Codex CLI 是 OpenAI 推出的终端 AI 编程袋里,靠 GPT 系列模型在命令行里完成代码生成、调试、重构这些活儿。它的核心能力由九个模块撑起来:AGENTS.md(项目指令)、沙箱与审批(安全隔离)、配置集(Profile,场景切换)、MCP(工具连接)、钩子(Hooks,自动化触发)、技能(Skills,可复用工作流)、无界面模式(headless,自动化执行)、上下文管理,还有和 Claude Code 的选型协作。
问题在于,很多人装好 Codex 就直接开干,基本没认真配置过这九个模块。结果就是:它不知道你项目的约定,沙箱模式跟场景对不上,每次操作都要弹窗确认,干完活也不验证就交差——能用,但绝对谈不上好用。
这篇文章,咱们就按模块一个个拆。每个模块,我会告诉你该配什么、为什么这么配、最实用的用法是什么。如果你已经用过 Codex 了,看完这篇应该能直接让你的配置升个级。要是你刚接触,可以先看看 Codex 是个啥,再了解一下它的全貌。至于到底用 CLI、App 还是云端,这得看你自己怎么选。
一、AGENTS.md — 项目指令
AGENTS.md 是 Codex 的指令文件,相当于 Claude Code 的 CLAUDE.md。它决定了 Codex 知不知道你的项目约定、遵守哪些编码规范、按什么流程干活。每次会话启动时,Codex 会自动搜索并拼接所有层级的 AGENTS.md,构建出一套完整的指令链。
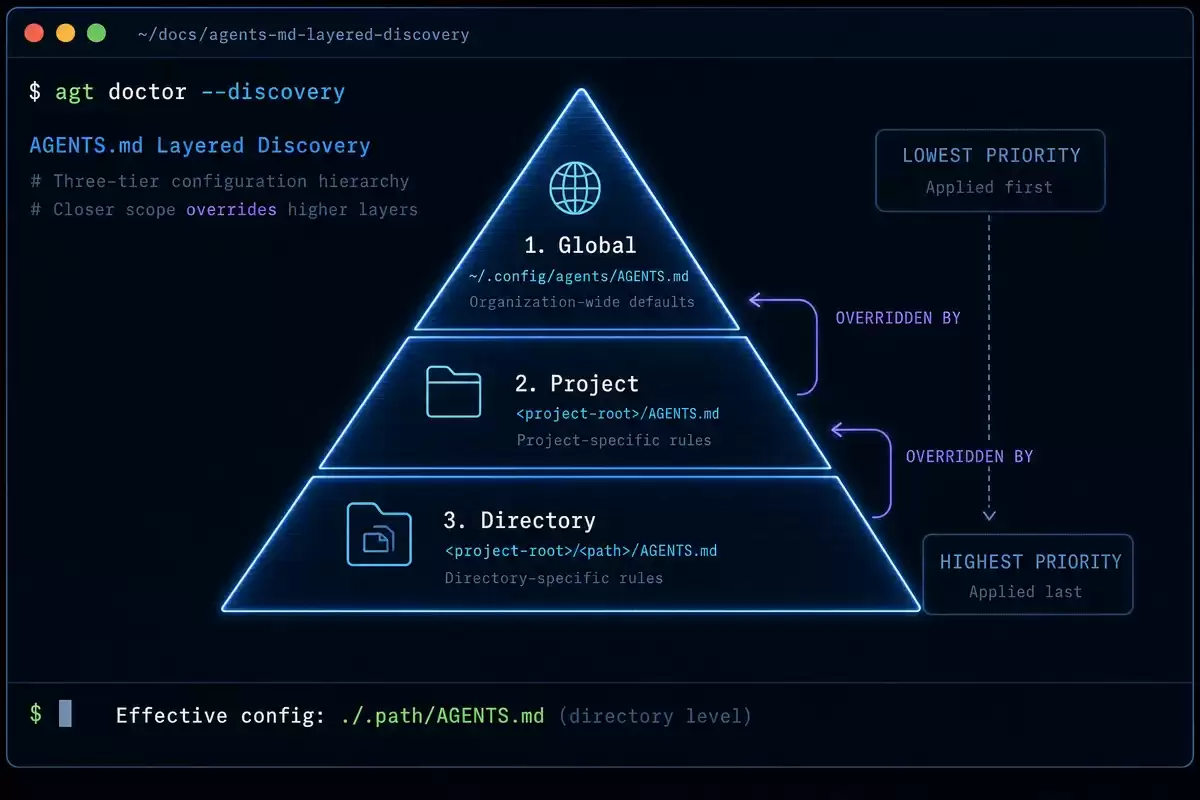
三层发现机制
Codex 的指令文件遵循从全局到局部的层级覆盖规则。这个逻辑和 CSS 的优先级很像——越具体的选择器(目录越深),优先级越高。
第一层是全局作用域,放在 ~/.codex/ 目录下,用来写你所有项目通用的个人偏好。如果同时存在 AGENTS.override.md 和 AGENTS.md,override 版本会优先——它就像 CSS 里的 !important。
第二层是项目作用域,从 Git 仓库根目录开始,逐层检查每个目录里有没有 AGENTS.md。子目录越深,指令就越具体。比如 src/api/AGENTS.md 比根目录的 AGENTS.md 优先级更高,你可以在里面写只适用于 API 模块的规则。
第三层是备选文件名(Fallback)。你可以在 config.toml 的 project_doc_fallback_filenames 字段里配一个备选文件名列表,比如 CLAUDE.md、CODEX.md、CURSOR.md。这意味着如果项目里已经有 CLAUDE.md,Codex 同样会读取——一份指令文件就能兼容两个袋里。
设计原则
指令文件最好控制在 10 条核心要点以内。虽然 Codex 支持最大 32KB(可以通过 project_doc_max_bytes 调到 64KB),但指令太长会稀释重点。Claude Code 社区的实测数据也验证了:指令文件越长,袋里的遵循度就越低。稳定规则放在 AGENTS.md 里,具体的长规范可以下沉到引用文件,让 Codex 按需读取。
只写必要信息。比如项目名、技术栈(像 Next.js 15 + TypeScript + Tailwind CSS)、构建与测试命令、编码约定(ESM 优先、函数单一职责、类型声明完整),还有禁止事项(禁止硬编码密钥、禁止创建没要求的新文件、禁止主动重构不相关的代码)。每个板块用二级或三级标题隔开,整体控制在一页内。
不应包含的内容有:完整的风格指南(用文件路径引用代替)、密钥或凭据(用环境变量)、模糊的鸡汤指令(比如“写出优雅的代码”)。这些要么浪费上下文空间,要么根本没有可执行性。
Override 的实战用法
AGENTS.override.md 在任意层级都优先于同层的 AGENTS.md,典型的三个场景:
临时全局覆盖——在 ~/.codex/AGENTS.override.md 里写入临时规则(像调试期间禁止修改某个目录),完成后删掉就行,不用动版本控制里的正式指令文件。
团队子目录覆盖——services/payments/AGENTS.override.md 可以为支付模块设定更严格的安全规则,团队其他成员的全局规则不受影响。
多袋里兼容——通过 project_doc_fallback_filenames 让 Codex 识别 CLAUDE.md,实现一套指令文件同时服务 Codex 和 Claude Code。同一个项目不用维护两份指令文件。
想深入了解 CLAUDE.md 的写法(也适用于理解 AGENTS.md 的设计思路),可以看 CLAUDE.md 最佳实践。
实战提示词
审计现有 AGENTS.md,或者从零生成 AGENTS.md。
→ 深入阅读:AGENTS.md 新手指南 · CLAUDE.md 最佳实践
二、沙箱与审批 — 安全隔离
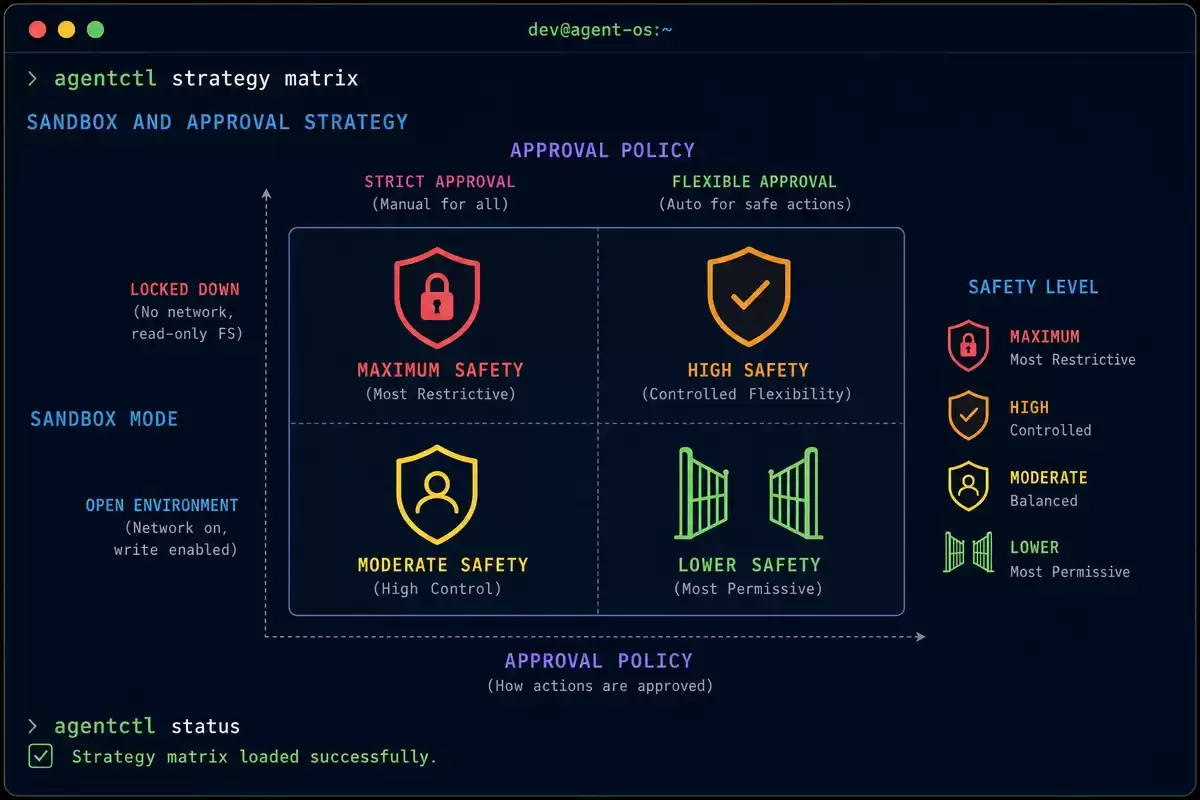
Codex 的安全模型由两个独立维度构成:沙箱(sandbox)控制系统资源访问,审批(approval)控制执行确认流程。两个维度可以自由组合,产生不同的安全等级。这是 Codex 和 Claude Code 最大的架构差异之一——Claude Code 没有操作系统级的原生沙箱。
沙箱模式
Codex 提供内核级沙箱保护,macOS 用 Seatbelt,Linux 用 Landlock。两个模式可选:
workspace-write(默认)——Codex 只能写入当前工作目录,网络访问被禁用。日常开发首选这个模式,安全性最高。但要注意,网络被禁意味着 Python 脚本调用外部 API 会失败,npm install 这类网络操作也会失败。
danger-full-access——全磁盘读写,网络全开。适用于知识库管理、跨目录批量操作、需要调用外部 API 的场景。名字里带“danger”就是提醒你:这个模式下 Codex 有权访问整台机器的所有文件。
审批策略
审批策略控制 Codex 执行操作前是否需要你确认:
untrusted——每个操作都要确认。适用于审阅不信任的外部代码,或者让 Codex 分析你不熟悉的项目。
on-request(默认)——按需确认。Codex 自己判断哪些操作需要确认,哪些可以直接执行。日常交互开发的最佳平衡点。
never——完全不确认,所有操作自动执行。适用于自动化脚本、持续集成(CI/CD)环境和无人值守场景。
组合策略决策表
| 场景 | 沙箱模式 | 审批策略 | 说明 |
|---|---|---|---|
| 日常开发 | workspace-write | on-request | 沙箱保护 + 按需审批,最安全的日常组合 |
| 快速迭代 | workspace-write | never | 等同 --full-auto 标志 |
| 知识库批量操作 | danger-full-access | never | 全磁盘 + 无审批,最高效但风险最大 |
| 审阅外部代码 | workspace-write | untrusted | 每步确认,安全第一 |
CLI 还提供了两个快捷标志:--full-auto 等同 workspace-write 沙箱加无审批;--yolo(--dangerously-bypass-approvals-and-sandbox 的别名)等同 danger-full-access 加无审批。
网络限制的应对
默认 workspace-write 模式下网络被禁用,会导致依赖网络的操作失败。三种应对方案:
切换到 danger-full-access——最直接,但安全性最低。
将网络操作封装为 MCP 工具——最推荐的方案。MCP 进程运行在沙箱外部,天然不受网络限制。把需要联网的操作做成 MCP 工具,沙箱模式不用改,安全和功能兼得。
使用 --full-auto 启动——折中方案,沙箱仍限制文件访问但不限网络。
通俗讲:沙箱就像实验室的通风柜——你在里面做化学实验,有害气体出不来。workspace-write 是关着柜门做实验(安全但不方便拿外面的东西),danger-full-access 是打开柜门(方便但要自己注意安全)。
实战提示词
诊断当前安全配置,或者创建安全配置组合。
→ 深入阅读:Codex 沙箱与审批深度指南 · Codex 完整学习指南
三、配置集(Profile)— 场景切换
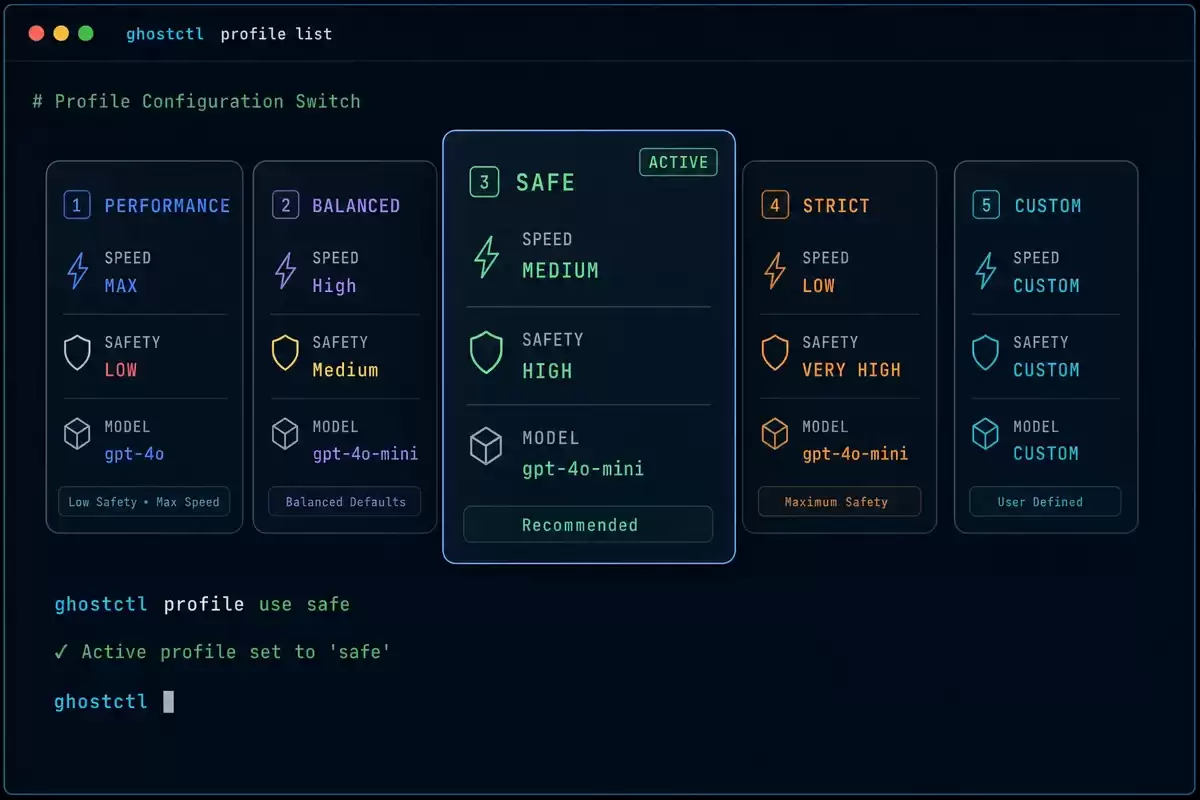
配置集(Profile)是 Codex 的配置快照系统,允许你为不同任务场景预设模型、推理深度、沙箱和审批策略的完整组合。一条命令就能切换所有参数,不用每次手动改 config.toml 再改回来。
推荐五套 Profile
在 config.toml 的 [profiles. 段中定义每套 Profile:
| Profile 名称 | 模型 | 推理深度 | 沙箱模式 | 审批策略 | 适用场景 |
|---|---|---|---|---|---|
| default-55 | gpt-5.5 | high | workspace-write | on-request | 日常主力,深度思考保证质量 |
| kb-full | gpt-5.5 | high | danger-full-access | never | 知识库管理,全磁盘无审批 |
| fast-55 | gpt-5.5 | medium | 默认 | 默认 | 快速迭代,花积分换速度 |
| mini | gpt-5.4-mini | low | read-only | 默认 | 轻量查询,快且省 |
| ci | gpt-5.4 | medium | workspace-write | never | CI/CD 自动化,稳定可预测 |
切换方式:启动时通过 codex --profile 指定。比如 codex --profile kb-full 进入知识库全权限模式,codex --profile mini 进入轻量查询模式。
任务匹配决策表
| 任务类型 | 推荐 Profile | 理由 |
|---|---|---|
| 日常代码修改 | default-55 | 深度推理保证质量 |
| 快速问答 / 检索辅助 | mini | 轻量模型够用,响应快 |
| 大仓跨目录改文档 | kb-full | 免审批 + 全磁盘访问 |
| 大重构 / 疑难调试 | default-55 + xhigh 推理 | 最大推理深度 |
| UI 快速迭代 | fast-55 | 速度优先,1.5 倍加速 |
| CI/CD 无人值守 | ci | API Key 路径稳定,可预测 |
快速模式(Fast Mode)
快速模式让 GPT-5.5 以约 1.5 倍速度运行,代价是消耗 2.5 倍积分。两种启用方式:在 config.toml 的 [features] 段设置 fast_mode = true 并在 Profile 中设置 service_tier = "fast";或者在会话中随时用 /fast on 开启、/fast off 关闭、/fast status 查看状态。
适用于短反馈循环——改样式、调参数、快速验证。复杂迁移或架构设计不建议开——速度提升有限,成本却翻倍。
实战提示词
一键创建五套 Profile,或者诊断 Profile 使用习惯。
→ 深入阅读:Codex 模型与成本指南 · Codex 完整学习指南
四、MCP — 工具连接
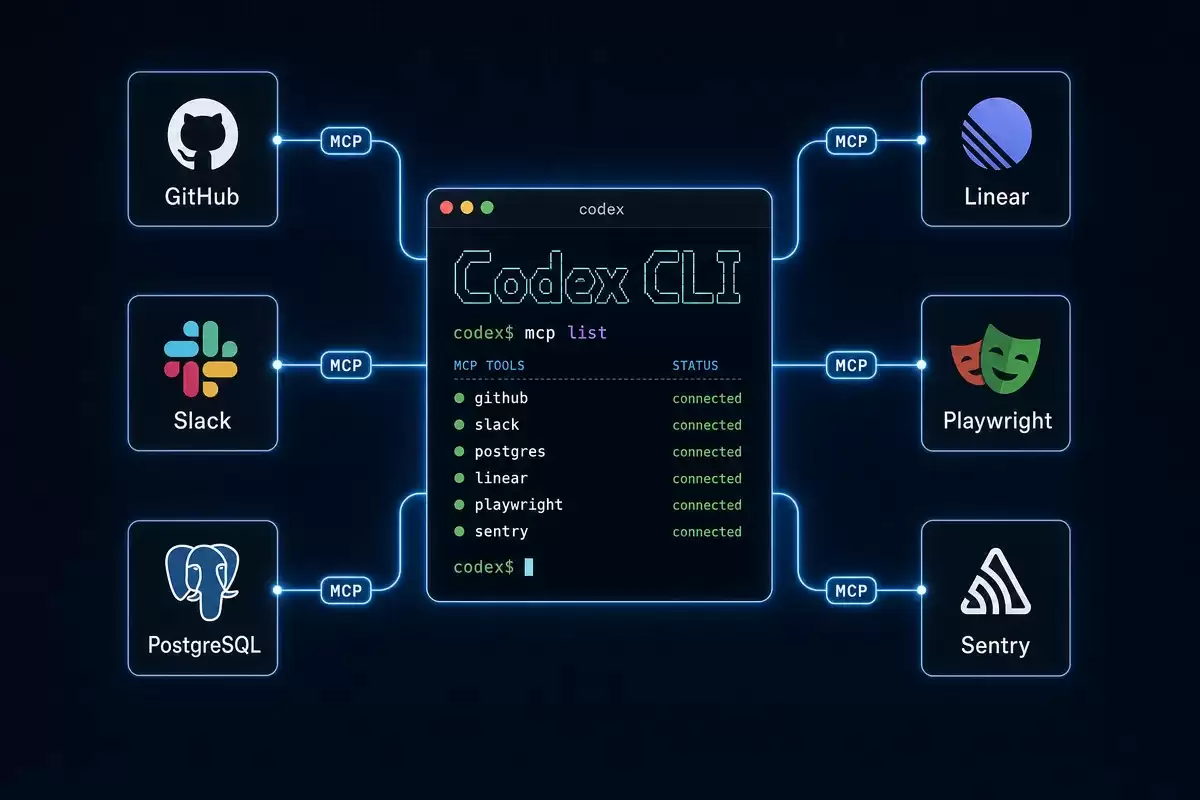
MCP(Model Context Protocol)让 Codex 能调用外部工具服务器——搜索引擎、代码仓库、网页抓取、编程文档查询。没有 MCP,Codex 只能操作本地文件和跑终端命令;有了 MCP,它能搜互联网、读 GitHub 议题、抓网页内容、查最新的库文档。
与 Claude Code 的 JSON 配置不同,Codex 在 config.toml 中用 TOML 段来定义 MCP。配置格式不一样,但解决的问题完全一样。如果你已经配过 Claude Code 的 MCP,这个概念可以直接迁移过来。
通俗讲:MCP 就像 AI 工具的 USB-C 接口。USB-C 让所有电子设备用同一根线连接,MCP 让所有 AI 工具用同一套协议连接外部服务。一个 MCP 服务器写一次,Codex、Claude Code、Cursor 都能用。
两种配置模式
stdio 模式(推荐)——在 config.toml 中指定可执行路径(command)和参数列表(args),通过环境变量白名单(env_vars)声明需要的密钥。MCP 进程在本地启动,通过标准输入输出通信。
HTTP 模式(无需本地进程)——只需填写 url 字段指向远程 MCP 端点。比如 OpenAI 官方文档的 MCP 服务就用这种模式,不需要安装任何本地依赖。
推荐 MCP 清单
以下基于社区热度和实际验证,按优先级排序:
| MCP 服务器 | 解决什么问题 | 为什么选它 | 优先级 |
|---|---|---|---|
| bra ve-search | 搜索互联网获取最新信息 | 中英文搜索效果好,免费额度够个人日常用 | 必装 |
| context7 | 查询编程库的最新 API 文档 | 训练数据可能过时,context7 能保证查到当前版本用法 | 推荐 |
| firecrawl | 抓取网页内容并结构化 | 对 Ja vaScript 渲染的单页应用(SPA)友好 | 推荐 |
| github | 操作代码仓库(拉取请求、议题、代码搜索) | 一个 MCP 覆盖 GitHub 全部操作 | 推荐 |
| openaiDeveloperDocs | OpenAI/Codex/GPT 官方文档 | HTTP 模式,零安装,实时同步官方变更 | 推荐 |
| chrome-devtools | 控制浏览器(含登录态操作) | 需要访问已登录页面时唯一选择 | 按需 |
密钥安全规则
和 MCP 最佳实践中强调的一样,密钥管理是 MCP 配置中最容易出错的环节。
推荐做法:在 config.toml 中只写 env_vars 白名单(比如 env_vars = ["BRA VE_API_KEY"]),密钥明文值放在独立的 env 文件中(权限设为 600,仅自己可读)。
绝对禁止:在 config.toml 的 env 段里直接写明文密钥值,或者在 .zshrc 中 export 密钥——这两种做法都会导致密钥扩散到不该出现的地方。
避免启动卡顿
MCP 启动卡顿是 Codex 常见的体验问题。根本原因通常是用了 npx 动态下载:每次启动时 npx 会解析最新版本并下载,多等 2-5 秒。正确做法是先全局安装到固定路径,config.toml 中直接指向安装后的可执行文件。
另一个常见原因是 ~/.npm/_npx 缓存目录膨胀或权限问题。可以把 npm 缓存固定到 ~/.codex/npm-cache,避免和系统其他 Node 进程冲突。
Codex 本身作为 MCP 服务器
一个很多人不知道的能力:Codex 可以反向暴露为 MCP 服务器——运行 codex mcp 即以 stdio MCP 服务器模式启动。这意味着你可以在 Claude Code 中通过 MCP 调用 Codex,或在 OpenAI Agents SDK 中将 Codex 作为工具节点。两个袋里互相调用,各取所长。
实战提示词
一键配置推荐 MCP 组合,或者审计现有 MCP 配置。
→ 深入阅读:Codex MCP 集成指南 · MCP 最佳实践 · Claude Code MCP 新手指南
五、钩子(Hooks)— 自动化触发
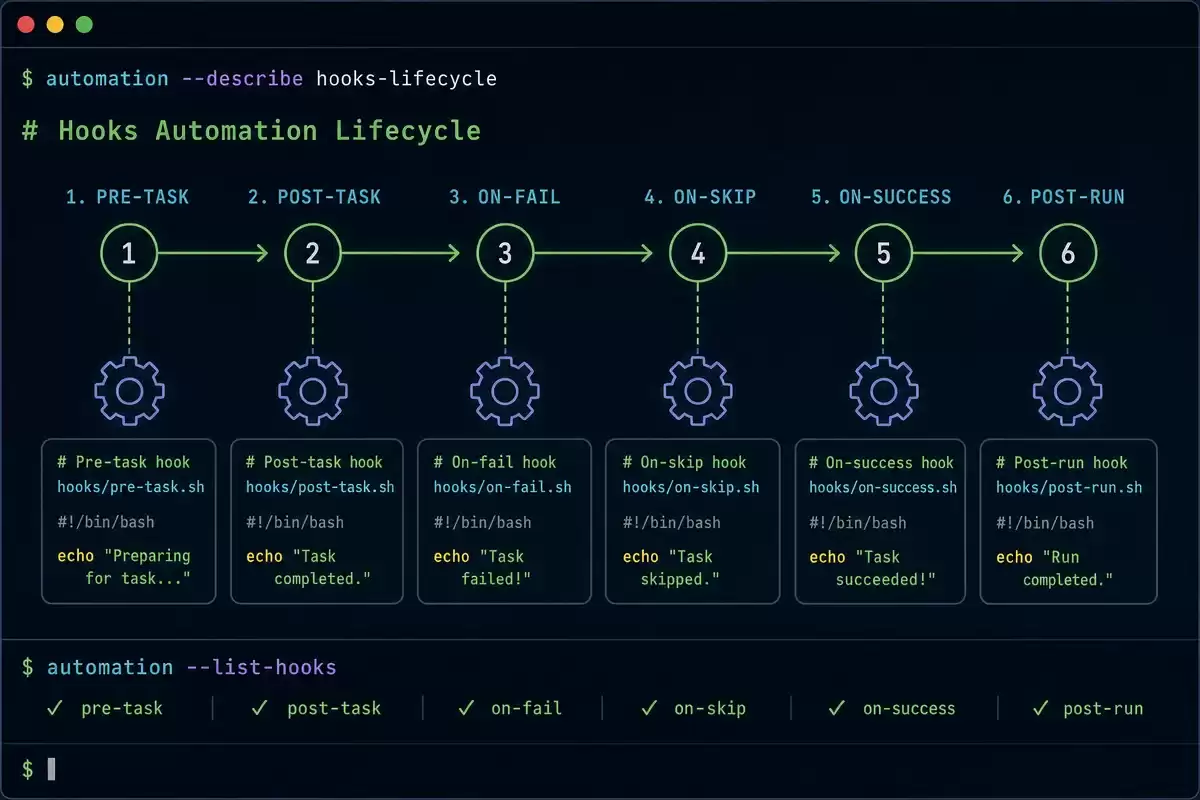
钩子(Hooks)是挂在 Codex 工作流特定节点上的自动化脚本——每当 Codex 执行到这个节点(比如准备调用工具、准备停止工作),钩子脚本就自动触发。Codex 引入了完整的钩子系统,与 Claude Code 的 Hooks 几乎一一对应。
和 AGENTS.md 的本质区别在于:AGENTS.md 是建议,钩子是强制。AGENTS.md 里写“禁止执行危险命令”,Codex 大部分时候会遵守,但复杂场景中可能为了走捷径而忽略。但如果你把同样的规则做成 PreToolUse(工具调用前)钩子,Codex 物理上就执行不了被禁止的命令,不管它多想这么做。
启用方式
在 config.toml 的 [features] 段中设置 hooks = true 启用。钩子脚本注册在 ~/.codex/hooks.json 中,按事件名分组。
六大事件
| 事件 | 触发时机 | 典型用途 |
|---|---|---|
| SessionStart | 会话启动、恢复或清空时 | 加载项目上下文 |
| UserPromptSubmit | 用户提交提示词前 | 注入当前时间 |
| PreToolUse | 调用工具前 | 拦截危险命令 |
| PermissionRequest | 请求权限时 | 自定义审批逻辑 |
| PostToolUse | 工具执行完毕后 | 审计日志、自动代码检查 |
| Stop | 任务完成时 | 发送通知、验证测试 |
最实用的三个钩子
UserPromptSubmit — 时间注入
Codex 不知道“现在几点”。如果你的任务和时间相关(比如“帮我检查今天的日志”),Codex 会猜一个时间或者直接忽略。挂一个 UserPromptSubmit 钩子,每次提交提示词时自动注入当前时间和时区,Codex 就能准确理解时间上下文了。
脚本逻辑极简:获取系统时间,格式化后输出一个 JSON 对象,包含钩子事件名和时间字符串。几乎所有认真配置 Codex 的人都会装这个。
PreToolUse — 危险命令拦截
在 Codex 执行任何工具之前触发。脚本读取即将执行的命令,与预定义的危险模式列表(如 rm -rf /、mkfs、dd if= 等)逐一比对。匹配到就返回拒绝决策,阻止执行;未匹配到就放行。
这是 Codex 安全体系的最后一道防线。即使审批策略设为 never,PreToolUse 钩子仍然能拦住你明确禁止的操作。
Stop — 验证 + 通知
Codex 准备停止工作时触发。两个典型用法:一是挂验证脚本,测试没通过就阻止停止、Codex 继续迭代修复——这是无人值守模式(headless)的核心;二是发通知(推送到手机、发消息到聊天工具),让你知道 Codex 干完了。
信任机制
Codex 对未托管的钩子增加了信任审核机制。首次添加或修改钩子后,需要通过 /hooks 命令交互式信任,或在 config.toml 的 [hooks.state] 段中写入 trusted_hash(SHA-256 值),跳过每次启动的信任确认弹窗。
失败开放(fail-open)设计
钩子采用失败开放(fail-open)设计——即使钩子脚本出错(退出码非 0),Codex 的主任务仍会继续执行。这意味着你可以放心添加钩子而不担心破坏工作流。但仍建议在钩子脚本中做防御性编程:try/except 兜底,确保永远返回退出码 0。
实战提示词
一键配置三个核心钩子,或者诊断钩子是否正常工作。
→ 深入阅读:Codex Skills、子袋里与 Hooks 指南 · Claude Code Hooks 新手指南
六、技能(Skills)— 可复用工作流
技能(Skills)是 Codex 的可复用指令模块,用 /skill-name 手动触发或由 Codex 根据描述自动匹配。和 Claude Code 的 Skills 概念相同,但 Codex 对格式有更严格的要求。
文件结构
每个 Skill 存放在 ~/.codex/skills/ 目录下。核心文件是 SKILL.md——由 YAML 文件头元数据(frontmatter)和 Markdown 正文两部分组成。文件头声明名称(name)、功能描述(description),正文写具体的指令和规范内容。
YAML 格式陷阱
Codex 对 SKILL.md 的 YAML 文件头有严格校验,两个常见坑:
name 字段——不超过 64 字符,必须匹配 [a-z][a-z0-9_-]* 模式。不符合的 Skill 会被静默跳过。
description 字段——必须是字符串,不能以方括号开头。比如 description: [已废弃] 合并到其他 skill 会被 YAML 解析器误读为数组导致报错。正确写法是用引号包裹:description: "(已废弃)合并到其他 skill"。
好 Skill 的设计标准
和 Claude Code Skill 的设计标准一致,Codex Skill 也遵循这些原则:
精确的触发描述——description 字段决定了 Codex 什么时候自动激活。“帮助处理代码”太模糊;“用户要求修复 GitHub Issue、创建修复分支并提交 PR 时使用”足够具体。好的描述读起来像一个条件判断语句。
SKILL.md 要精简——内容在手机屏幕上能看完。超过 50 行的 Skill 执行失败率显著上升,大概率该拆成两个。
单一职责——每个 Skill 只做一件事。不要把“修 Issue”和“写文档”合并。
跨袋里共享 Skills
通过符号链接(symlink)机制,一套 Skills 可以被多个 AI 编程工具共享。选定一个主库(比如 ~/.claude/skills/),把 ~/.agents/skills/ 用符号链接指向主库。Codex 的 ~/.codex/skills/ 保持为真实目录,因为里面有 .system/ 内置技能(如 imagegen、openai-docs),不建议改为符号链接。
实战提示词
创建你的第一个 Codex Skill,或者审计已有 Skill 质量。
→ 深入阅读:Codex Skills、子袋里与 Hooks 指南 · Skill 开发完全指南 · Skill 从入门到变&现
七、无界面模式(headless)— 自动化执行
codex exec 是 Codex 自动化场景的核心入口,适用于持续集成(CI/CD)、脚本集成和多袋里编排。它让 Codex 在没有交互界面的情况下执行任务并返回结果。
四种调用方式
最简调用——codex exec --full-auto "任务描述",终端直接输出结果。适合一次性任务。
换行分隔 JSON 事件流(NDJSON)——加 --json 标志,Codex 输出逐行 JSON 事件,适合脚本解析。每一行是一个独立的 JSON 对象,包含事件类型、内容和时间戳。
最终回复写文件——加 -o 标志,只把最终消息写入指定文件,过程输出不保留。适合只关心结果不关心过程的场景。
结构化输出——加 --output-schema 标志,Codex 按你定义的 JSON Schema 格式返回结构化数据。适合需要程序化消费结果的场景。
会话恢复(Resume)
Codex 支持会话恢复。工作流程:先通过 --json 输出的事件流提取 session_id(筛选 type 为 session.created 的事件),保存该 ID 后用 codex exec resume 加新任务描述继续对话。也可以用 codex exec resume --last 直接恢复最近一次会话。
这对长任务特别有用——如果任务执行到一半中断了,你不需要重新开始,直接恢复会话继续。
CI/CD 集成
在 GitHub Actions 中集成 Codex 的典型步骤:检出代码 → 安装 Codex CLI → 用 API Key 认证 → 用 codex exec 执行任务。
CI 环境的关键注意事项:
必须用 API Key 模式认证(通过 codex login --with-api-key 从管道注入),不要走 OAuth——CI 环境没有浏览器完成授权流程。
加 --full-auto 标志——CI 不会有人确认操作,必须全自动执行。
加 --json 标志——输出事件流到文件备查,方便事后排障。
加 --ephemeral 标志——一次性执行不持久化会话,避免 CI 环境积累废弃会话数据。
批量自动化
对多个文件重复执行同一类任务时,用 shell 循环逐个调用 codex exec --full-auto --ephemeral。注意两个细节:在脚本中用 防止 stdin 阻塞(codex exec 默认读 stdin,不重定向会卡住);加 --ephemeral 确保每次调用独立,不互相干扰。
实战提示词
测试 headless 执行,或者创建 CI 集成配置。
→ 深入阅读:Codex 任务管线指南 · Codex 团队与生产部署
八、上下文管理 — 贯穿一切的底层逻辑
前七个模块本质上都在做同一件事:管理上下文窗口的质量。GPT-5.5 在 Codex 中默认 128K token 上下文窗口,可通过 model_context_window 配置调至模型上限(1M),但上下文质量比数量更重要。
AGENTS.md 管的是会话启动时加载什么指令。MCP 的工具描述占用多少上下文空间。钩子在不占用上下文的前提下提供确定性控制。Skills 在主会话上下文中执行标准化工作流。headless 模式让每次执行都从干净的上下文开始。
理解了这个底层逻辑,剩下的就是几个日常操作习惯。
/clear 的节奏
/clear 清空当前上下文,重新开始。和 Claude Code 一样,在两个不相关的任务之间不清上下文,是产出质量下降最常见的原因。
前一个任务的文件内容、失败尝试、中间推理全部留在窗口里,挤占新任务的空间。更危险的是,Codex 可能被前一个任务的“残留记忆”误导。
建议的节奏:一个任务做完提交(commit)之后,立刻 /clear。想接着聊,用 resume 恢复会话。
/compact 精准瘦身
/compact 比 /clear 温和——不清空,只压缩。完成一组文件修改后压缩,清除已完成的计划和工具调用细节,保留关键上下文。
高效的长会话遵循「读 → 改 → 验 → 压缩」循环:让 Codex 先读项目结构 → 只读相关源文件 → 执行修改 → 运行测试验证 → /compact 压缩 → 继续下一组修改。
通俗讲:把上下文窗口想象成工作台面。及时清理已完成任务的中间产物(计划文本、失败尝试、旧文件内容),才能为下一个任务腾出空间。
连续纠正两次还不对:信号灯亮了
如果你对 Codex 的同一个错误纠正了两次它还是没改对——不要继续第三次。窗口里已经积累了两轮失败方案和你的纠正指令,Codex 反而更容易被这些“失败记忆”干扰。
正确做法:/clear,重新写一个更清晰的初始提示词,从干净的上下文开始。
临时会话(--ephemeral)
--ephemeral 标志让 Codex 执行完就丢弃会话数据,不持久化。适用于一次性脚本、CI 环境和批量验证——这些场景不需要恢复会话,留着反而浪费磁盘空间。
实战提示词
诊断上下文健康度,或者优化长会话节奏。
→ 深入阅读:Codex 上下文工程指南 · Claude Code 上下文窗口指南
九、Codex vs Claude Code — 选型与协作

两者是互补关系,不是替代关系。根据任务特性选择最合适的工具,或者在同一项目中同时使用两个。
选 Codex 的场景
| 场景 | 原因 |
|---|---|
| 需要操作系统级沙箱隔离 | macOS Seatbelt / Linux Landlock 内核级保护,Claude Code 没有原生沙箱 |
| CI/CD 自动化集成 | codex exec + NDJSON + JSON Schema 原生支持 |
| 成本敏感的长时间工作 | ChatGPT 订阅包月,比 API 按 token 计费更经济 |
| 需要自定义模型提供商(LLM Provider) | config.toml 的 model_providers 段可接入任意端点 |
| 需要多配置集快速切换 | Profile 系统一键切换场景 |
| 需要 Codex 作为 MCP 服务器 | codex mcp 暴露给其他袋里调用 |
选 Claude Code 的场景
| 场景 | 原因 |
|---|---|
| 复杂的跨文件架构改动 | Claude 在长上下文理解方面有优势 |
| 需要精细的文件操作工具 | Read/Edit/Write 专用工具比 shell 命令更精确 |
| 需要原生记忆(Memory)系统 | 自动记忆跨会话偏好 |
| 需要精细的钩子控制 | PreToolUse/PostToolUse 精细拦截 |
| 团队协作 | TeamCreate/SendMessage 原生支持 |
| 前端 UI 开发 | 对视觉组件的理解力更强 |
想深入了解 Claude Code 的配置,可以看 Claude Code 最佳实践。
核心架构差异
| 维度 | Codex | Claude Code |
|---|---|---|
| 实现语言 | Rust(高性能终端界面) | TypeScript/Node.js |
| 沙箱 | 内核级(Seatbelt/Landlock) | 无原生沙箱 |
| 配置格式 | TOML | JSON |
| 指令文件 | AGENTS.md(32KB 限制) | CLAUDE.md(无硬限制) |
| 文件操作 | 通过 shell 命令 | 专用 Read/Edit/Write 工具 |
| 搜索 | shell 命令(find/grep) | 内置 Glob/Grep |
| 开源 | 是 | 否 |
双工具协同模式
在同一项目中同时使用两个工具是高效的工作方式,三种协同模式:
指令文件兼容——通过 project_doc_fallback_filenames 让 Codex 识别 CLAUDE.md。一套项目规范,两个袋里都遵守。
MCP 互调——通过 codex mcp 将 Codex 暴露为 MCP 服务器,Claude Code 通过 MCP 调用 Codex。反过来也可以。两个袋里互相增强。
Skills 共享——~/.agents/skills/ 作为跨工具通用接收端,符号链接指向主库,一套 Skills 两个工具都能用。
实战提示词
做选型诊断,或者配置双工具兼容。
→ 深入阅读:Codex 完整学习指南 · Claude Code 最佳实践 · Claude Code 完整学习指南
常见问题
Codex 和 Cursor 有什么区别?
Codex 是终端 AI 袋里,通过命令行操作代码和文件系统,适合全栈开发和自动化。Cursor 是 VS Code 的 AI 增强版,在编辑器内提供补全和聊天,适合面向编辑器的交互式开发。两者面向不同的工作场景。
Codex 免费吗?
Codex CLI 本身开源免费。使用需要 ChatGPT Pro/Plus 订阅(走 OAuth 登录,包月使用)或 OpenAI API Key(按 token 计费)。对于日常开发,ChatGPT 订阅比 API 按量计费更经济。注意不同订阅档位有各自的用量配额。
AGENTS.md 和 CLAUDE.md 可以共存吗?
可以。通过 project_doc_fallback_filenames 配置,Codex 会在找不到 AGENTS.md 时读取 CLAUDE.md。两者也可以同时存在:AGENTS.md 写 Codex 专用规则,CLAUDE.md 写通用规则或 Claude Code 专用规则,一套项目规范兼容两个袋里。详见 AGENTS.md 新手指南。
沙箱模式下如何让 Codex 访问网络?
三种方案:切换到 danger-full-access 模式(最直接但最不安全);将网络操作封装为 MCP 工具(最推荐——MCP 进程天然在沙箱外运行);使用 --full-auto 启动(折中方案)。
多台机器如何共享 Codex 配置?
config.toml 不建议跨机整份复制(路径不同),推荐用补丁脚本只同步模型、Profile、功能开关字段。AGENTS.md 可通过 Syncthing 同步。auth.json(认证凭据)只走 scp 点对点传输,禁止通过 Git 或云盘同步——多台机器共享同一份 auth.json 时,token 刷新会导致其他机器的旧令牌失效。
启动时卡在 Working / MCP 阶段怎么办?
通常是某个 MCP 的 tools/list 调用超时。用 codex mcp list 定位问题服务器。常见原因是 npx 冷启动(改为全局固定安装)、npm 缓存目录权限问题(固定到 ~/.codex/npm-cache)、或 Linux 上 PATH 漏掉 Node 路径(在 MCP 的启动脚本中显式设置 PATH)。
延伸阅读
- Codex 完整学习指南——从零开始的完整知识地图
- Claude Code 最佳实践——六大模块逐个拆解,与本文互为参照
- CLAUDE.md 最佳实践——指令文件设计方法,与 AGENTS.md 互为参照
- MCP 最佳实践——从协议原理到生产部署的完整指南
- AI 知识库最佳实践——知识库从设计到落地的完整方案
- Codex 官方文档——CLI 参考、配置字段、API 最新变更
- Codex GitHub 仓库——源码、Issue、更新日志
配置字段和功能特性可能随版本更新变化。建议结合 OpenAI 官方更新日志验证最新状态。




