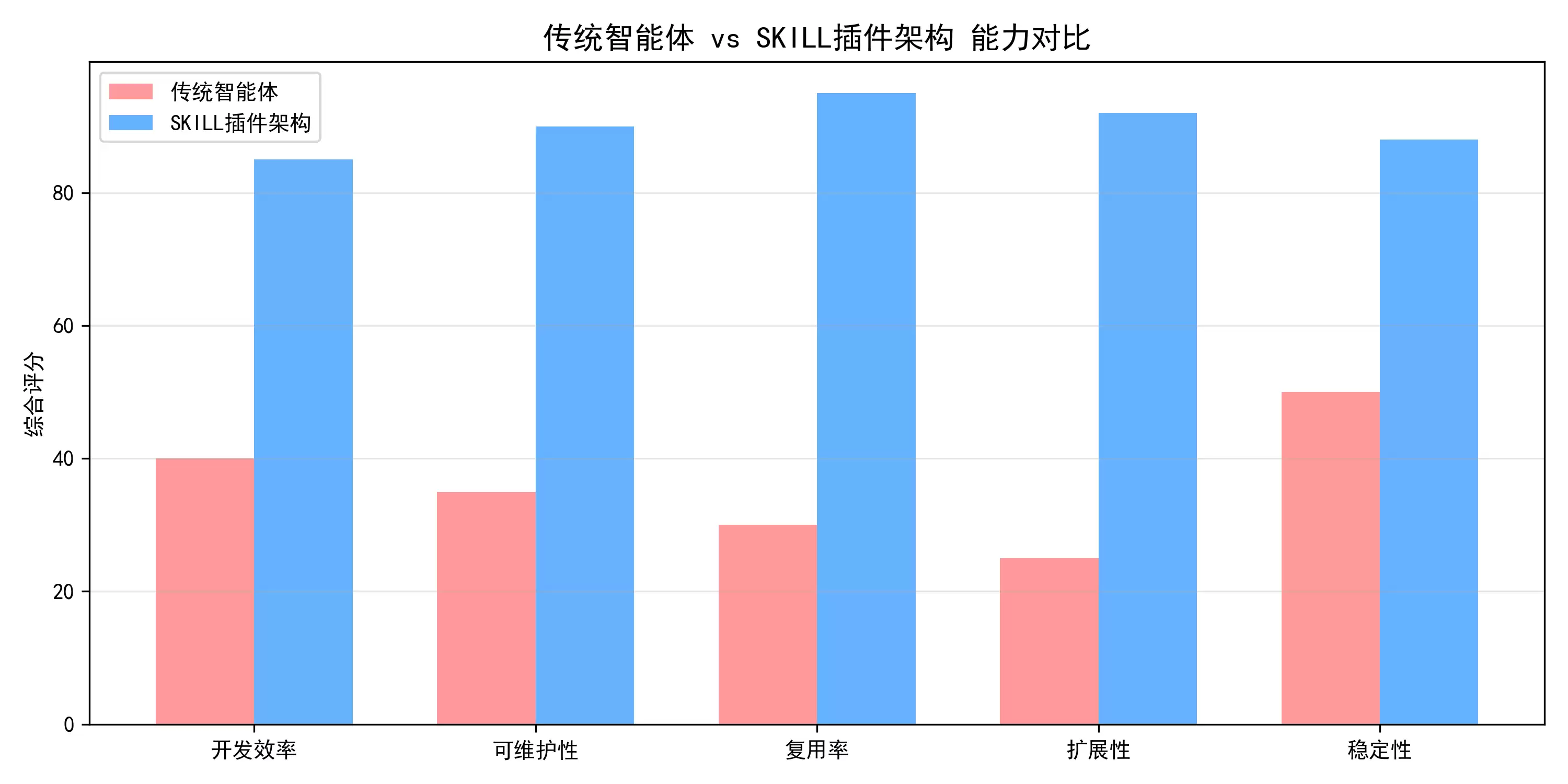
3. SKILL架构优势
3.1 技术优势
模块化程度高:便于维护和升级复用性强:同一技能可在不同场景下重复使用
测试友好:每个单元可以独立测试
扩展性好:新增功能只需添加新技能即可
3.2 业务优势
快速组装:通过组合现有技能快速构建新功能风险隔离:单个技能故障不会影响整体系统
团队协作:不同团队可并行开发不同技能
成本优化:减少重复开发,提高开发效率
4. SKILL架构的核心价值
大模型本身是大脑,负责理解意图、生成逻辑,但不擅长执行具体功能、保证数据准确性。SKILL架构给大模型装上了标准化的手脚:
大模型只需要做决策:判断用户需要什么能力;SKILL单元负责执行:精准完成具体功能,保证数据合规、逻辑正确;
最终实现:大模型通用能力 + SKILL标准化能力 = 高可用、可工程化的智能体。
二、SKILL架构基础
1. 五大核心组件
1.1 原子SKILL单元:最小执行载体
定位:智能体能力的最小颗粒度,不可再拆分;特性:功能闭环、独立运行、无外部依赖,是最基础SKILL;
示例:文本生成SKILL、数据库查询SKILL、API对接SKILL、参数校验SKILL。
1.2 Schema校验模块:数据安全底座
作用:统一所有SKILL的输入输出数据格式;技术实现:Python的Pydantic库、YAML/JSON Schema;
价值:技能间通信零误差,杜绝数据类型错误、字段缺失。
1.3 触发调度引擎:大模型决策入口
作用:接收大模型的意图判断,精准匹配并调用对应SKILL;匹配维度:关键词、用户意图、上下文对话、置信度阈值;
优势:复杂场景下不混淆,比如用户说“帮我分析数据”,不会调用文本生成SKILL。
1.4 依赖管理中心:能力组合核心
作用:管理SKILL之间的调用关系、第三方服务依赖;能力:支持单向依赖、链式依赖、并行依赖;
示例:报表生成SKILL → 依赖数据分析SKILL → 依赖数据采集SKILL。
1.5 版本与迭代管理器:维护保障
作用:每个SKILL独立版本控制,更新不影响其他能力;价值:修复一个SKILL的bug,无需重启整个智能体,迭代成本降低90%。
2. 基础运行原理
2.1 解耦原理:能力与核心代码分离
传统架构:核心系统 → 功能A → 功能B → 功能C(强绑定)
SKILL架构:调度引擎 ↔ SKILL1 ↔ SKILL2 ↔ SKILL3(松耦合)
核心系统只负责调度,不承载任何业务能力;每个SKILL是独立文件、独立模块,新增、删除SKILL,不影响核心代码。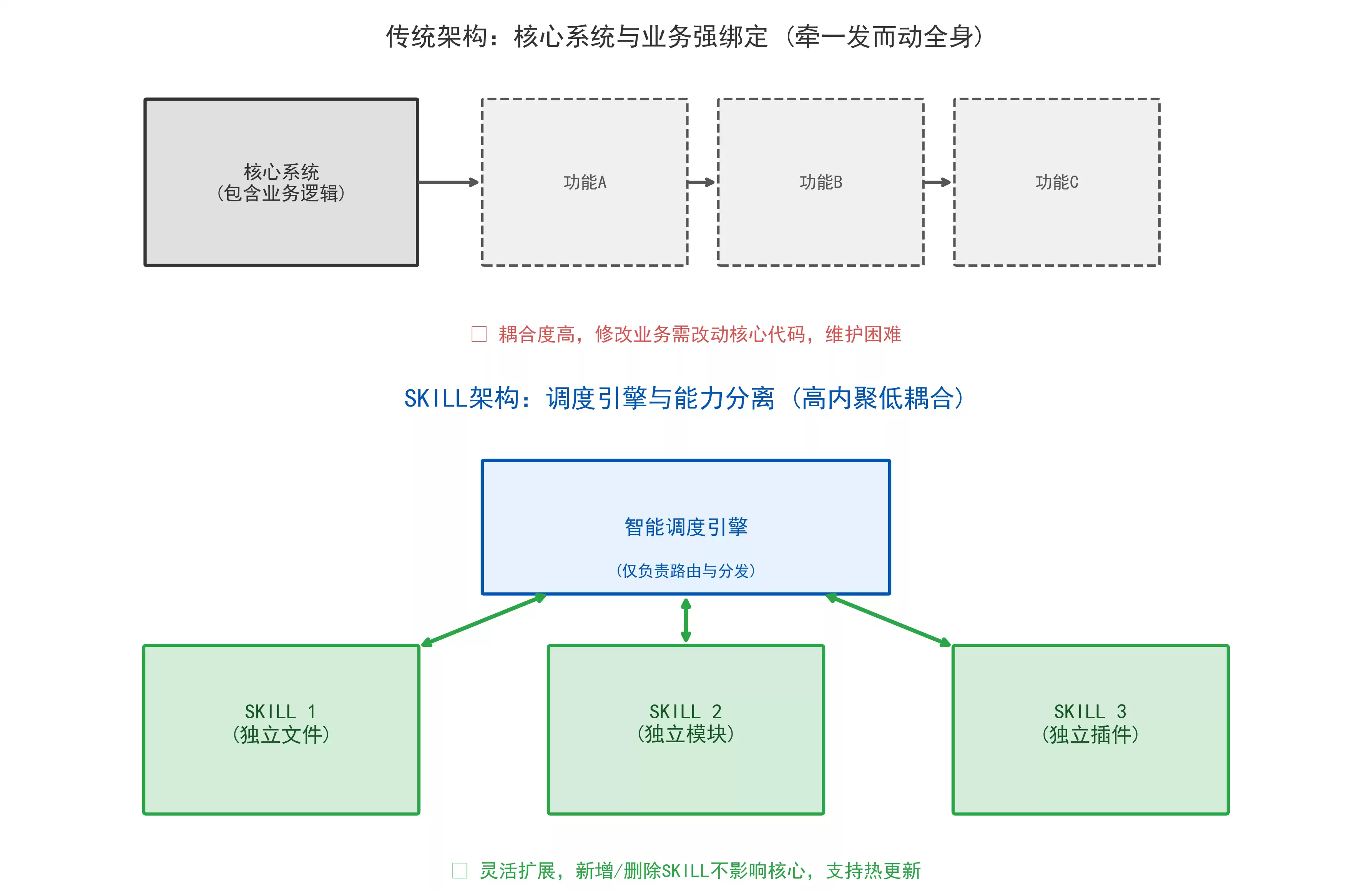
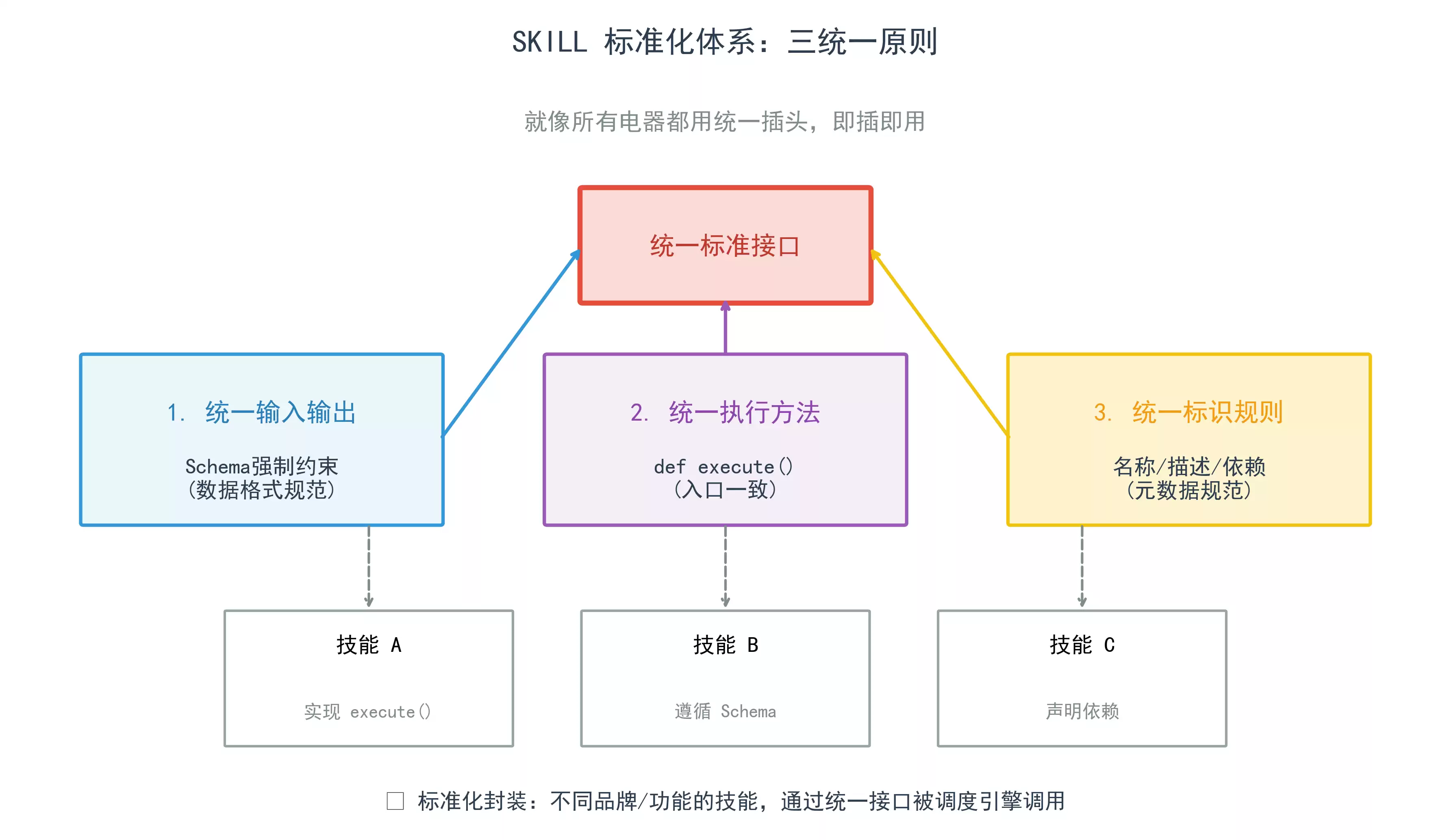
2.2 标准化原理:统一通信协议
所有SKILL遵循三统一:
1. 统一输入输出:用Schema强制约束;2. 统一执行方法:所有SKILL都有execute()方法;
3. 统一标识规则:SKILL名称、描述、依赖声明格式一致。
这就好比所有电器都用统一插头,不管什么品牌,插上就能用。
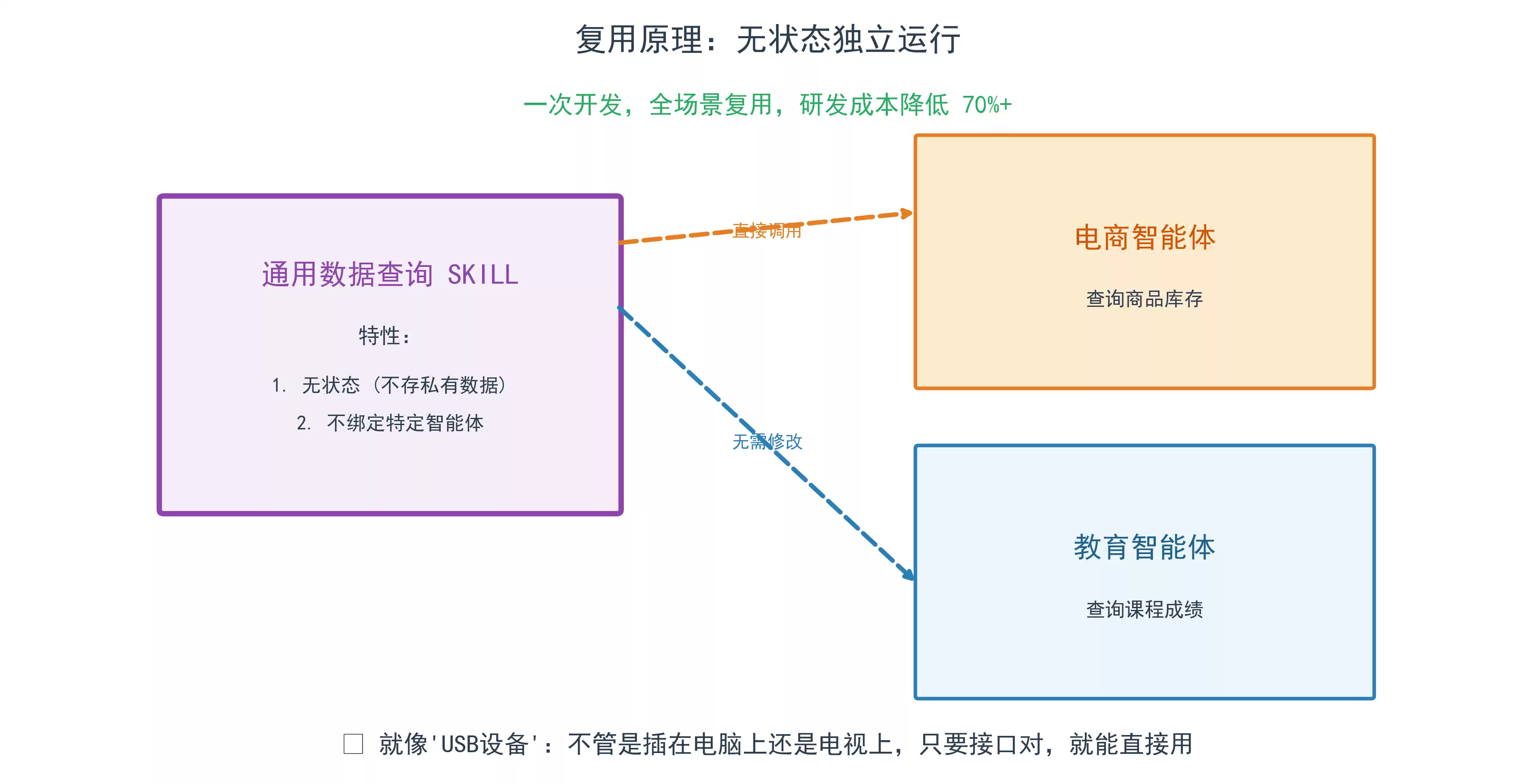
2.3 复用原理:无状态独立运行
SKILL单元不绑定任何智能体、不存储私有数据,只要符合标准,就能在任何项目中随意调用:
电商智能体的“数据查询SKILL”,可以直接拿给教育智能体用;一次开发,全场景复用,研发成本降低70%以上。
2.4 扩展原理:独立迭代升级
每个SKILL有独立版本号:
v1.0:基础查询功能;v1.1:增加缓存优化;
v2.0:支持多数据源查询。
更新的时候,只替换单个SKILL文件,不用重启智能体,无风险、高效率。
3. 四大设计原则
1. 单一职责原则:一个SKILL只做一件事,比如校验手机号SKILL不做信息发送;2. 无状态原则:SKILL执行不存储上下文数据,数据由调度引擎统一管理;
3. 标准化原则:所有SKILL遵循统一的输入输出、触发、依赖规范;
4. 可复用原则:SKILL跨智能体、跨项目通用,一次开发,无限复用。

4. 实施细节考虑
粒度平衡:技能拆分不宜过细或过粗性能考量:过多技能调用可能影响响应速度
版本管理:需要良好的技能版本控制系统
监控运维:建立技能运行状态的监控体系
5. 示例:Schema标准化封装
示例主要展示了基于Pydantic的SKILL标准化封装,核心设计如下:
输入层:参数校验与类型约束,DataQueryInput 定义了 user_id(最小3字符)、query_date(日期格式)、query_type(可选)执行层:原子化业务逻辑,DataQuerySkill.execute() 完成数据查询并返回结构化结果
输出层:标准化响应格式,DataQueryOutput 统一返回 status/data/error_msg 三字段
代码说明:
Schema强制校验:用Pydantic定义输入输出规则,任何不符合格式的参数都会被拦截并报错,保证数据安全;原子化设计:每个SKILL独立封装,修改查询逻辑不影响其他代码,实现原子化;
标准化接口:输入输出完全标准化,可被任何其他SKILL或调度引擎调用。
自描述能力:skill_name + skill_description 供大模型理解功能意图
输出结果:
SKILL执行结果(正确):
{'status': 'success', 'data': {'user_id': 'U12345', 'query_date': '2026-04-08', 'content': '用户当日业务数据:订单数5,消费金额200元'}, 'error_msg': None}
SKILL执行结果(错误):
{'status': 'failed', 'data': {}, 'error_msg': "1 validation error for DataQueryInput\nquery_date\n String should match pattern '^\d{4}-\d{2}-\d{2}$' [type=string_pattern_mismatch, input_value='2026年04月08日', input_type=str]\n For further information visit pydantic.dev/2.12/v/string_pattern_mismatch"}
三、执行流程
1. 流程说明
结合以上示例,我们扩展成多个SKILL集成的模式,看一下完整的执行流程是什么样的。

步骤 1:用户输入(原始请求)
用户:帮我查询 U12345 用户 2026-04-08 的业务数据,然后生成一份分析报告
步骤 2:大模型意图理解(大脑决策)
大模型解析出:
用户需要两个能力:数据查询 + 报告生成;执行顺序:先查询,后生成;
关键参数:user_id=U12345,query_date=2026-04-08。
步骤 3:触发调度引擎匹配SKILL
调度引擎根据大模型的意图,匹配两个标准化SKILL:
1. data_query_skill(数据查询)2. report_generate_skill(报告生成)
步骤 4:SKILL依赖链执行
1. 执行data_query_skill,返回标准化查询结果;2. 调度引擎把查询结果作为输入,传给report_generate_skill;
3. 执行报告生成SKILL,完成复杂任务。
步骤 5:结果返回用户
返回最终的分析报告,全程无数据错误、无逻辑混乱。
2. 应用实践
通过以上Schema标准化封装的示例,我们根据流程扩展成多SKILL,展示链式编排能力以及依赖链执行。
相比旧示例有以下核心增强:
- 1. 多SKILL链式编排能力:
旧示例仅展示单个SKILL调用,新代码实现了调度引擎(SkillScheduler):数据查询SKILL → 报告生成SKILL 的完整链路,SKILL间数据自动传递,query_result 作为 report_input- 2. SKILL组合复用模式:
调用方式从简单示例的直接调用升级为通过调度引擎编排数据流转升级为SKILL间自动传递- 3. 更完整的工程化结构
ReportGenerateSkill:展示SKILL如何消费其他SKILL的输出SkillScheduler.run_pipeline():统一入口管理多SKILL执行顺序
链路状态追踪:每个步骤的成功/失败都有明确日志
输出结果:
==================================================
调度引擎启动:数据查询 → 报告生成
==================================================
步骤1:执行 data_query_skill
数据查询成功,返回标准化结果
步骤2:调度引擎传递结果 → report_generate_skill
报告生成成功
==================================================
最终输出:
{'status': 'success', 'query_data': {'user_id': 'U12345', 'query_date': '2026-04-08', 'content': '用户当日业务数据:订单数5,消费金额200元'}, 'report': '【业务数据报告】\n用户ID: U12345\n查询日期: 2026-04-08\n数据摘要: 用户当日业务数据:订单数5,消费金额200元\n生成时间: 2026-04-08\n报告类型: summary'}
四、技术细节
1. 多维度触发规则实现
传统智能体只支持关键词匹配,比如只有输入“查询数据”才调用对应功能。SKILL架构支持4维精准匹配:
应用价值:复杂场景下,比如用户模糊提问、上下文关联任务场景,可以精准调用SKILL,不混淆、不错误。
2. 技能依赖链调度实现

执行逻辑:自动按依赖顺序执行,前一个SKILL失败则终止,保证任务逻辑正确性。
五、总结
SKILL架构本质上就是把传统耦合严重、改一点动全身的智能体,彻底改成了插件化、可拼装、易维护的工程化系统。它通过原子化拆分把每个功能拆成独立SKILL模块,再用标准化封装统一输入输出、触发规则和依赖管理,直接解决了传统智能体扩展难、复用低、维护麻烦的痛点,真正做到了像搭乐高一样搭建智能体。
好的AI架构从来不是堆功能,而是解耦、规范、可扩展。大模型负责理解和决策,SKILL负责执行和落地,分工清晰才是落地的关键。初次接触的话,建议先吃透基类和注册机制,再动手写简单插件,逐步尝试依赖链和热更新。不要一上来就追求复杂流程,先把单个SKILL做标准、做稳定,后续组合起来自然就流畅了。




