OpenAI推出PointE三维模型技术全解析
时间:2026-06-14 14:26
在过去的一年里,OpenAI 的节奏快得让人喘不过气来。先是 Dall-E 2 和 ChatGPT 接连引爆网络,一个从文字生成图像,一个输出海量文本,把整个互联网的注意力都牢牢抓在手里。而就在圣诞节前,这家公司又悄悄抛出了第三个概念——Point-E,延续着同样的路子:靠你的提示词来创造内容。 P
在过去的一年里,OpenAI 的节奏快得让人喘不过气来。先是 Dall-E 2 和 ChatGPT 接连引爆网络,一个从文字生成图像,一个输出海量文本,把整个互联网的注意力都牢牢抓在手里。而就在圣诞节前,这家公司又悄悄抛出了第三个概念——Point-E,延续着同样的路子:靠你的提示词来创造内容。
Point-E 是什么?它又是怎么工作的?

从某种意义上说,Point-E 就是 Dall-E 2 的直系后裔,连命名逻辑都一脉相承。Dall-E 从零开始生成图像,而 Point-E 则更进一步——把图像转化成 3D 模型。OpenAI 团队在发布的研究论文里解释得很清楚:这套系统分两步走。第一步,用文本到图像的人工智能把你的文字提示变成一张图;第二步,用另一个函数把这张图转成 3D 模型。
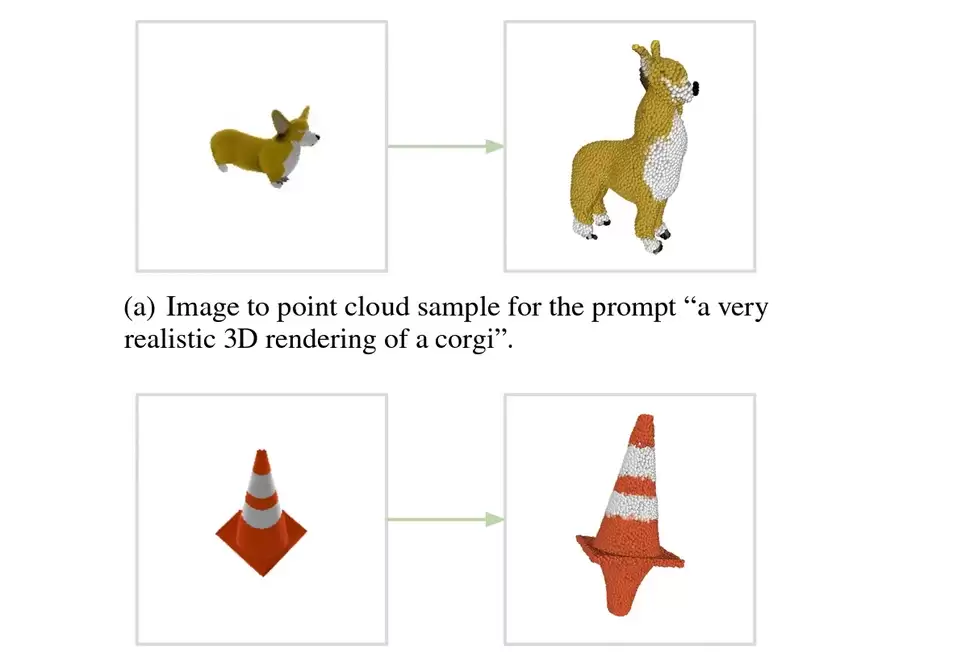
跟 Dall-E 2 追求极致画质不同,Point-E 只生成一个质量相对较低的图像——只要足够用来构建 3D 模型就行。而且,它并不像传统 3D 建模那样生成完整的流体结构,而是生成一个“点云”(Point Cloud),这也是名字 Point-E 的来源。简单说,就是在三维空间里撒下一堆点,这些点代表了一个立体形状。
当然,光靠一堆点看着可不太像回事,所以它还有第二步。团队额外训练了一个人工智能模型,把这些点转化成网格——也就是更接近物体形状、模具和边缘的编码结构。不过,当变量太多的时候,出点岔子也在所难免。OpenAI 在研究论文里也提到,生成的对象可能缺了点,或者出现方块状的畸形。
训练模型
要让模型正常工作,训练自然是重头戏。前半段——文本到图像的部分——跟之前的 Dall-E 2 一样,靠文字提示来训练。简单说,就是给图像配上替代文本,让模型学会理解图片里有什么。后半段——图像到 3D 模型——也需要类似的训练:给模型喂一大批图像,每个图像都跟对应的 3D 模型配对,这样 Point-E 就能弄明白二者之间的对应关系。
这个过程在庞大的数据集上重复了数百万次。第一次测试的时候,Point-E 倒是能根据点云生成请求物体的粗略颜色估计,但距离精准呈现还差得远。这项技术目前还处在早期阶段。要想让 Point-E 像 Dall-E 2 或 ChatGPT 那样稳定输出准确的 3D 渲染图,恐怕还得等上一阵子;至于公众能直接上手玩,时间可能更长。
怎么用 Point-E
截至目前,OpenAI 还没有正式发布 Point-E 的官方版本。不过,技术功底比较扎实的朋友可以通过 GitHub 获取代码。或者,你也可以在 Hugging Face 上试试——这是一个机器学习社区,之前也托管过不少大型人工智能项目。
说白了,现在这技术还比较初期,生成的结果不会太精确。在 Hugging Face 上试用时,可能会遇到长时间等待或者加载迟缓的情况。至于 OpenAI 后续会不会向公众开放这项服务,或者只搞邀请制,目前还没个准信儿。
Point-E 能做什么?

每当一个新的人工智能程序冒出来,大家的第一反应往往是:它到底要干什么?ChatGPT 和 Dall-E 2 让人担心它们会取代艺术家和创作者,这种担忧很可能也会落到 Point-E 头上。3D 设计本身就是一个庞大的产业,虽然目前的 Point-E 还远不能和专业的 3D 艺术家相提并论,但谁也说不好未来会不会直接跟这个领域抢饭碗。
不过,有报道称 OpenAI 每个月要花几百万美元来维持这些项目的运转。像 3D 渲染这么复杂的任务,软件的使用和运行成本可能会非常高昂。说到底,技术越先进,烧钱也越猛。




