问题描述:Azure AI Search 英文检索中的词形差异难题
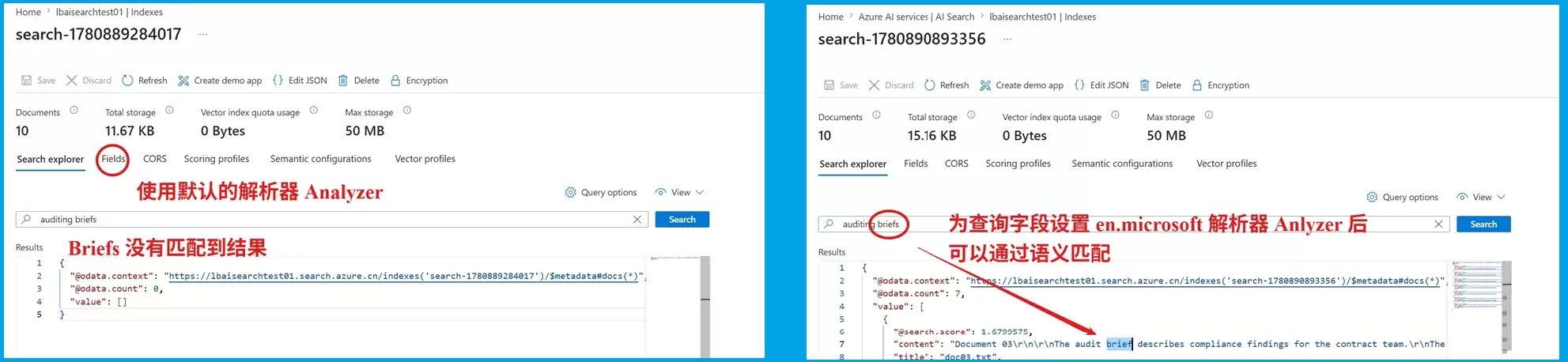
先说说今天碰到的常见场景:在 Azure AI Search 里进行英文全文检索时,常常因为一个很小的词形差异导致查询失败。例如文档中写的是 brief,而搜索 briefs 就是无法命中。
例如,搜索 briefs 无法命中只包含 brief 的文档。类似情况还有 audit 与 auditing,仅差一个复数或时态,检索结果却完全不同。
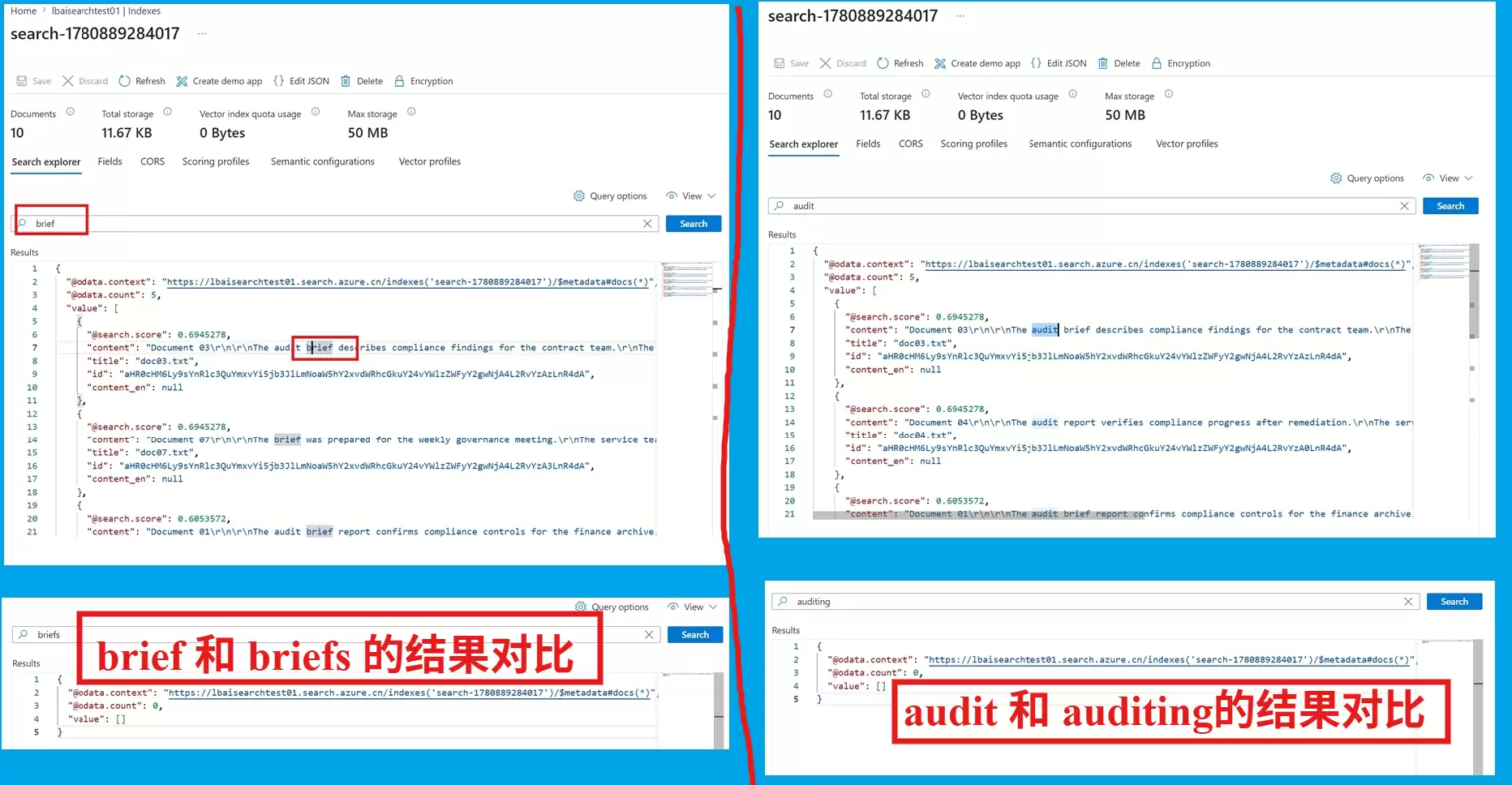
文档明明存在,关键词只差一个“s”或“ing”,为何检索结果天差地别?
问题的根源并非文档内容,而是 Azure AI Search 底层使用的匹配机制。通俗来说,就是它究竟基于字符串文本匹配,还是基于语义匹配?
问题解析:分析器(Analyzer)决定匹配结果
Azure AI Search 在执行全文检索时,并非直接比较原始字符串,而是比较经过分析器(analyzer)处理后生成的词条(token)。
brief 和 briefs 能否互相命中,取决于索引字段使用的是默认分析器 standard.lucene,还是语言分析器(如 en.microsoft)。
1. standard.lucene:不做词形还原
standard.lucene 是 Azure AI Search 的默认分析器,仅执行分词和小写转换,不进行英文词干提取或词形还原(lemmatization)。
因此,搜索 briefs 无法匹配 brief 的原因并非数据缺失或服务故障,而是两者经分析器生成的 token 完全不同。
2. en.microsoft:语言级词形还原(Lemmatization)
en.microsoft 采用词形还原(lemmatization)技术,并非简单截断词尾,而是基于语言学规则将单词变体还原为基本形式。
举例说明:
briefs → brief
auditing → audit
此类分析器尤其适合对英文检索质量要求较高的场景,例如需要处理单复数、时态变化及不规则动词变形。
代价是索引构建速度可能略有下降,但常规查询性能通常不受显著影响。
3. 如何选择
standard.luceneen.microsoft若英文内容涉及单复数、时态或不规则变化,建议优先验证 en.microsoft 分析器。若业务场景要求保留原始词形差异,则继续使用默认的 standard.lucene 更为妥当。
4. 修改分析器(Analyzer)
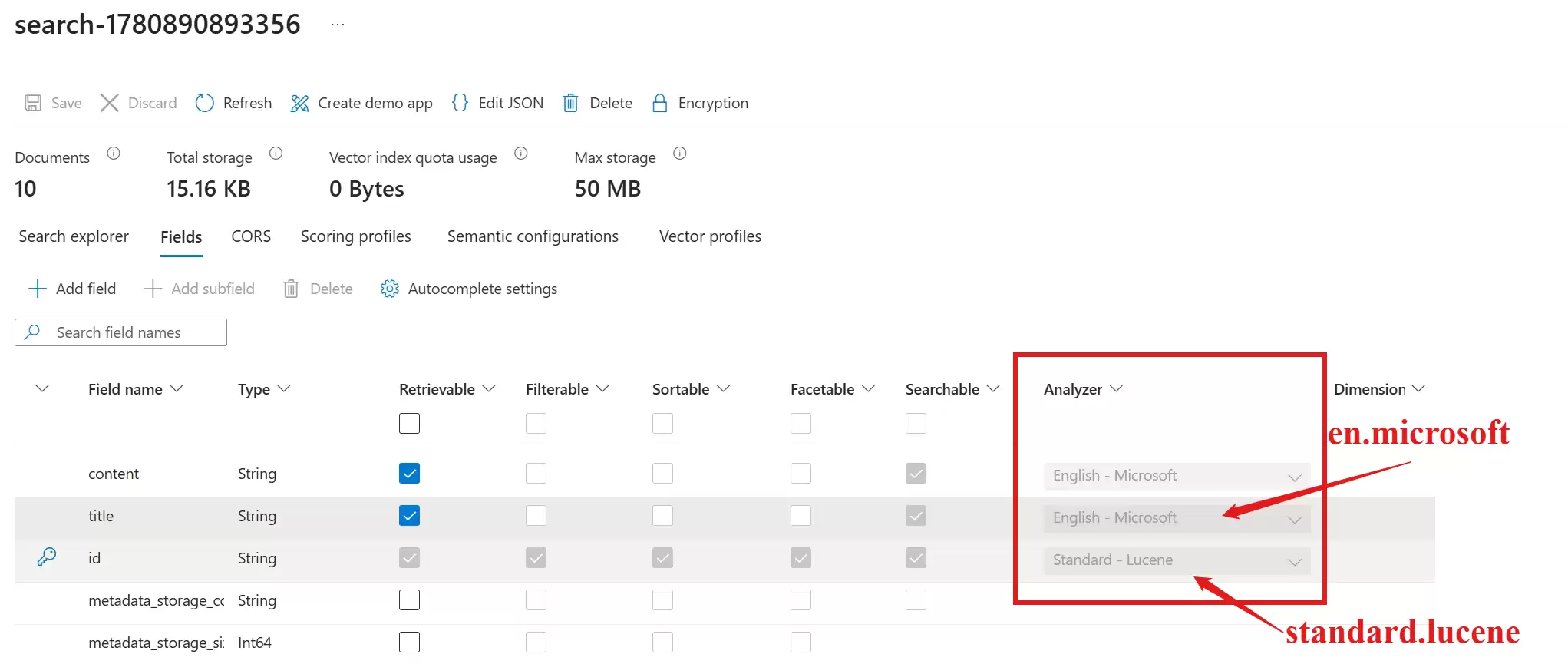
分析器(analyzer)是字段定义的一部分,已存在的字段无法直接修改。若要由 standard.lucene 切换至 en.microsoft,通常需要重建索引,或新增一个使用新分析器的并行字段,并通过 searchFields 参数切换验证。
如下图所示(无法修改 Analyzer):
以下是添加新索引字段并设置分析器的操作步骤:
1:添加新的查询字段
具体操作如下:
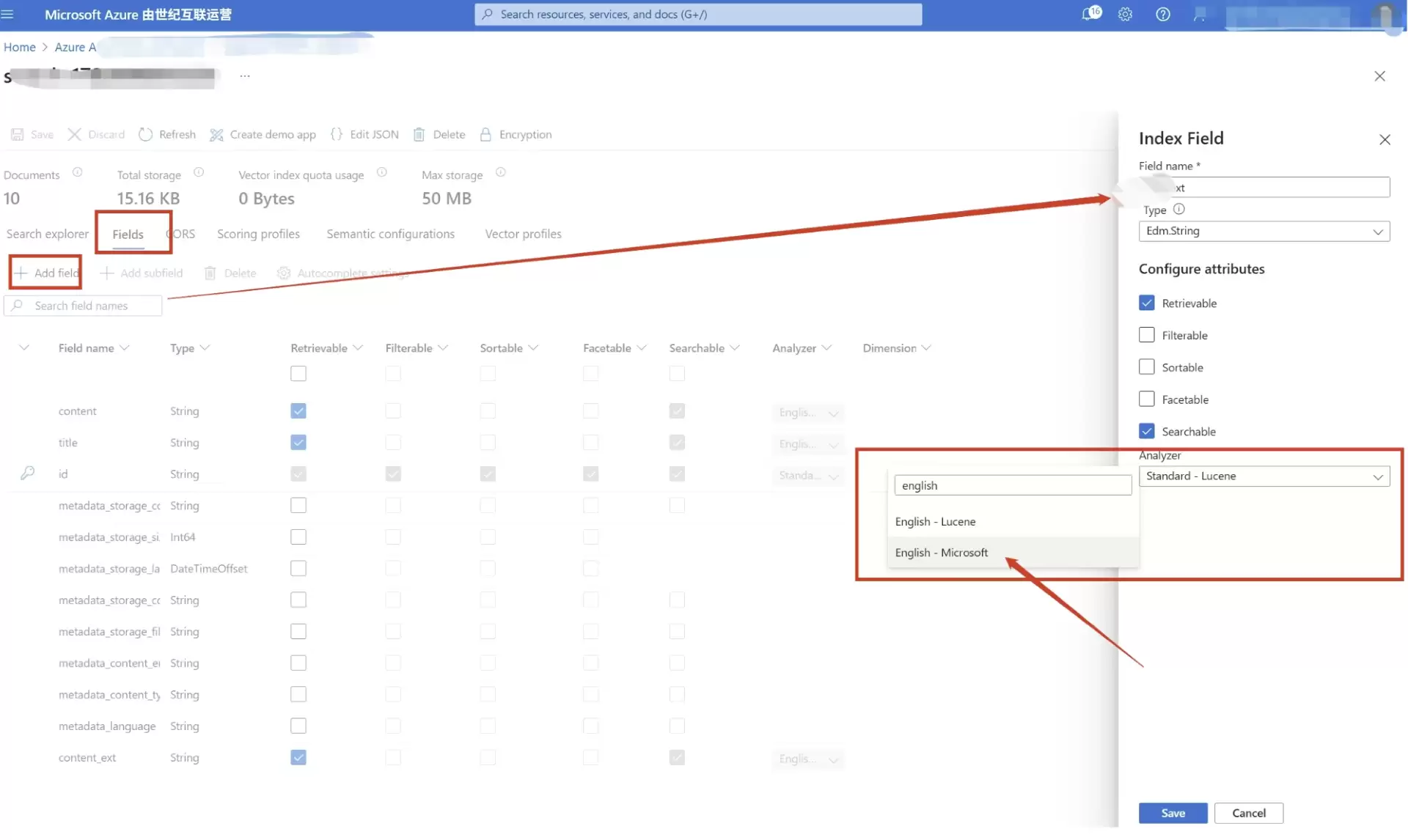
在索引的 Fields 选项卡中,点击添加字段。
输入新字段名,例如 content_ext。
勾选 Retrievable 和 Searchable。
选择 Analyzer 为 English - Microsoft(这一点很关键)。
保存修改。
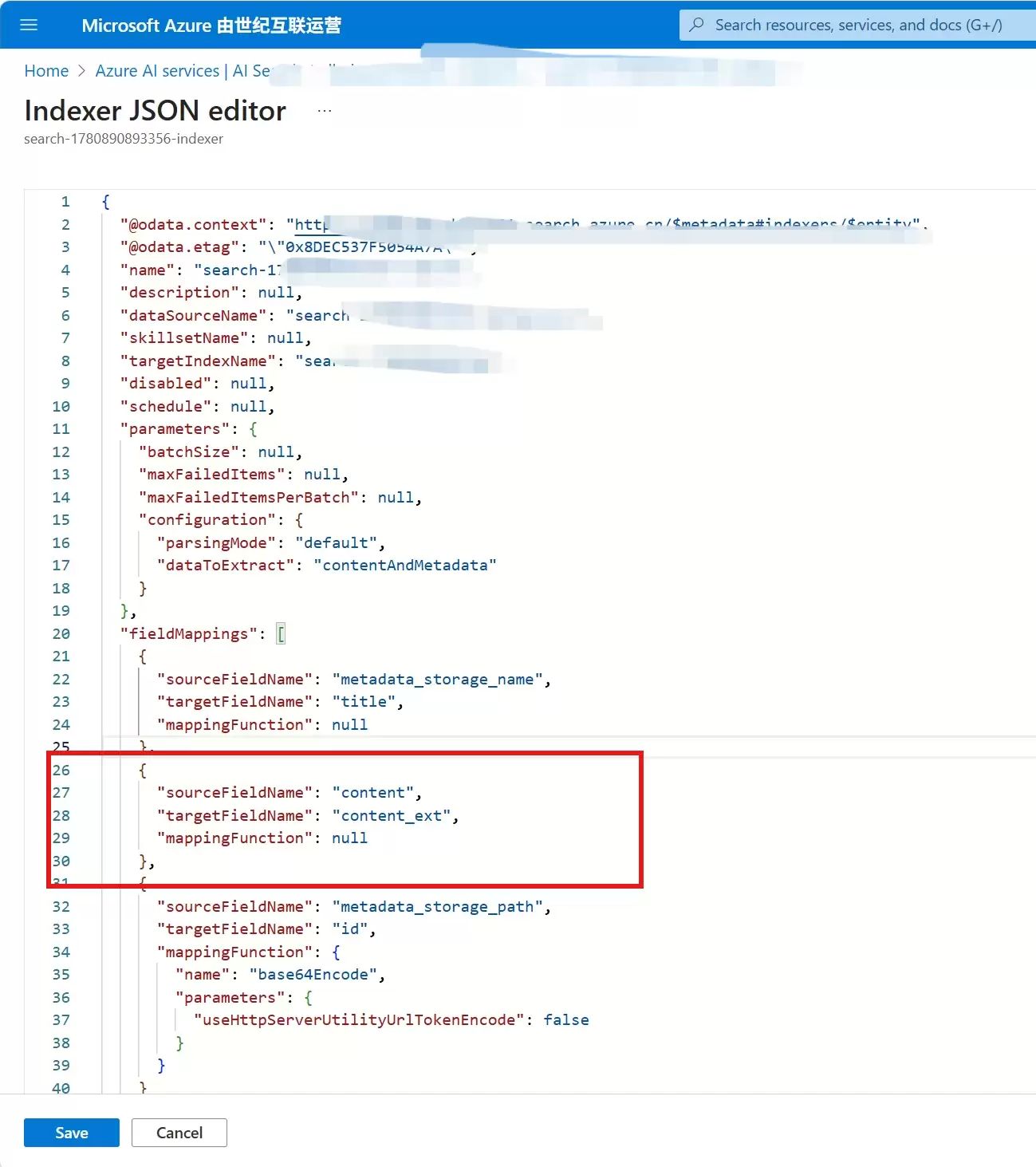
2:关联查询字段与文档内容
操作步骤如下:
进入对应的索引器,点击 Edit JSON。
在 fieldMappings 中,添加 sourceFieldName 为 content、targetFieldName 为 content_ext 的映射关系,然后保存。
添加内容:
参考截图如下:
3:修改文档属性并运行索引器为新字段填充数据
运行索引器,将文档的 content 内容填充到索引的 content_ext 字段中。
这一步需注意:需要让 blob 文档的最后修改时间发生变动后,再执行文档索引器,这样才会加载这些变动的文档内容。
执行完以上操作之后,可以对比验证使用默认 Analyzer 和 en.microsoft 的查询结果区别。
参考资料
用于 Azure AI 搜索的文本处理分析器:https://learn.microsoft.com/zh-cn/azure/search/search-analyzers
向 Azure AI 搜索索引中的字符串字段添加语言分析器: https://learn.microsoft.com/zh-cn/azure/search/index-add-language-analyzers
更新或重新生成索引 :https://learn.microsoft.com/zh-cn/azure/search/search-howto-reindex?tabs=sdk-python,portal
Indexes - Analyze - REST API (Azure Search Service) : https://learn.microsoft.com/zh-cn/rest/api/searchservice/indexes/analyze?view=rest-searchservice-2026-04-01&tabs=HTTP




