上一篇我们聊了Feed流的基本概念与分类,从这一篇开始,直接进入核心议题——架构设计。
谈到Feed流系统的关键决策,很多人首先想到的是选什么数据库、用什么缓存技术。但说实话,这些并不是最关键的——数据分发策略才是那个牵一发而动全身的核心命门。简单来说就是:用户A发布了一条消息,如何让他所有的粉丝都能看到?是主动推送过去,还是等粉丝主动来拉取,又或者两者结合?
这个决策几乎决定了整个系统的走向——存储结构怎么设计、分页如何实现、性能瓶颈在哪里、扩展性怎么样,全都绕不开它。所以这一篇,我们把这个话题彻底讲透。先不急着看具体实现,先把“该用什么策略”这个问题想清楚。
1. Feed流系统面临的核心挑战
在讨论具体方案之前,先明确Feed流系统到底要解决哪些问题。只有理解了这些挑战,才能更好地评估各种方案的优劣。
第一点,实时性要求不低。Feed的本质就是“实时消息流”,从消息产生到消费再到推送,整个链路要尽可能快。用户发布了一条动态,粉丝刷新页面后应该立刻能看到。这个“实时”不一定要求毫秒级,但秒级或秒级以内是基本要求。
第二点,数据量巨大。消息来源多样且数量庞大。一个大V发一条微博,可能要分发给上千万粉丝;每天产生的消息总量可能是亿级别的。这对存储系统提出了很高的要求。
第三点,读写严重失衡。前面提到过,Feed流是典型的读多写少场景,读写比通常在10:1以上。这意味着系统在架构上要明显偏向读优化。
第四点,数据一致性不能丢。消息发布出去后,必须保证所有关注者都能感知到。可以接受短暂延迟(最终一致性),但不能出现消息丢失。想象一下你发了一条朋友圈,结果只有一半朋友看到,另一半没看到,这对产品来说就是致命的。
这四个挑战是所有Feed流系统都要面对的,不同的分发策略就是在这些挑战之间做取舍。顺序不能乱,一个比一个难解决。
2. 三种数据分发策略详解
2.1 读扩散(拉模式)
读扩散的思路其实很简单。用户要刷Feed流的时候,系统就去拉取他关注的所有人的最新消息,然后合并排序返回。
具体流程是这样的:
用户请求Feed流 -> 获取用户的关注列表 -> 遍历关注列表,从每个人的发件箱中拉取最新消息 -> 合并所有消息,按时间排序 -> 返回给用户
这种方式的优势是什么?写入成本极低。用户发消息的时候,只需要写入自己的发件箱就行了,根本不用管粉丝的事。不管你有100个粉丝还是1亿个粉丝,写入的开销都是一样的。
但问题也很明显——读取成本太高了。假设一个用户关注了200个人,那他每次刷新Feed流都要去拉取200个发件箱的数据,然后合并排序。如果这200个人里有些是大V,发件箱数据量很大,那这个读取延迟……你懂的。
而且分页也是个棘手的问题。用户往下翻页的时候,需要记住每个关注人拉到了哪个位置(write_last_id),翻页逻辑会变得非常复杂。这个后面讲分页的时候再详细展开。
读扩散适合什么场景?粉丝数量特别多的大V用户。因为大V的粉丝太多了,写扩散的成本太高,不如让粉丝自己来拉取。
2.2 写扩散(推模式)
写扩散是读扩散的反面:用户发消息的时候,系统主动把消息推送到所有粉丝的收件箱中。粉丝查看Feed流的时候,直接从自己的收件箱读取就行了。
用户发布消息 -> 消息写入发件箱 -> 获取粉丝列表 -> 将消息ID写入每个粉丝的收件箱 -> 完成用户请求Feed流 -> 直接从自己的收件箱读取 -> 返回
写扩散最大的优势就是读取性能极好。粉丝打开Feed流的时候,数据已经准备好了,直接从收件箱里取就行,不需要任何实时计算。分页也简单,收件箱里的数据本身就是排好序的。
但缺点也摆在那儿——写入压力大。一个普通用户有几百个粉丝还好,但如果是一个有5000万粉丝的大V呢?他每发一条消息,就要往5000万个收件箱里写数据。这个写入量,想想就头大。
写扩散适合什么场景?普通用户。大部分用户的粉丝数量在几百到几千之间,写扩散的开销完全可以接受,而且读取体验最好。
2.3 读写结合(推拉结合模式)
既然读扩散和写扩散各有优劣,那能不能结合起来用?答案是肯定的——这也是业界最主流的方案。思路很清楚:普通用户用写扩散,大V用户用读写结合。
具体怎么操作?当大V发布消息的时候:
热粉丝(活跃用户):写扩散,消息主动推送到他们的收件箱;
冷粉丝(不活跃用户):不推送,等他们上线查看Feed流的时候再通过读扩散去拉取。
这样既保证了大V的热粉丝能实时看到新内容,又避免了向海量冷粉丝写扩散带来的性能压力。一举两得。
判断一个用户是“热粉丝”还是“冷粉丝”,常见的做法有几种:
根据登录频率,比如最近7天登录过就算热粉丝;
根据在线状态,当前在线的用户算热粉丝;
根据互动行为,最近有过点赞、评论等行为的算热粉丝。
// 消息发布时的分发逻辑
public void publishMessage(User publisher, Message message) {
// 1. 保存消息到发件箱
messageRepository.sa veToOutbox(publisher.getId(), message);
// 2. 判断是否为大V用户
if (isInfluencer(publisher)) {
// 大V:只向活跃粉丝写扩散
List activeFollowers = followerService.getActiveFollowers(publisher.getId());
for (User follower : activeFollowers) {
inboxService.addMessage(follower.getId(), message.getId(), publisher.getId());
}
} else {
// 普通用户:向所有粉丝写扩散
List allFollowers = followerService.getAllFollowers(publisher.getId());
for (User follower : allFollowers) {
inboxService.addMessage(follower.getId(), message.getId(), publisher.getId());
}
}
}
那“大V”的判断标准是什么?这个没有绝对的标准,需要根据业务场景来定。一般来说,粉丝数量超过某个阈值(比如10万)就可以算大V了。也可以结合认证状态、内容质量等维度综合判断。
public boolean isInfluencer(User user) {
// 基于粉丝数量判断,阈值可以根据业务调整
return user.getFollowersCount() > INFLUENCER_THRESHOLD;
}
3. 三种方案的对比分析
把三种方案放在一起对比一下,差别就更清楚了:
| 维度 | 读扩散 | 写扩散 | 读写结合 |
|---|---|---|---|
| 写入成本 | 低 | 高(大V场景极高) | 中等 |
| 读取成本 | 高 | 低 | 低(热粉丝)/ 高(冷粉丝) |
| 读取延迟 | 高(实时计算) | 低(数据已就绪) | 中等 |
| 分页复杂度 | 高 | 低 | 中等 |
| 适用场景 | 大V用户 | 普通用户 | 大V + 普通用户混合 |
由于Feed流是读多写少的场景,大部分情况下写扩散是更好的选择。毕竟读操作远多于写操作,优化读取性能带来的收益更大。只有当出现粉丝量级特别大的大V用户时,才需要引入读写结合来平衡写入压力。
4. 整体架构概览
确定了分发策略之后,我们可以看一下整体架构。下面这张图描述了一个典型的Feed流系统的核心组件和数据流向:
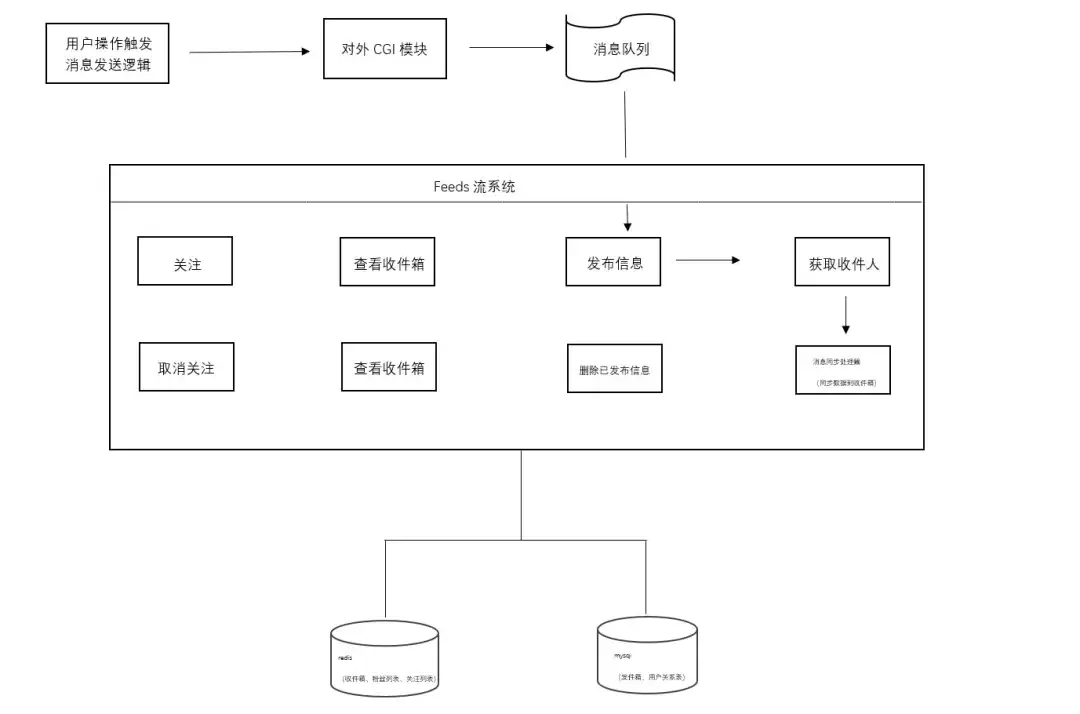
整个系统主要由以下几个核心组件构成:
消息发布服务。 处理用户发布的消息,将消息持久化到数据库,然后根据发布者的类型(普通用户/大V)选择合适的分发策略,将消息同步到粉丝的收件箱中。
消息存储服务。 管理消息内容和用户关系数据。消息内容存储在数据库中(发件箱),用户关系数据也需要持久化存储。
Feed流查询服务。 提供Feed流的查询接口。对于活跃用户,直接从收件箱读取;对于非活跃用户,还需要额外从关注的大V发件箱中拉取数据。
缓存层。 主要用Redis来实现。用户的收件箱用Redis的Sorted Set存储,提供高效的时间排序和分页能力。用户关系、活跃用户列表等热点数据也会缓存在Redis中。
消息队列。 用于解耦消息的发布和处理流程。用户发布的消息先进入消息队列,然后由后台消费者异步处理分发逻辑。这样做的好处是什么?一是提升系统的响应速度,用户不需要等待分发完成就能得到响应;二是削峰填谷,应对突发流量;三是失败可以重试,提高可靠性。
这些组件协同工作,构成了一个完整的Feed流系统。后面的文章会逐一深入每个组件的设计细节。
一个容易忽略的问题:消息修改和删除
在讨论分发策略的时候,大家往往只关注“发布”这个场景,但很容易忽略“修改”和“删除”。
写扩散模式下,消息发布出去后,每个粉丝的收件箱里都有这条消息的引用。如果发布者修改或删除了这条消息,怎么办?
最直观的做法是:修改或删除的时候,也做一次扩散,把变更同步到所有粉丝的收件箱。但这样做有两个问题:
和发布一样,大V场景下扩散成本太高;
用户在修改/删除的扩散完成之前,看到的还是旧数据,存在时效性问题。
更好的做法是:不扩散修改和删除,而是通过读取时的回查来实现。
具体来说,收件箱里存的不是完整的消息内容,而是消息ID。用户读取Feed流的时候,先拿到消息ID列表,然后回查数据库获取最新的消息内容。如果消息被修改了,回查时自然拿到的是最新版本;如果消息被删除了,回查时标记为已删除状态,过滤掉就行。
这种方式的好处是:修改和删除完全不需要扩散,零成本。代价是每次读取都要多一次回查操作,但这个开销在合理范围之内,完全值得。
这就是所谓的“软删除 + 懒删除”机制,下一篇讲数据模型的时候会详细展开。
6. 小结
这一篇重点聊了Feed流系统的三种数据分发策略。读扩散写入成本低但读取成本高,写扩散读取成本低但写入成本高,读写结合则是在两者之间取一个平衡。
对于大多数Feed流系统来说,推荐的方案是:以写扩散为主,对大V用户引入读写结合。这样既能保证大部分用户的读取体验,又能应对大V场景下的写入压力。
还有一个关键的设计原则:收件箱只存消息ID,不存完整内容。这样修改和删除就不需要扩散,通过读取时回查就能搞定。
下一篇我们会聊数据模型和存储设计——消息表怎么建、关注关系表怎么设计、收件箱用Redis怎么存。这些是整个系统的地基,地基打好了,后面的实现才会稳。




