一、核心概念
1. 基础定义
先聊一个大家既熟悉又容易混淆的概念——大模型智能体。不像是我们平时在网页上点开的那种个人聊天助手,虽然背后也是大模型,但智能体承载的是正经的业务服务系统。金融客服、政务审批、工业调度、医疗辅助,这些都是它的战场,要求7×24小时不中断、零业务中断、高稳定性、可追溯、可管控。
这类智能体的核心能力,其实是由一个个Skill技能“扛”起来的。举个例子:金融智能体里面的“账单查询Skill”和“风险预警Skill”,政务智能体里的“证照办理Skill”和“政策解读Skill”,每一个都是具体业务逻辑的载体。

1.2 Skill技能
Skill是大模型智能体最小的功能模块,同时也是核心执行单元。它本质上是封装了业务逻辑、大模型调用规则、工具接口(数据库、API、文件系统)的可执行代码或配置。
说白了,一个智能体 = 多个Skill的组合;新增一个功能,就加一个Skill;修复一个问题,就改对应的Skill;下线一个功能,就删掉那个Skill。在传统架构里,Skill跟智能体核心服务是强绑定的—改任何一个Skill,都得把整个系统重启一遍,业务自然就中断了。
1.3 Skill热更新
所谓热更新,简而言之就是不停服的动态更新。不用重启智能体核心服务,不打断用户的请求,只针对目标Skill进行加载、修改或卸载。这种更新方式的最大价值在于:更新期间,用户完全无感知,业务零中断,这对于金融、工业、政务这些对高可用有严格要求的场景来说,是硬性刚需。
1.4 灰度发布
灰度发布听起来有点陌生,但它的逻辑其实很直白:把更新后的新Skill,先定向推送给少量指定用户(我们叫灰度用户)。跑一段时间,盯着成功率、响应时间、错误率这些指标,确认一切正常了,再全量推广给所有用户。先在小范围内验证,能有效规避全量发布可能带来的风险。
1.5 技能回滚
回滚就更不用说了,是用来兜底的。一旦新发布的Skill出了问题,一键切换回历史稳定版本,其他Skill完全不受影响,做到快速止损,保障系统稳定性。核心价值就四个字:快速恢复。
2. 应用价值
2.1 传统智能体的致命短板
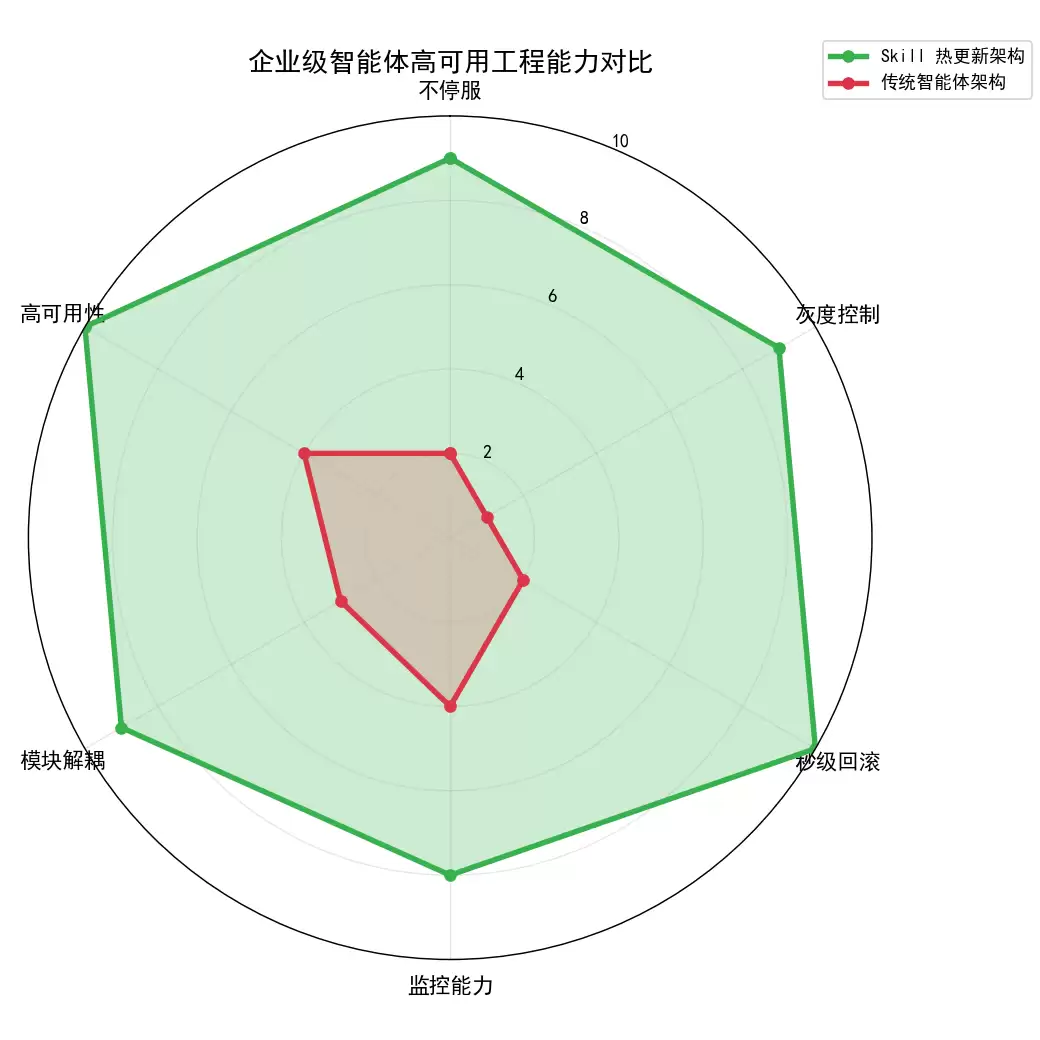
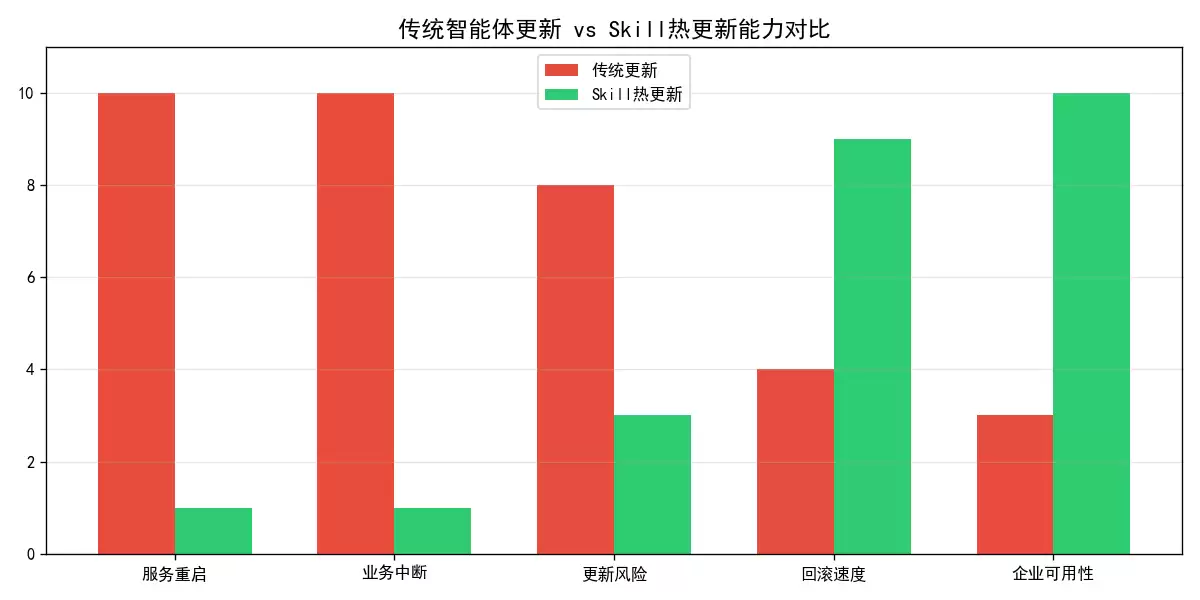
传统智能体的问题很明显:更新必停机。改一个很小的Bug,系统就得重启一次。在政务、金融场景里,停机一分钟,损失可能就是以十万计了。更麻烦的是,全量更新风险极高—新功能直接推给所有用户,一旦出错,全员“陪葬”。而且也没有应急回滚的能力,更新失败后只能回退代码再重启,耗时久、影响大。这哪还能满足企业级的高可用、高稳定性、可管控的需求。
2.2 Skill热更新 + 灰度发布的核心价值
这套组合拳的价值是实实在在的:高可用(7×24小时不停工,更新零停机)、高安全(灰度验证,全量发布无风险)、高灵活(单一Skill独立更新或回滚,不影响其他功能)、可观测(全流程监控,更新状态可追溯)。而且一旦脱离单一场景,这套方案能适配所有企业级智能体。
3. 对大模型的意义
大模型是智能体的大脑,负责理解用户意图、生成执行指令;而Skill是智能体的手脚,负责落地执行具体的业务。把大模型核心和业务逻辑解耦,大模型服务不用频繁重启,只需要更新业务Skill,这就保护了大模型核心服务的稳定性。同时还能提升大模型落地的效率—业务需求快速迭代,不用等系统重启,上线周期大大缩短。更重要的是,增加了大模型整体的可靠性,有了灰度和回滚机制,业务Bug不会反过来影响大模型的核心服务。最终实现真正意义上的企业级工程化,让大模型成为生产级的核心系统,满足最严苛的行业要求。
二、基础原理
1. 核心架构原理
Skill热更新和灰度发布的核心原理,可以概括为六个字:分层解耦 + 动态注册 + 策略路由。拆开说就是解耦与动态管理。整体架构分为4层:
- 接入层:接收用户请求,解析用户身份,判断是否为灰度用户。
- 路由层:根据灰度策略,把请求分发到对应版本的Skill。
- Skill注册中心:统一管理所有Skill的版本、状态和配置。
- 执行层:加载并运行Skill,调用大模型与工具接口。
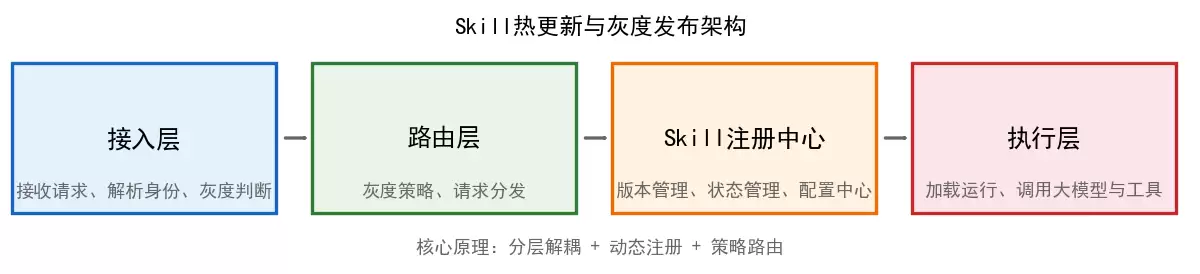
核心原理:智能体核心服务只保留“请求接收、路由调度、监控上报”这几项能力。Skill作为独立模块动态加载到内存,而不是编译绑定到核心服务中。更新的时候,只需要替换内存里的Skill模块,核心服务完全不用中断。
2. 核心组件详解
2.1 SkillRegistry(技能注册中心)——核心大脑
作用:统一存储、管理所有Skill的元数据,包括名称、版本、路径、依赖和灰度策略。功能涵盖Skill的注册、注销、查询、版本管理。技术细节上,基于内存结合持久化存储(Redis/MySQL)实现,支持高并发查询,同时支持热加载监听。
2.2 DynamicLoader(动态加载器)——热更新执行单元
作用:从文件或仓库中加载Skill代码到内存,卸载旧版本Skill。技术细节上,支持Python importlib、Ja va ClassLoader等动态加载机制,并支持沙箱隔离,避免Skill之间相互影响。
2.3 GrayRouter(灰度路由器)——灰度分发核心
作用:根据用户ID、部门、区域等规则,匹配灰度策略,分发请求。支持白名单、百分比、标签三种灰度模式,规则实时生效,不用重启。
2.4 Monitor(监控器)——发布决策依据
作用:实时采集Skill的运行指标,包括成功率、响应时间、错误率、大模型调用耗时。指标上报到Prometheus/Grafana,异常自动告警,支持灰度自动终止或回滚。
2.5 VersionControl(版本控制器)——回滚核心
作用:存储Skill的所有历史版本,记录版本变更日志。版本号递增管理,回滚时直接加载历史版本,秒级生效。
三、执行流程
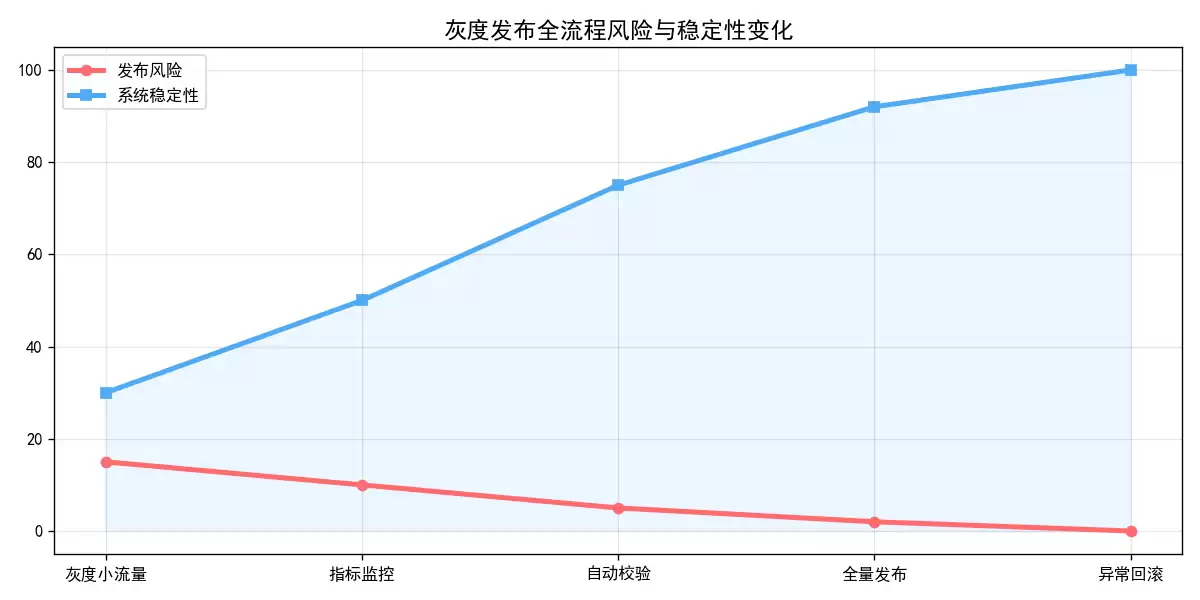
这个流程的核心目标,是实现Skill的平滑升级。新Skill独立开发并注册后,通过白名单、百分比或标签三种方式配置灰度规则,先在小范围用户中运行,监控成功率和响应时间。达标了,全量发布;出现异常,自动回滚到历史版本,确保服务稳定性。

流程说明:
步骤1:Skill开发与打包
开发者编写新Skill或修改旧Skill,测试完成后,打包为独立模块(.py文件或.json配置文件),上传到Skill仓库。关键前提:Skill必须独立无耦合,不依赖智能体核心服务的内存数据。
步骤2:Skill注册与版本录入
将新Skill的信息(名称、版本、路径、灰度规则)录入SkillRegistry,注册中心标记为“待发布”状态。版本号遵循“主版本.次版本.修订号”的惯例,例如1.0.0到1.0.1,自动关联历史版本。
步骤3:灰度发布配置
管理员配置灰度规则,有三种模式可选:白名单(按用户ID或部门)、百分比(例如10%的用户)、标签(例如政务内网用户、金融VIP用户)。配置完成后,GrayRouter实时加载规则。
步骤4:灰度运行与监控
灰度用户的请求进入系统后,路由层匹配规则,分发到新Skill。Monitor开始实时采集指标。判断标准:连续5分钟成功率100%、响应时间≤500ms、无错误,就可以全量发布;一旦出现异常,自动触发回滚。
步骤5:全量发布/异常回滚
全量发布时,关闭灰度规则,所有用户的请求都路由到新Skill。异常回滚时,路由层切回历史版本Skill,卸载新Skill,标记异常并记录日志。
四、应用实践
1. 完整的项目结构
skill_agent_hotupdate/
├── main.py # 主入口:执行热更新、灰度、回滚全流程
├── requirements.txt # 项目依赖清单
├── skills/ # 所有技能 Skill 存放目录(热更新核心目录)
│ ├── bill_query_v1_0_0.py # 账单查询技能 - 稳定旧版本
│ └── bill_query_v1_0_1.py # 账单查询技能 - 待灰度新版本
├── core/ # 核心架构模块
│ ├── __init__.py
│ ├── skill_registry.py # Skill 注册中心 SkillRegistry
│ ├── dynamic_loader.py # 动态加载器(热更新核心)
│ ├── gray_router.py # 灰度路由策略
│ ├── monitor.py # 技能运行指标监控
│ └── rollback.py # 版本回滚管理器
├── config/ # 配置文件
│ ├── __init__.py
│ └── redis_config.py # Redis 连接配置
└── logs/ # 运行日志、发布记录、回滚记录(自动生成)
├── skill_metrics.log
└── rollback_history.log
2. 文件完整代码
2.1 requirements.txt
redis>=5.0.0
psutil>=5.9.0
matplotlib>=3.7.0
2.2 主入口 main.py
整合所有模块,负责执行注册Skill → 热加载 → 灰度路由 → 监控 → 全量发布 → 模拟回滚。

2.3 Redis连接配置:config/redis_config.py
统一管理Redis、端口、灰度策略阈值等,便于生产环境修改。
2.4 Skill注册中心:core/skill_registry.py
Skill注册中心:版本管理、状态管理、元数据存储。
2.5 热更新核心:core/dynamic_loader.py
动态加载器:动态importlib重载,实现Skill热更新,不停服重载。

2.6 灰度路由:core/gray_router.py
灰度路由器:根据用户身份分配版本。

2.7 监控:core/monitor.py
技能监控:采集成功率、响应时间、错误率。

2.8 回滚:core/rollback.py
回滚管理器:异常时快速恢复历史版本。

2.9 稳定版技能:skills/bill_query_v1_0_0.py

2.10 灰度新版技能:skills/bill_query_v1_0_1.py

2.11 运行日志:logs/skill_metrics.log

3. 运行结果
============================================================
? 企业级智能体 Skill 热更新与灰度发布系统启动
============================================================
? 步骤0:初始版本调用测试(更新前)
✅ 技能【bill_query】热加载成功:./skills/bill_query_v1_0_0.py
[初始版本 v1.0.0] 调用结果: 【v1.0.0】用户 user_test 当前账户余额:10000 元
? 步骤1:注册新版本 Skill(灰度发布中)
? 步骤2:动态热加载 Skill(不停服)
✅ 技能【bill_query】热加载成功:./skills/bill_query_v1_0_1.py
? 步骤3:灰度路由分发测试
[灰度用户] user001 → 路由到【新版本 1.0.1】
[普通用户] user003 → 路由到【稳定旧版本 v1.0.0】
? 步骤4:实时监控 Skill 运行指标
? 监控指标 2026-04-07 20:48:11:
success_rate: 100%
response_time: 0.28s
error_rate: 0%
cpu_usage: 5.0%
==================================================
✅ 灰度验证无异常,执行全量发布
==================================================
? 技能【bill_query】状态已更新:online
? 当前版本调用测试: 【v1.0.1】用户 test_user 余额:10000 元 | 本月账单已自动分期
==================================================
⚠️ 模拟新版本异常,触发自动回滚
==================================================
⏪ 开始回滚技能【bill_query】到版本 1_0_0
✅ 技能【bill_query】热加载成功:./skills/bill_query_v1_0_0.py
✅ 回滚完成:【bill_query】已恢复至稳定版本 1_0_0
? 步骤7:回滚后验证 - 调用不同版本Skill
✅ 技能【bill_query】热加载成功:./skills/bill_query_v1_0_0.py
[回滚后-旧版本 v1.0.0] 调用结果: 【v1.0.0】用户 user_test 当前账户余额:10000 元
[新版本 v1.0.1] 调用结果: 【v1.0.1】用户 user_test 余额:10000 元 | 本月账单已自动分期
? 回滚后路由验证:
[任意用户] user001 → 路由到【全量版本 1.0.0】
============================================================
? 全流程执行完成:热更新 → 灰度 → 全量 → 回滚 → 验证
============================================================
五、总结
Skill架构的热更新与灰度发布,本质上就是给企业级智能体装上了“不停服、更安全、可反悔”的工程化能力。传统智能体改个功能、修个Bug都得重启服务,一停机就影响业务,在金融、政务、工业这些对可用性要求极高的场景里,确实扛不住。而这套方案通过SkillRegistry实现技能动态加载,新增、修改、删除单个技能都不用重启核心服务,真正做到无感升级。
再配合灰度发布,先把新技能放给小部分用户试用,一边跑一边盯着成功率、响应速度、错误率这些关键指标,没问题再逐步全量上线,避免一个小Bug波及所有用户。万一新版本出了问题,还能快速回滚到历史稳定版本,而且只影响有问题的那个技能,其他功能照常运行,把风险降到最低。
整体来看,这套机制不仅解耦了大模型核心和业务技能,还让智能体具备了企业级的高可用水准,能够轻松适配各类严苛场景。无论是在迭代效率、运行稳定性还是风险控制方面,都彻底解决了传统架构“更新必停机”的痛点,让大模型智能体真正能够稳定落地到生产环境中。




