当前AI助手功能日益强大,却常受限于各自的“数据孤岛”,难以连接实时变化的外部世界。这种割裂迫使开发者不得不为每个数据源定制接口,不仅拖慢创新步伐,也制约了系统扩展。是否存在一种方法,能让AI摆脱“信息孤岛”的困境?
模型上下文协议(MCP)正是解决这一问题的终极方案。它如同数据世界的通用语言,让AI助手能够无障碍连接各类数据源。通过统一的协议标准化交互方式,MCP不仅简化了开发工作,还大幅提升了AI的认知能力。
下面梳理你将从本文收获的核心内容:
- MCP核心原理:透彻理解协议的设计思想与核心优势
- 架构解析:深入了解MCP服务器与AI工具的无缝集成方式
- 代码实战:通过Python/TypeScript SDK灵活实现MCP
- 落地场景:探索MCP在实际应用中的创新用法
准备好了吗?接下来我们将深入揭示MCP服务器如何重新定义智能体AI的未来。
模型上下文协议(MCP)全面解析
MCP协议是解决AI“数据孤岛”问题的开放标准,它在AI模型与多种数据系统之间建立了安全、双向的通信通道。开发者无需再为每个数据源编写定制接口,MCP通过通用协议统一了AI访问外部数据的方式。
例如,当开发者需要查询GitHub仓库时,无需再分别为GitHub、Google Drive等服务编写不同的对接代码。使用MCP,只需配置通用接口,即可通过TypeScript SDK优雅地实现:
import { MCPServer } from 'mcp-sdk';
const githubServer = new MCPServer({
dataSource: 'GitHub',
authToken: '你的github令牌'
});
githubServer.fetchData().then(data => {
console.log('从GitHub获取的数据:', data);
})MCP本质上是连接AI与现实世界的桥梁,使AI系统具备以下能力:
- 以标准化的方式查询各种数据源
- 从GitHub、云盘、数据库等渠道精确获取信息
- 将外部上下文信息整合到推理与决策过程中
MCP的最终目标是利用统一协议取代零散的定制化集成方案,这种标准化为开发者和用户带来双重收益:
- 开发效率显著提升
- 不同AI系统之间无缝协同
- 用户体验始终保持流畅
- AI获取信息的广度和深度大幅扩展
MCP架构与工作原理详解
MCP采用精心设计的架构,确保AI系统与外部数据源之间安全高效地对接。接下来,我们将深入剖析其设计理念与运行机制。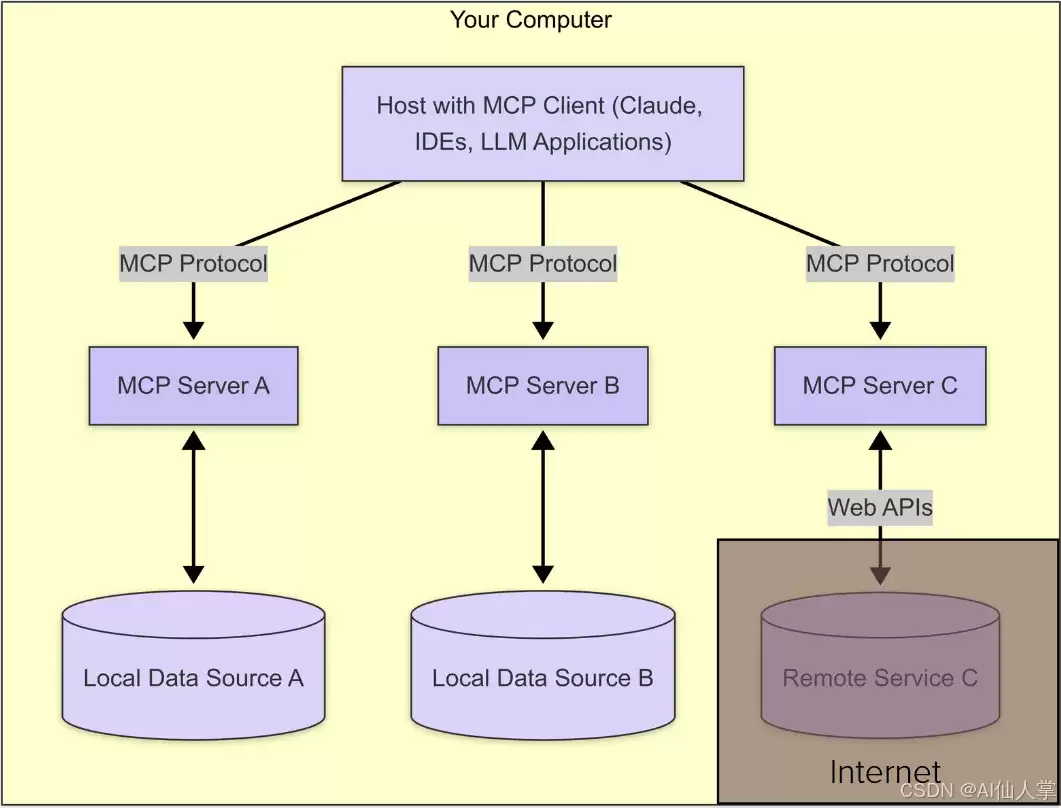
整体架构
MCP架构由两个核心组件组成,二者协同实现上下文感知的AI交互:
MCP服务器(数据提供方)
这些服务器按照MCP协议标准化地暴露数据接口,可以是GitHub仓库、Google Drive文档、AWS知识库等。它们接收来自MCP客户端的结构化查询,并返回协议定义的标准响应。
MCP客户端(AI工具)
作为需求方的AI系统,通过实现MCP客户端协议来查询服务器。包括语言模型、聊天机器人等需要外部上下文信息的AI应用。
安全双向通信
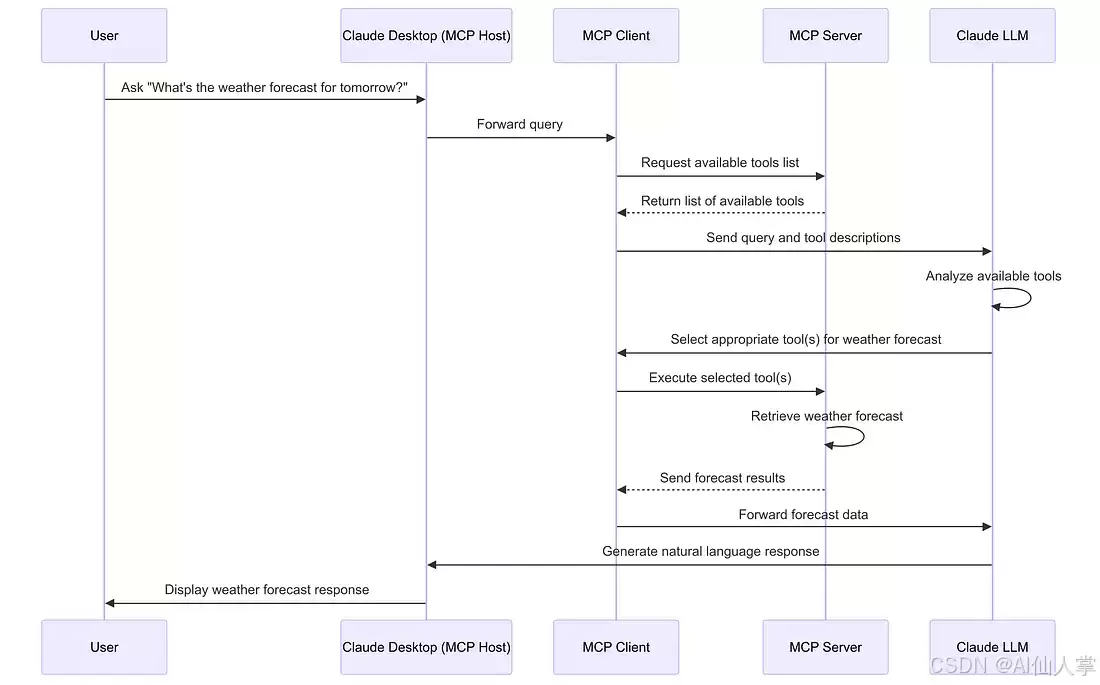
客户端与服务器通过加密通道进行以下交互:
- 查询阶段:客户端发送结构化查询请求
- 鉴权阶段:执行身份认证与权限校验
- 响应阶段:服务器处理查询并返回标准化数据
- 融合阶段:客户端将上下文信息融入决策流程
代码实战演示:
class MCPClient:
def __init__(self, auth_token):
self.auth_token = auth_token
self.registered_servers = {}
def register_server(self, server_id, server_url):
"""注册MCP服务器以备后续查询"""
self.registered_servers[server_id] = server_url
def query_server(self, server_id, query_params):
"""向已注册的MCP服务器发送查询"""
if server_id not in self.registered_servers:
raise ValueError(f"未注册的服务器: {server_id}")
server_url = self.registered_servers[server_id]
# 携带认证信息的请求头
headers = {
"Authorization": f"Bearer {self.auth_token}",
"Content-Type": "application/json"
}
# 向服务器发送POST请求
response = requests.post(f"{server_url}/query",
headers=headers,
json=query_params)
# 处理响应
if response.status_code == 200:
return response.json()
else:
raise Exception(f"服务器查询错误: {response.status_code}")
# 实战演示
client = MCPClient("你的认证令牌")
client.register_server("github", "https://mcp-github.example.com")
client.register_server("gdrive", "https://mcp-gdrive.example.com")
# 查询GitHub服务器
github_results = client.query_server("github"<...)



