RAG知识库性能评估与成本监控技术方案
先梳理一下这套方案的核心逻辑:采用Ragas评估框架搭配Langfuse成本监控工具,构建一条“性能评估—成本管控—迭代优化”的全链路监控体系。目标很明确——性能达标、成本可控、体验最优。传统RAG系统常见的三大痛点——评估模糊、成本失控、优化盲目,这套方案正好能精准解决,让每一次迭代都有数据支撑。
一、方案概述
整体思路是:通过一套标准化的评估流程,精准定位知识库的短板;同时借助实时成本追踪,理清资源分配。最后根据这两方面的数据,完成“评估-管控-优化”的闭环。换句话说,就是给RAG知识库装上一套带仪表盘的驾驶舱,既能掌握运行速度(性能),也能了解资源消耗(成本)。
二、核心技术选型及优势
(一)Ragas:RAG性能评估核心框架
选型原因:选择Ragas的核心原因是它专为RAG系统设计,能够直接进行端到端评估,无需手动拆分检索与生成环节。它还支持自定义指标,方便适配知识库的业务场景。加上原生集成的实验追踪和结果聚合功能,评估链路的搭建成本显著降低。
核心优势:
- 数据集适配性强:可以导入真实业务查询数据集,也能使用LLM生成贴合场景的合成数据,确保评估结果反映实际运行情况。
- 指标聚焦核心需求:支持自定义离散型和连续型指标(如正确性、相关性),直接衡量回答质量,简洁高效。
- 实验流程自动化:一键运行评估任务,自动输出结构化结果,并支持多版本对比——版本迭代时,性能差异一目了然。
举个实际例子,跑完一次评估后,拿到的报告长这样:
{
"test_number": 2,
"question": "What are the three main components required in a RAG system?",
"answer": "根据提供的知识库上下文,",
"ground_truth": "RAG system requires three main components: a retrieval",
"project": "Lightrag_evaluation_sample",
"metrics": {
"faithfulness": 0.7777777777777778,
"answer_relevance": 0.0,
"context_recall": 0.0,
"context_precision": 0.0
},
"timestamp": "2025-12-23T14:19:24.840570",
"ragas_score": 0.1944
}
这就是基于示例测试用例,跑出来的知识库评估报告。每个指标的具体数值,能直接揭示当前版本的薄弱之处。
(二)Langfuse:LLM调用成本与性能监控工具
选型原因:LLM应用的成本和性能监控长期是难点。Langfuse提供了多维度、实时化的观测能力——它自动适配主流模型价格,集成成本低,还支持告警和预算控制,有效规避超支风险。
核心优势:
- 成本计算精准灵活:支持自动计算(覆盖OpenAI、Anthropic等100+模型),也支持用户自定义计算,兼顾标准场景与定制化计费。
- 监控维度全面:可按模型、项目、时间等多维度拆分成本与性能数据,高消耗环节一眼可辨。
- 实时告警与控制:设置成本阈值告警(如单次查询超过0.1美元)、项目级预算上限,真正做到“监控—告警—控制”一体化。
监控仪表盘的效果参考下面两张图:
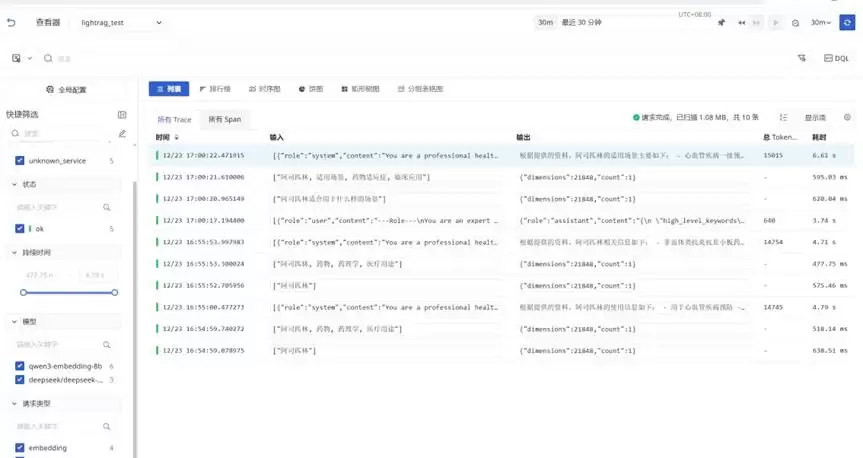
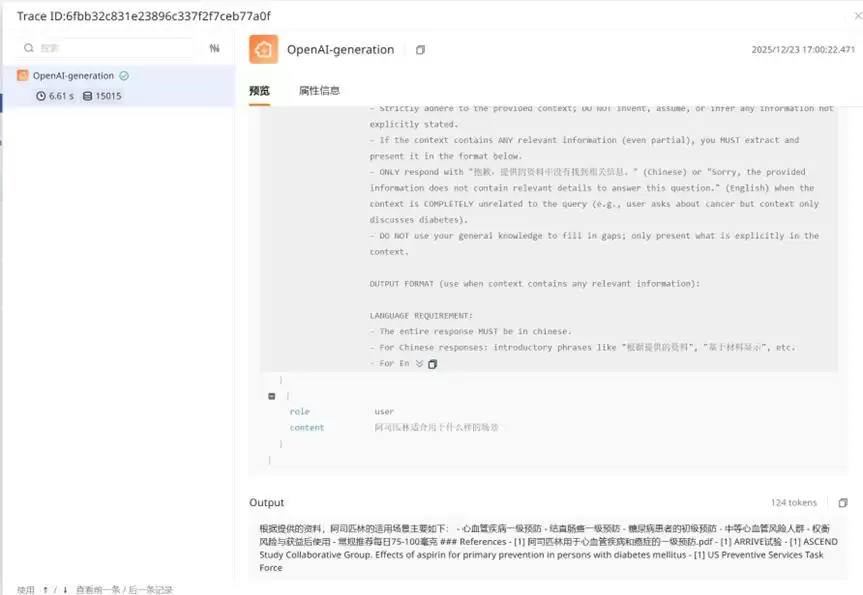
三、核心监控模块设计
(一)性能评估模块
评估数据集构建
- 数据来源:一是采集真实业务场景中的用户查询(同时附带标准答案),二是通过LLM生成贴合知识库领域的合成问答对,标准化为“问题-预期答案”结构。另外,用户在实际App中对AI回答的反馈(点赞/点踩)也很有价值,可标准化为“问题-理想/不理想答案”结构。
- 数据格式:导入Ragas Dataset进行管理,CSV等格式均可存储。
核心评估指标
- 正确性:判断模型响应是否包含预期答案的关键信息、是否事实准确(基于Ragas的DiscreteMetric自定义实现)。
- 检索相关性:评估检索环节返回的文档与问题的匹配程度,漏检、误检问题都能准确识别。
- 响应时效性:记录从查询发起至获取答案的总耗时,确保知识库响应速度达标。
评估流程
- 基线测试:初始化一个基础版RAG系统(例如基于BM25检索器),运行一次评估任务,获取基准性能数据(如正确率、平均响应时间)。这就是后续优化的起点。
- 迭代测试:每次对知识库进行优化(如切换检索策略、调整文档切分方式)后,重复评估流程,观察性能变化。
- 失败分析:对失败的案例查看轨迹数据,定位核心问题——是检索器未匹配到关键文档,还是生成Prompt设计有缺陷,一目了然。
(二)成本监控模块
监控指标
- 核心成本指标:单次查询平均成本、每日/每月总成本、各模型调用成本占比、Token输入/输出成本拆分。这些数据能直接反映资金流向。
- 辅助性能指标:Token使用效率(有效信息输出Token占比)、模型响应耗时。这是成本与性能的交叉指标,帮助判断“钱花得是否值得”。
监控流程
- 集成配置:通过Langfuse SDK接入RAG系统,开启自动成本计算与数据上报。简单配置即可运行。
- 数据可视化:通过Langfuse仪表盘,可查看成本趋势、模型消耗排行等数据,高效识别成本偏高的环节。
- 告警配置:设置成本阈值告警(如单次查询成本超过0.1美元、日成本环比增长超过50%),触发后自动通过邮件或Slack通知。即使是夜间,也能避免预算超支。
(三)优化闭环模块
问题定位:结合Ragas的评估结果与Langfuse的监控数据,精准锁定核心优化点——
- 性能问题:如果正确率偏低,优先考虑优化检索策略(如从BM25切换到向量检索,或采用Agentic RAG),或调整文档的chunking方式。若响应慢,可优化模型选型(下调模型参数、改用轻量化模型)。
- 成本问题:如果某个模型消耗异常高,可优化Prompt内容(减少冗余信息)、启用缓存策略,或对非核心场景降级使用更便宜的模型。
迭代优化
- 检索优化:采用Agentic RAG模式,让AI agent迭代优化检索关键词,提升检索覆盖率;或引入混合检索(BM25 + 向量检索),实现双管齐下。
- 成本优化:对非关键场景使用低成本模型(如用gpt-4o-mini替代gpt-4o);优化Prompt结构,减少Token消耗;启用Langfuse的缓存策略,重复查询复用结果,节省重复调用。
- 验证评估:每次优化后,重新运行性能评估和成本监控,对比优化前后的指标变化。若效果未达标,持续调整——不断循环,直至满意。
四、方案核心价值
- 数据驱动优化:通过标准化评估与多维度监控,告别“凭经验优化”,每一次调整都有数据支撑。
- 成本可控:实时监控LLM调用成本,提前规避超支风险,资源分配效率自然提升。
- 可追溯可复用:完整的评估与优化过程都有记录,支持多版本对比,沉淀后的优化方案可重复使用。
- 快速迭代:评估和监控流程简化后,优化周期大幅缩短,知识库的回答质量和用户体验持续提升。




