AI Coding(AI编程)如今备受关注,但许多人对其存在误解。它远不止“让AI帮忙写几行代码”这么简单,本质上,这是一种以大型语言模型为核心驱动力的全新软件生产模式。这意味着,开发者的核心技能库需要更新:不仅要精通编程语言,更要掌握模型边界感知、上下文工程、认知负载管理等一套新兴的“软技能”。
随着Claude、GPT-4、Kimi等模型能力的持续跃迁,我们正经历一个显著的范式转移:从“AI辅助编码”(Copilot模式)转向“AI主导架构设计,开发人员主导关键决策”的智能体编程(Agentic Coding)。这一转变至关重要,它迫使我们必须建立全新的工作流、质量控制体系和知识管理方法。
第一部分:核心概念与认知框架
这部分帮你理清基本思路,如果你已经了解,可以直接跳到第二部分查看具体工作流。
1.1 模型边界感知
玩转AI Coding的第一原则,就是要清醒地认识模型的“天花板”。就像做饭,水加多了饭夹生,加少了饭太硬。模型也有明确的边界:
- 上下文窗口限制:虽然主流模型都宣称支持128K甚至200K tokens,但实际有效利用的长度往往只有8K到32K。简单来说,对话越长,模型对前面内容的记忆力(召回率)就越差,回答可能会开始偏离主题。
- 知识截止时间:模型训练数据有截止日期,对于最新的框架版本、API变更,它可能存在信息盲区。
- 推理深度:涉及复杂的算法推导或多步骤逻辑链时,模型容易在中间环节“卡住”或出错。
- 幻觉概率:在不熟悉的领域(比如你们公司内部特定的业务框架),它很可能生成看起来头头是道、但实际无法运行的代码。
因此,核心策略是任务拆解。不要一上来就把一个庞然大物丢给AI。
❌ 错误示范:“给我写一个完整的电商系统。” ✅ 正确姿势:[用户认证模块] → [商品数据模型设计] → [购物车业务逻辑] → [支付接口对接]
每个拆解后的子任务最好满足几个条件:职责单一(一次对话只解决一个问题)、输入完备(提供充分的接口定义和数据样例)、输出可验证(能通过测试用例或类型检查来验收)。
1.2 上下文工程
如果说提示词(Prompt)是给AI下达指令,那么上下文(Context)就是为它提供作战地图。这目前是最容易被低估的一项专业技能。
可以把上下文想象成一个金字塔:
- 项目级上下文:整个项目的架构图、采用的技术栈、团队编码规范、目录结构。
- 任务级上下文:与当前任务相关的代码文件、依赖的接口文档、业务逻辑的背景说明。
- 会话级上下文:当前对话的历史记录、已经做出的技术决策、还有哪些问题待解决。
如何高效管理上下文?有几种不错的方法:采用RAG(检索增强生成)技术,用向量数据库存储项目文档,需要时动态检索相关片段注入;引用文件时使用规范的标签(如
1.3 提示词工程:从“技巧”到“协议”
早期的提示词像是小技巧,现在则需要升级为结构化的“沟通协议”。一个好的结构化提示模板能极大提升效率。
[角色设定]
你是一位资深后端工程师,专精于高并发分布式系统。
[核心任务]
重构以下Python函数,使其支持异步并发处理。
[上下文信息]
当前函数使用同步阻塞I/O,目标是支撑10,000 QPS。允许使用的依赖库:asyncio, aiohttp。
[输入代码]
[这里粘贴需要重构的代码块]
[约束条件]
1. 必须保持现有的对外API接口不变。
2. 需要添加完整的类型注解。
3. 错误处理逻辑必须兼容现有的日志格式。
[输出要求]
1. 重构后的完整代码。
2. 关键变更点的简要说明。
3. 针对性能测试的初步建议。
其中的关键点很明确:通过角色设定锁定回答风格和专业领域;提前用约束条件框定技术边界,减少AI的无效尝试;对输出格式提出结构化要求,方便后续的自动化处理或人工审查。
第二部分:AI Coding 工作流与方法论
掌握了核心理念,我们来看看具体如何实践。
2.1 需求澄清与信息核对
AI Coding有一条铁律:输入的模糊性会导致输出错误率呈指数级上升。在敲下回车键之前,务必做好信息核对。可以准备一份简单的清单:
- 业务术语是否明确定义?(例如你说的“用户”是否包含未登录的访客?)
- 技术约束是否全部明确?(浏览器兼容版本、Python解释器版本、第三方依赖限制)
- 边界条件是否都已考虑?(空值如何处理、最大并发数多少、数据取值范围)
- 验收标准能否量化?(性能要达到多少QPS、测试覆盖率要求多少)
一个行之有效的方法是“反向复述”:先不要急着让它写代码,而是要求AI用自己的理解把你的需求重述一遍。双方确认理解一致后,再进入开发阶段。
2.2 调试与错误处理协议
AI生成的代码出错了怎么办?遵循一个结构化的报错流程能帮你节省大量时间。可以给AI一个清晰的报告模板:
[问题描述]
一句话概括现象,例如:服务启动时抛出NullPointerException。
[环境信息]
语言/框架版本:
操作系统:
相关依赖库版本:
[错误日志]
这里必须划个重点:及时止损!如果同一个问题经过3轮以上的交互迭代(AI修复-你测试-又报错)还没解决,立刻采取以下措施:开一个新的对话窗口,重置可能已被污染的上下文;把问题进一步拆解成更小、更容易验证的单元;切换策略,从“让AI自动修复”改为“让AI提供几种可能的解决方案,由你人工判断并实施”。
2.3 版本控制与代码审查
管理AI生成的代码,在版本控制上具有特殊性:
- 生成元数据标记:在Git提交信息中标注清楚生成这段代码所用的AI模型、提示词的版本以及温度参数等。这相当于留下了“实验记录”。
- 隔离实验分支:所有由AI主导的重构或重大修改,都必须在独立的功能分支上进行,最后通过Pull Request流程经由人工审查后才能合并到主分支。
- 快照对比:利用像aider、cline这类专门工具,可以清晰对比出AI修改前后的具体差异,审查起来一目了然。
代码审查时,可以带着一份清单重点检查:是否引入了未声明的第三方依赖?错误处理是否覆盖了所有重要场景?代码里有没有潜在的安全漏洞(如SQL注入、XSS)?性能表现是否符合预期?
第三部分:工程化与系统化进阶
当个人技巧成熟后,需要向工程化、系统化迈进,实现规模化应用。
3.1 上下文窗口管理策略
这里有一个常见的认知陷阱:模型“支持”长上下文,并不等于能“有效利用”长上下文。实验表明,当上下文长度超过32K tokens后,模型对早期信息的记忆和提取能力会显著下降。
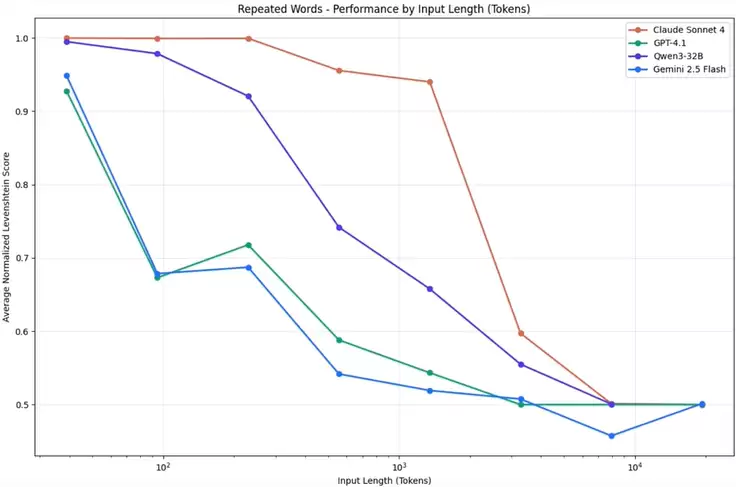
因此,必须主动管理:
- 对话分片:每个对话窗口只聚焦一个独立的功能点。任务完成后,将核心结论和代码沉淀到项目Wiki或文档中。后续的新任务基于这些沉淀的知识开启全新对话,而不是在旧对话里无限延续。
- 记忆管理:引入外部记忆系统(如Mem0、Zep),将项目核心知识(架构设计、关键决策、通用工具函数)持久化存储。所有关键决策点必须经人工确认后才存入记忆库,并定期清理过时的信息。
- 增量更新:与AI协作时,尽量只传递文件的变更差异(diff),而不是每次都发送整个文件。使用
git diff格式能让模型快速理解你具体修改了哪一部分。
3.2 MCP架构与工作流封装
MCP(模型上下文协议)架构是AI Coding走向工程化的核心。它把AI需要用到的各种工具和能力封装成标准化的接口。
典型的MCP工具可以分为以下几类:
| 类别 | 功能 | 示例操作 |
|---|---|---|
| 文件系统 | 读写代码文件、搜索代码、遍历目录 | read_file, search_code |
| 终端执行 | 运行Shell命令、执行脚本、构建项目 | execute_command, run_tests |
| 网络请求 | 调试API接口、检索在线文档、查询依赖信息 | http_request, fetch_docs |
| 数据库 | 查询Schema结构、验证数据、生成迁移脚本 | query_db, migrate |
| 版本控制 | 执行Git操作、查看代码差异、管理提交 | git_diff, commit |
基于MCP,就可以封装出高度自动化的工作流。例如,一个“安全重构”工作流可能包含以下步骤:1. AI先行分析代码结构;2. AI生成重构方案(不执行);3. 验证现有测试能否通过;4. 分步实施修改,每步后自动运行测试;5. 若测试失败,自动回滚到上一步;6. 生成完整的代码差异报告,等待人工最终确认。
3.3 项目Wiki与知识管理
为了让AI更好地成为项目的一员,你需要建设一个“AI友好型”的项目知识库。一个清晰的结构至关重要:
wiki/
├── 1.开始/ # 新手上路指南
│ ├── 快速开始.md # 5分钟运行Hello World
│ ├── 环境搭建.md # 依赖安装、IDE配置
│ └── 架构概览.md # 一张图看懂系统
├── 2.指南/ # 核心开发指南
│ ├── 添加新功能.md # 端到端开发流程
│ ├── 调试技巧.md # 常见问题排查手册
│ └── 性能优化.md # 基准测试与调优方法
├── 3.参考/ # 详细技术资料
│ ├── API文档/ # 自动生成的接口文档
│ ├── 配置手册.md # 所有环境变量与参数说明
│ └── 错误码表.md # 错误码对照与解决方案
└── 4.开发/ # 团队协作规范
├── 贡献指南.md # 代码规范、提交格式要求
├── 架构决策记录(ADR)/ # 所有关键设计决策及原因
└── 路线图.md # 项目未来规划
优化AI可读性的几个要点:优先使用机器易于解析的格式(Markdown, YAML, JSON);坚持“显式优于隐式”原则,明确写出所有默认值和边界情况;做到“示例驱动”,每个重要的概念或接口都配备一个可运行的最小化代码示例。
总结与展望
在实践AI Coding的过程中,有几个常见误区需要警惕:需求准备不完善,目标模糊就急于开工;过早追求代码的完美和优雅,忽视了快速验证;以及对AI的能力抱有不切实际的过高期望。
一个明显的趋势是,不少前沿公司已经开始调整技术岗位的划分逻辑,不再严格按Java/Python/前端等技术栈来分隔,而是转向设立更通用的“智能体工程师”(Agent Engineer)岗位。工作安排也更多是基于产品或项目任务来驱动。
这意味着,对于开发者而言,面对一个你不熟悉的技术栈,最重要的不再是精通其所有细节,而是建立起基本的概念框架和认知模型。然后,配合AI Coding的强大能力,去完成具体的开发需求。当然,这并非说基础不再重要。对于完全的门外汉,从零开始系统学习仍是必须的,只不过学习的曲线可以变得更陡峭——过去需要从0学到1才能干活,现在可能学到0.8,就能在实际业务的牵引下进行开发,并在过程中完成那剩下的0.2。开发,正在越来越像一场与AI紧密协作的深度对话。




