时隔多年,在积累了丰富的软件工程实践经验(当然,过程中的疏漏也不少)之后,我们再次将目光聚焦于 Apache Spark——这次的重点是深度解析 Spark AI 技术,探索它在人工智能领域的实际应用。
先来聊聊什么是人工智能。以通义千问为例:AI 并非单一技术,而是一套通过计算机模拟、延伸和拓展人类智能的综合性技术体系。它融合了数学、计算机科学、神经科学等多学科成果,旨在让机器具备学习、推理、感知与决策能力,从而完成那些原本依赖人类智慧才能处理的复杂任务。
那么,Apache Spark 在人工智能方向具体提供了哪些核心组件技术?主要有以下几项:
- MLlib:端到端的大规模机器学习流水线,支持从数据预处理到模型部署的全流程
- 深度学习框架集成:打通数据与计算之间的障碍,实现高效协同
- Spark NLP:工业级自然语言处理工具,专为大规模文本分析场景设计
- 底层架构支撑:为 AI 任务提供高性能执行底座,保障计算效率
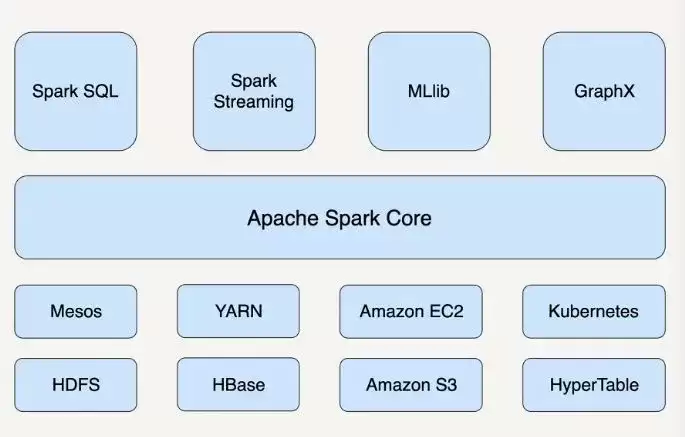
从上图可以清晰看到,Spark 的核心组件包括 Spark SQL、Spark Streaming、MLlib、GraphX 以及底层引擎 Apache Spark Core。此前我在博客中已详细剖析过 Spark SQL、Spark Streaming 和 Spark Core 的运行机制,也分享了大量关于 YARN 集群与 HDFS 的实战经验——这些都属于 Spark 生态的老本行。
这次算是一个全新的起点,主攻方向是 Spark AI 的新模块与前沿特性。明天继续,朋友们~




