在使用 Redis 的过程中,你是否遇到过请求响应突然变慢、网络出现卡顿,甚至数据丢失的情况?经过一番排查,发现罪魁祸首往往是 big keys 问题。这类状况在生产环境中并不罕见,今天就让我们深入剖析 big keys 的本质、成因与应对策略。
什么是 big keys
Redis 中单个 String 类型的 key 最大可存储 512MB 数据,而 list、set、hash、zset 等集合类型理论上可以容纳多达 40 亿个元素。但在实际高并发互联网业务场景中,根本不需要如此巨大的容量,反而对数据大小有更严格的限制。通常来说,符合以下任一条件即可认定为 big keys:
- String 类型的 key 对应的值超过 5 MB。
- list、set、hash、zset 等集合类型的元素个数超过 2000。
需要注意的是,上述标准并非绝对。在实践中,判断是否为 big keys 的核心依据应是“是否对业务产生了负面影响”。例如,某个 key 在执行操作时导致响应显著变慢,那么它就是 big keys,数字仅作为参考。
big keys 是怎么产生的
big keys 的产生通常源于程序设计阶段对数据规模的预估不足,或缓存结构设计不合理。常见的典型场景包括:
- 统计类应用场景:例如统计网站访问用户,初期数据量较小,但随着访问量持续增长,该 key 中的元素不断累积,逐渐演变为 big keys。
- 社交类应用场景:某个大 V 的粉丝列表,粉丝数量高达千万级别,若不进行拆分,一个 key 就可能导致性能崩溃。
- 缓存类应用场景:从数据库查询数据序列化后直接存入 Redis,为了方便常将所有数据塞进一个 key 中。业务量上升后,这个 key 迅速膨胀。
这些都是线上环境中真实踩过的坑。开发初期应根据预估数据量合理设计缓存数据结构,避免等出现问题再被动补救。
big keys 的危害
系统中存在 big keys,往往会直接引发响应变慢、请求超时,甚至导致整个系统不稳定。
1、响应变慢与请求超时阻塞
- 由于 Redis 采用单线程模型,同一时刻只能处理一个请求。操作 big keys 耗时较长,导致后续请求必须排队等待,从而造成响应变慢。
- 排队等待时间过长便会引发请求超时。此外,删除 big keys 同样耗费大量时间,也会阻塞后续请求。
2、网络拥塞
- 单个 big keys 可能产生巨大的网络流量。例如,一个 1MB 的 big keys 若被客户端每秒访问 1000 次,每秒流量即达到 1000MB,普通千兆网卡难以承受。
- 而且一台服务器上通常运行多个 Redis 实例,一个 big keys 的网络波动可能拖累其他实例的性能。
3、内存分布不均
- 在集群模式下,key 根据哈希槽分配到不同节点。如果多个 big keys 集中落在同一节点,就会导致内存使用倾斜,该节点内存紧张而其他节点资源闲置。
- 在水平扩容时,不得不以容量最大的节点为标准,从而浪费其他节点的内存资源。
如何发现 big keys
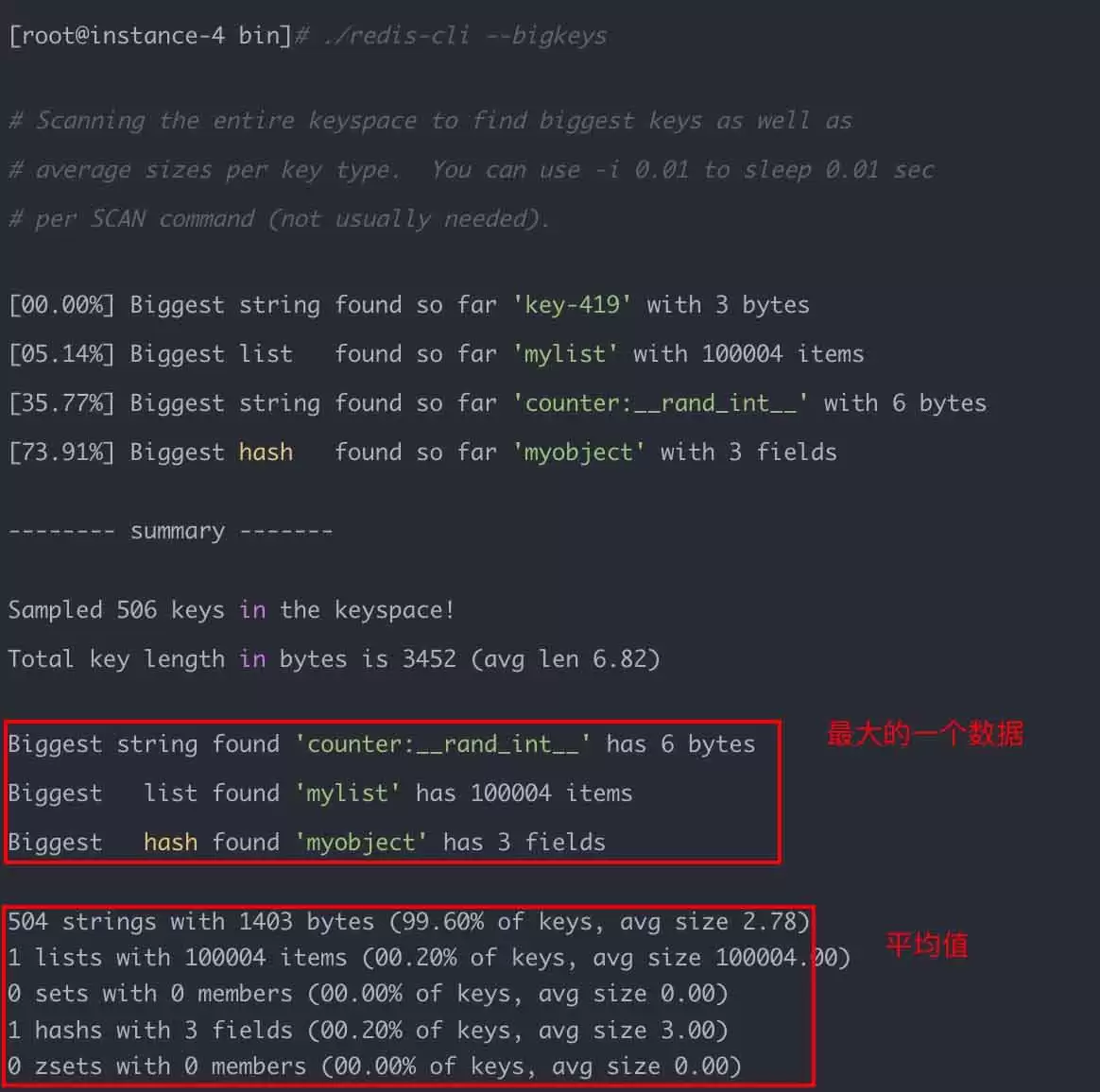
Redis 4.0 后提供了 --bigkeys 命令,用法很简单:
./redis-cli --bigkeys
它会统计每种数据类型里最大的 key,同时给出每种类型的键总数和平均大小。不过 Redis 是单线程的,为了减少对线上请求的影响,执行时需要注意以下几点:
- 建议在从节点(slave)上执行,因为
--bigkeys同样会遍历数据,可能阻塞主线程。 - 加上
--i参数降低扫描速度,比如--i 0.1表示每 100 毫秒扫描一次。 - 注意这个命令只能给出每种类型里最大的 key,无法提供全局的 big keys 列表。
big keys 怎么处理
异步删除 big keys
定位到 big keys 后,首要任务是及时删除。但直接使用 del 命令会阻塞线程,耗时较长。Redis 4.0 引入了 unlink 命令,支持异步非阻塞删除,推荐优先使用。
对于非字符串的集合类型(比如 list、set、hash、zset),可以利用 hscan、sscan、zscan 等命令进行渐进式删除,分多次取出并移除元素。此外,需要特别注意的是,如果 big keys 设置了过期时间,到期自动删除时同样会触发阻塞的 del 操作——例如一个包含 200 万元素的 zset 设置了 1 小时过期,到期瞬间可能导致 Redis 卡顿。
拆分 big keys
字符串类型:降低单个字符串的长度,将一个大字符串拆分成多个小字符串。
非字符串类型:减少元素个数。核心思路是将一个 key 拆分为多个 key。例如:
- 字符串类型的数据可根据属性拆分,比如商品信息按类别拆分成多个 key。
- 集合类型的数据可按时间拆分,比如用户登录集合按日期拆分成
key20220101、key20220102……
如果业务场景中确实无法避免 big keys(比如业务要求必须在一个 key 中存储大量数据),则查询和删除数据时应尽量采用分段操作,避免一次性全量获取或全量删除。
总结
- big keys 会导致请求变慢、网络阻塞、数据丢失等连锁问题。
- 字符串超过 5 MB、集合元素超过 2000 一般就属于 big keys 了,但具体还得结合业务场景判断。
- 产生原因主要是设计不合理或数据规模预判不足。
- 紧急处理:先用
unlink异步删除 big keys。长期优化:将单个 key 拆分成多个小 key。 - 如果无法避免 big keys,就采用分段查询和分段删除的方式操作。
在面试或系统设计时,可以从以下几个角度展开讨论:big keys 可能引起的性能影响、线上如何紧急处理、有哪些有效的优化方案以及各自的适用场景。掌握这些要点,就足以应对大部分相关问题了。




