在深度学习领域,TensorFlow 是最为广泛使用的框架之一,而模型训练则是构建高效模型的核心环节。本文将从梯度下降、优化器以及批量训练三个关键角度出发,帮助你系统梳理 TensorFlow 模型训练的基本流程与核心要点。
【TensorFlow系列教程第五章】TensorFlow 模型训练全解析
 在这里插入图片描述
在这里插入图片描述
一、梯度下降
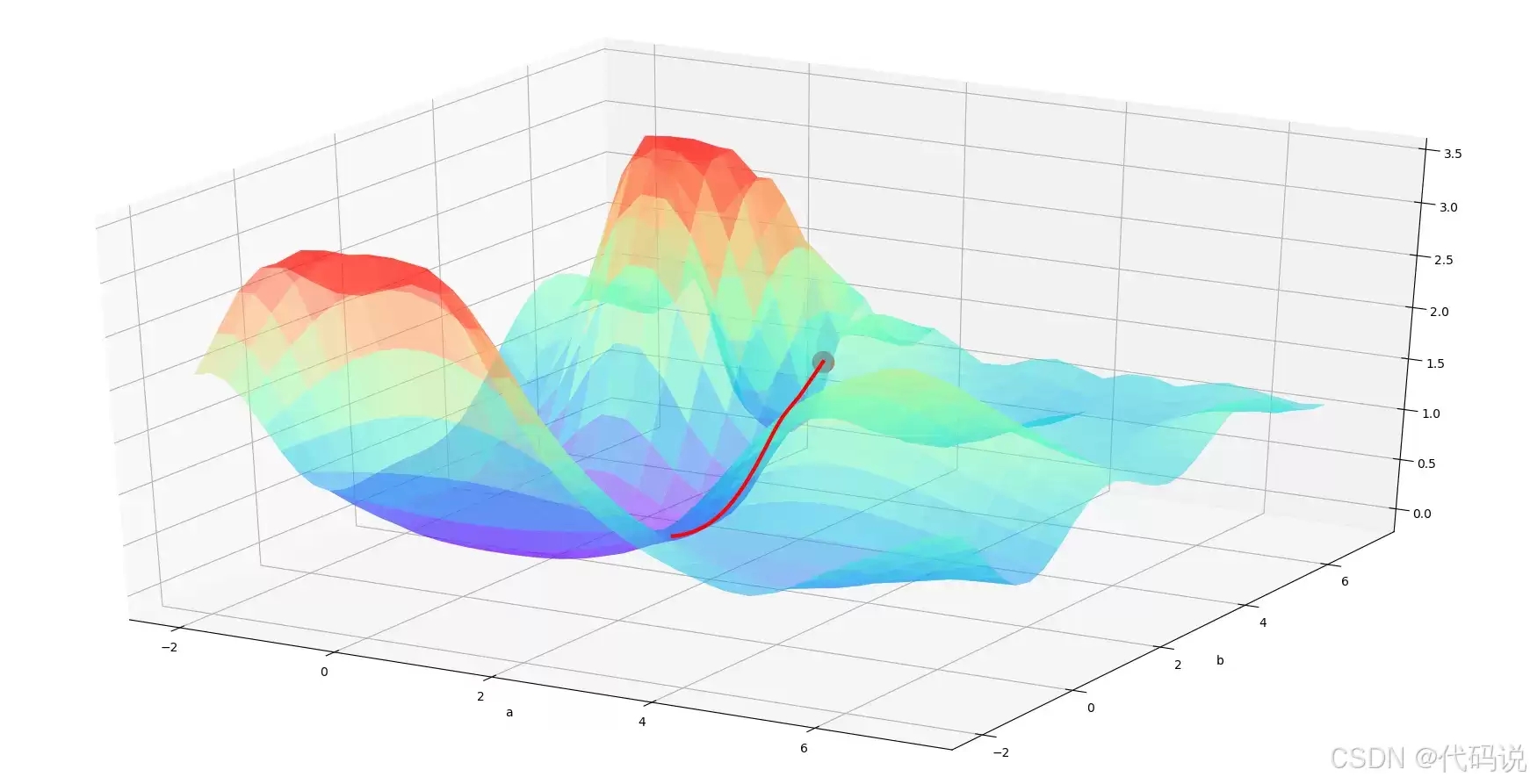 在这里插入图片描述
在这里插入图片描述
(一)基本原理
梯度下降是机器学习中最经典的优化算法之一,其核心目标非常明确——通过最小化损失函数来更新模型参数。简单来说,它沿着损失函数梯度的反方向逐步调整参数,使损失值不断下降,最终收敛到一个相对理想的状态。
(二)基于 TensorFlow 的实现步骤
首先导入必要的库:
import tensorflow as tf这一步直接引用 TensorFlow 即可,无需额外操作。
接下来定义模型参数:
# 初始化模型参数
w = tf.Variable(tf.random.normal(shape=(2,1)), name='weight')
b = tf.Variable(tf.random.normal(shape=(1,)), name='bias')这里我们分别定义了权重 w 和偏置 b,通过随机正态分布完成初始化,并为它们命名以便后续操作。
然后定义损失函数:
def loss(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))该函数用于量化预测值与真实值之间的差异,采用了均方误差(MSE)作为损失度量,并返回当前的损失值。
再定义训练步骤:
def train_step(X, y, learning_rate=0.01):
with tf.GradientTa pe() as tape:
y_pred = tf.matmul(X, w) + b
current_loss = loss(y, y_pred)
dw, db = tape.gradient(current_loss, [w, b])
w.assign_sub(learning_rate * dw)
b.assign_sub(learning_rate * db)
return current_loss利用 GradientTa pe 记录梯度信息,先计算预测值和对应的损失,再获取损失对参数的梯度,最后根据学习率更新参数,并返回当前的损失值。
开始训练:
X_train = # 输入数据
y_train = # 标签数据
num_epochs = 100
for epoch in range(num_epochs):
current_loss = train_step(X_train, y_train)
print(f'Epoch {epoch}, Loss: {current_loss.numpy()}')将数据输入模型,通过循环迭代逐步优化参数。每个 epoch 都会输出当前损失值,帮助观察收敛情况。经过多次迭代,模型参数会不断优化,效果逐步提升。
二、优化器
(一)作用与重要性
在 TensorFlow 中,优化器是专门用于更新参数并最小化损失的工具。不同优化器具有各自的特点,选择合适的优化器能够显著加快收敛速度,并提升模型的整体性能。常见的优化器包括梯度下降、Adam、RMSProp 等。
(二)示例演示
首先导入库和模块:
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers这次额外引入了构建模型和选择优化器所需的内容。
定义一个简单的模型:
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])这是一个简单的全连接神经网络结构:首先将输入扁平化,然后连接两个全连接层,激活函数分别选用 relu 和 softmax。
定义损失函数和优化器:
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = optimizers.Adam()对于分类任务,选择稀疏分类交叉熵作为损失函数;优化器方面采用了性能出色的 Adam。
编译模型:
model.compile(loss=loss_fn, optimizer=optimizer, metrics=['accuracy'])将损失函数、优化器以及评估指标(准确率)关联在一起,为后续训练做好准备。
加载数据并进行训练:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model.fit(x_train, y_train, epochs=5)使用 MNIST 数据集,对数据做归一化处理后直接通过 fit 方法启动训练,共进行 5 轮迭代。在训练过程中,优化器会根据损失计算结果动态更新参数,引导模型逐步收敛。
在实际应用中,需要根据问题的性质和数据集的特性谨慎选择优化器,同时可以通过调整超参数(如学习率)来挖掘模型的潜力。TensorFlow 提供了丰富的优化器选项,赋予开发者极大的灵活性。
三、批量训练
(一)概念与优势
批量训练是 TensorFlow 中一种高效的训练方式——每次使用多个样本同时更新模型参数。相比于逐个样本的训练方式,批量训练不仅能够加快计算速度,还能提升模型的泛化能力,使模型在面对新数据时表现更加稳定。
(二)详细教程
首先导入库:
import tensorflow as tf
import numpy as np使用 TensorFlow 配合 Numpy 进行数据处理。
准备训练数据:
# 生成随机的训练数据
X_train = np.random.rand(100, 10)
y_train = np.random.randint(0, 2, size=(100, 1))随机生成 100 个样本,每个样本包含 10 个特征,标签为二分类,用于模拟一个简单的训练场景。
构建模型:
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])构建一个包含两个全连接层的网络,中间层使用 relu 激活函数,输出层使用 sigmoid 激活函数,适用于二分类任务。
编译模型:
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])采用 Adam 优化器,损失函数选择二元交叉熵,评估指标为准确率。
执行批量训练:
batch_size = 32
num_batches = len(X_train) // batch_size
for epoch in range(10):
for i in range(num_batches):
start = i * batch_size
end = (i + 1) * batch_size
X_batch = X_train[start:end]
y_batch = y_train[start:end]
model.train_on_batch(X_batch, y_batch)
print('Epoch {}, Loss: {}, Accuracy: {}'.format(epoch, loss, accuracy))首先设定 batch_size 为 32,并计算出需要迭代的批次数。在每个 epoch 中,遍历所有批次,使用 train_on_batch 方法更新模型参数,同时打印当前 epoch 的损失和准确率,以便监控训练效果。
通过以上步骤,可以在 TensorFlow 中顺利实现批量训练模型。希望这些内容能够帮助你在模型训练过程中更加得心应手。如果在实践中遇到任何问题,欢迎随时交流探讨。




