与大语言模型(LLM)协作的关键在于如何有效地输入指令,也就是我们常说的“Prompt”。然而,随着应用场景日益复杂多样,如何高效地组织、管理和复用这些提示词,正成为一个亟待解决的挑战。为此,模型上下文协议(Model Context Protocol,MCP)应运而生,提供了一套标准化的解决框架,而其核心组件之一便是Prompts。
MCP Prompts 并非单纯的文本片段,而是一种由服务端预先定义、可供客户端灵活调用和配置的结构化提示词模板。这套机制使得服务端能够向客户端清晰地公开一系列预设的、可定制的交互范式,从而让与大型语言模型的沟通变得更加规范、可预测,大大提升了开发与应用效率。
MCP Prompts 的设计精髓
“用户主导”(user-controlled)是MCP Prompts 的核心设计哲学。这意味着这些高级提示词模板并非隐藏于后台,而是清晰地呈现给最终用户,由用户自主选择和触发。
这种透明化的设计,让用户能够清楚地了解到当前应用支持哪些与AI模型交互的特定功能。在实际用户界面中,最常见的实现方式是通过斜杠命令(slash commands)。例如,用户在聊天框中输入 /,系统便会下拉展示所有可用的 Prompts 列表。当用户选择并输入 /code_review,即表示他调用了一个名为“code_review”的代码审查提示模板。这种交互方式直观便捷,无需用户记忆复杂的指令格式,自然就能发现并使用各种预设功能。当然,MCP协议并不局限于斜杠命令,开发者完全可以根据产品设计,采用按钮、菜单或其他任何合适的UI组件来展示这些 Prompts。
一个标准的Prompt模板通常包含名称(name)、标题(title)、描述(description)以及一组可定义的参数(arguments)。以 code_review 为例,它可能需要一个名为 code 的必需参数,用于接收用户提交的待审查代码。这种结构化的定义确保了每一次交互意图明确,输入输出皆有据可循。
如何与 MCP Prompts 进行交互
客户端与服务端之间围绕Prompts的交互,遵循一套清晰的JSON-RPC协议消息流程。整个过程主要分为两个关键步骤:首先是发现可用的Prompts,其次是获取并使用指定的Prompt。
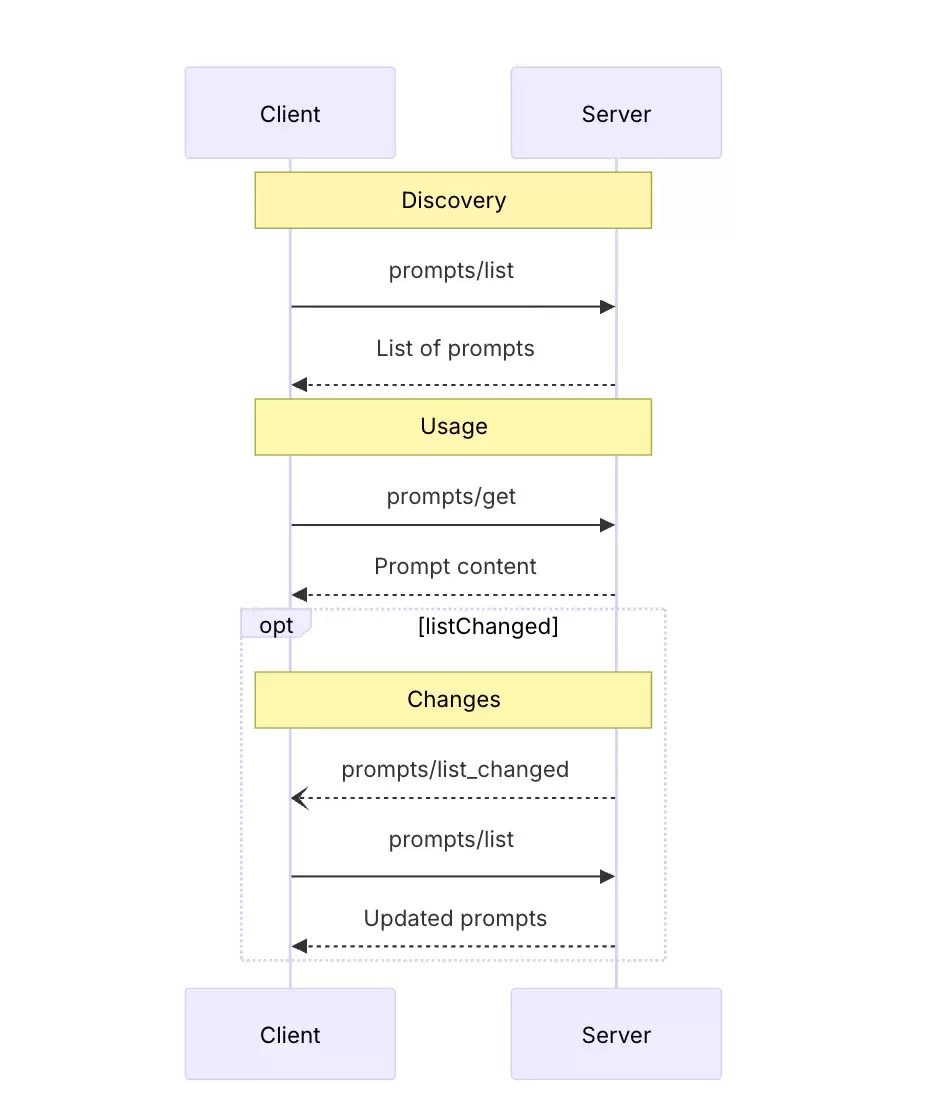
第一步:发现可用的 Prompts
交互的第一步,是客户端需要了解服务端提供了哪些可用的Prompts。这通过发送一个 prompts/list 请求来实现——这是一个标准的JSON-RPC请求,旨在向服务端查询当前可用的所有提示词模板列表。
一个基础形态的 prompts/list 请求示例如下:
{"jsonrpc": "2.0","id": 1,"method": "prompts/list","params": {}}服务端在接收到请求后,会返回一个包含 prompts 数组的响应,数组中每个对象都详细描述了一个可用的Prompt。
{"jsonrpc": "2.0","id": 1,"result": {"prompts": [{"name": "code_review","title": "Request Code Review","description": "Asks the LLM to analyze code quality and suggest improvements","arguments": [{"name": "code","description": "The code to review","required": true}]}],"nextCursor": null}}从响应中可以看出,服务端提供了一个名为 code_review 的Prompt,它具备清晰的标题和功能描述,并且要求一个必需的 code 参数。客户端界面可以根据这些元数据,为用户展示一个功能明确的选择项。如果Prompts数量庞大,服务端还可以通过 nextCursor 字段支持分页加载机制。
第二步:获取并使用 Prompt
当用户从列表中选择 code_review 并输入了待审查的代码后,客户端需要根据用户的输入,去获取这个Prompt最终生成的、可直接投喂给LLM的内容。这一步通过发送 prompts/get 请求来完成。
与列表查询不同,prompts/get 请求必须指定目标Prompt的 name,并提供用户已填充的 arguments 参数值。
{"jsonrpc": "2.0","id": 2,"method": "prompts/get","params": {"name": "code_review","arguments": {"code": "def hello():\nprint('world')"}}}服务端收到请求后,会依据 code_review 的模板定义和用户传入的 code 参数值,动态组装出最终要发送给语言模型的标准消息格式,并将其返回给客户端。
{"jsonrpc": "2.0","id": 2,"result": {"description": "Code review prompt","messages": [{"role": "user","content": {"type": "text","text": "Please review this Python code:\ndef hello():\nprint('world')"}}]}}客户端最终获得的 messages 数组,就是符合通用大模型API调用标准的消息体。这个过程清晰地将Prompt的模板定义、参数填充和最终内容生成三个阶段解耦,使得整个交互既灵活又具备高度的规范性。
Prompts 支持的多模态内容格式
MCP Prompts 的强大之处不仅在于结构化定义,更在于其支持丰富多样的内容类型——这使得与AI模型的交互不再局限于纯文本,迈向了真正的多模态应用。一个Prompt消息体(PromptMessage)可以包含文本、图像、音频,甚至直接引用服务端托管的资源文件。
下表清晰对比了不同内容类型的特点及典型应用场景:
| 内容类型 (Content Type) | 描述 | JSON 示例关键字段 |
|---|---|---|
text | 最基础的纯文本交互类型,适用于绝大多数自然语言指令与信息传递场景。 | "type": "text", "text": "..." |
image | 图像内容支持,可将图片作为上下文输入模型,适用于视觉问答、图像内容描述或分析等任务。 | "type": "image", "data": "base64...", "mimeType": "image/png" |
audio | 音频内容支持,允许将音频文件发送给模型,用于语音识别、音频内容摘要或情感分析等场景。 | "type": "audio", "data": "base64...", "mimeType": "audio/wa v" |
resource | 嵌入服务端资源,Prompt可直接引用服务端上的文件(如API文档、知识库文章),便于动态内容注入。 | "type": "resource", "resource": { "uri": "..." } |
image 和 audio 类型的数据需要以Base64格式编码,并携带正确的MIME类型,这为构建能“看懂”图片、“听懂”声音的智能应用铺平了道路。
resource 类型是一个非常强大的功能,它允许Prompt无缝集成服务端管理的静态或动态内容。例如,一个旨在“基于最新产品手册回答问题”的Prompt,可以通过引用一个资源URI,自动将最新的手册内容注入对话上下文,而无需客户端用户手动查找和上传文件。
动态更新与服务端能力声明
在实际持续运行的应用中,服务端提供的Prompts列表可能会动态变化。MCP协议为此设计了优雅的动态更新通知机制。
在客户端与服务端建立连接的初始化握手阶段,服务端必须声明其支持的能力集(capabilities)。如果服务端提供Prompts功能,并且支持在列表变更时主动通知客户端,就需要在其能力声明中包含 prompts 相关标识。
{"capabilities": {"prompts": {"listChanged": true}}}其中,"listChanged": true 是一个至关重要的信号。它告知客户端:“当我的可用Prompts列表发生任何增删改时,我会主动通知你更新。”
该通知通过一条名为 notifications/prompts/list_changed 的协议消息发送给客户端。客户端在收到此通知后,便知晓本地缓存的Prompts列表可能已失效,应立即重新发起 prompts/list 请求以获取最新列表。
这一简洁高效的机制,确保了客户端能实时响应服务端的功能更新,避免了低效的定时轮询,使整个系统协作更具实时性和响应性。
在具体开发实践中,为确保安全,服务端必须对用户传入的参数进行严格的验证与清理,防止潜在的注入攻击。同时,客户端也需要稳健地处理分页逻辑和各类错误场景——例如,当请求的Prompt不存在或参数缺失时,服务端会返回标准的JSON-RPC错误响应,客户端应能正确解析并向用户提供友好的提示。遵循MCP这套成熟的Prompts规范,开发者能够构建出功能强大、用户体验一致且易于长期维护的AI应用生态。




