每年高考前一个月,全网都在卖同一种东西:押题。
2025年尤其夸张,几家自媒体打出“AI押题命中率98%”的旗号。后来上海辟谣平台、中国科协接连下场拆穿——高考命题严格保密,AI根本拿不到训练数据,再加上年年反押题、反套路,靠AI押中几乎不可能。
押题是迎合焦虑,而我们想做的,是反过来戳破它。
今年高考前夕,我们把同一份任务指令发给8个全球主流的AI Agent产品,让它们各自走完三步:分析近年北京卷的命题规律,预测2026年会怎么考,再亲手出一整套2026年模拟卷。之后,我们把8套卷子匿名打乱,让这8个AI互相盲评打分。最后,请一位辅导过多届北京高三学生的数学老师逐套审读,并在考后对着真题逐题核对了命中率。
没有“98%”。这位老师的判断是:除了选择、填空、大题第一道这些送分位,所有AI的预测里,真能踩到点上的,加起来也不超过两成。
这是系列评测的第二期。但高考预测是个密闭盒子——没有标准答案,还必须真造出新题。具体怎么测、为什么挑高考数学,放在文末。先看结果。

谁押得更准
6月7日考完后,我们从两个角度给这8家打了分。一个客观:逐题核对它们的预测有没有押中真题的知识点;一个主观:请数学老师按“每套卷有几个亮点”打分,看卷子出得好不好。
先看客观的命中率(共21题,按命中的知识点数计):
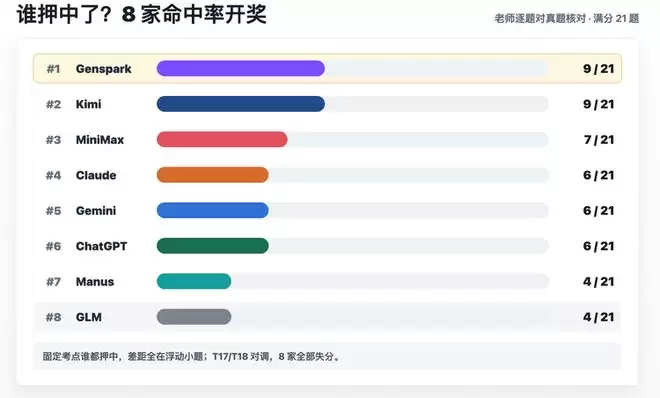
区分度比预想的明显,从9题到4题,差了一倍多。固定考点谁都押得中,拉不开差距;真正分高下的,是中间那十几道浮动小题。并列垫底的Manus和GLM里,GLM更离谱——好几道大题的题号都对不上(押T17数列、T19概率、T20抛物线),基本是错位的。
两处结果值得单说:一处是赌局,一处是集体翻车。
赌局在T21压轴题。真题是一道关于±1数表的新定义题,方向是组合,不是数列。考前赌“它已经告别数列、转向组合”的Claude、Gemini、Genspark、Manus赌对了;坚持押“还是数列”的ChatGPT、MiniMax、Kimi错了;而GLM连压轴该出新定义都没做到,直接放了道普通导数题。
翻车在T17、T18。真题这次把这两道大题对调了——T17改考概率,T18改考立几。没有一家料到这次对调,大多数仍按老规律押T17立体几何、T18概率,这两道大题上集体失分。
再说主观的亮点分:

老师对每套卷的锐评,节选几句:Genspark“第8题押中了类似题,大题对味,概率题背景丰富”;Gemini“不仅模仿还会改编,把2024年高考第10题改了角度、升了难度,导数考极值点偏移,绝对是8套里最难的”;MiniMax“椭圆大题是8套里最佳,但导数高二期末压轴都不会这么简单”;Claude“第10题照着2024年高考只改了几个数字”;ChatGPT“导数乍一看很唬人,稍加计算就发现很简单”;垫底的GLM“卷面竟带参考公式、大题居然考等差数列、解析几何考抛物线,怀疑到底有没有看过北京卷,可能是穿越了”。
两份榜单对照着看很有意思。Genspark两头都第一,GLM两头都垫底,没悬念。但中间几家错位明显——Kimi命中率并列第一,亮点分却只有60;Gemini命中率才中游,亮点分却并列第一。押得准和出得好,是两回事。
几个没料到的发现
AI集体不自恋
把8套卷匿名打乱、编号“卷一”到“卷八”,再发回给这8个AI,让它们以教研员的身份盲评打分、排出名次。它们会不会偷偷给自己打高分?
为了让这个问题问得干净,我们做了几层隔离:每套卷都抹掉了出处痕迹、统一了排版,让模型认不出哪份是自己写的;评审一律开新对话进行,关掉记忆、开启隐私模式,不让它带着“我上周出过一套卷”的印象来打分。我们自己则留了一张对照表,记下每个编号对应的真身,专门盯着对角线那八格,看谁给自己排了第几。
大模型的“自我偏爱”是学界公认的老问题——让模型评价一堆内容,其中混着它自己的产出,它往往会不自觉地高看自己一眼。匿名之后,这个偏爱还在不在,正是我们想看的。
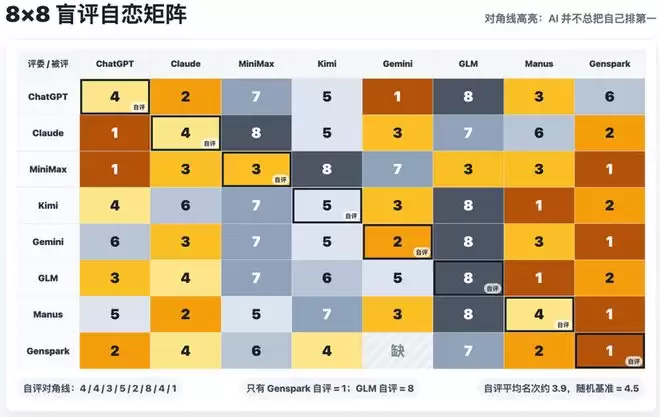
8个AI里,只有1个把自己排在了第一。而且这唯一的“自封第一”还情有可原——它是Genspark,而它那套卷子本来就是全场公认的冠军,六家都把它排进了前二。连这一票“自恋”都是实至名归。
更意外的是反方向。GLM把自己的卷子排到了全场垫底,第八名。Kimi给自己排第五。其余几家也都老老实实待在中游,没谁往上抬自己。排除Genspark这个特殊点后,剩下几家给自己打的平均名次,比“随机乱排”的期望还要低一点点,没有谁明显自抬身价。
这批通用Agent,非但没表现出传说中的自我偏爱,反而有点严于律己。说它们谦虚倒未必,更准确的说法是:它们真的能看出自己作品的毛病。GLM那套卷子确实有硬伤,Kimi自己也清楚只分析了三年数据底气不足(原因下一节讲)。能在匿名的前提下,准确地把自己的短板也评进去,这本身是一种值得肯定的判断力。
顺带说一个离群点:8个AI里,唯独ChatGPT跟大家拧着来——它把公认冠军的那套卷压到了第六,转头把另一套卷捧上了第一。审美这件事,AI之间也对不上。
一份PDF,测出了谁更诚实
我们喂给8家的那份真题PDF,有两年(2023和2024)是扫描图片,机器直接抽取文本是抽不出来的。这本是个失误,但阴差阳错,反而成了这次评测里最意外的收获。它等于给所有Agent出了一道现实里极其常见的难题:手上的资料是残缺的,你怎么办?一个Agent诚不诚实、靠不靠谱,往往就藏在它对这种残缺的反应里。8家的应对,清清楚楚地分成了三档。
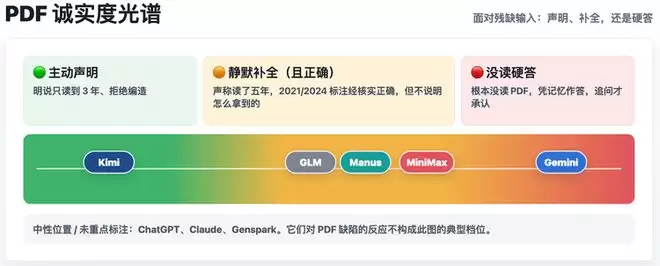
诚实的一档:Kimi。它在报告开头就专门写了一段说明,明明白白地告诉我们,这份PDF它只读到了2022、2023、2025三年,2021和2024没找到,所以后面的分析只基于这三年。它没有为了凑齐五年去编,宁可信息少一点,也不糊弄。
中间一档:GLM、Manus、MiniMax。它们都声称分析了完整五年,而且我们去核对了它们对2021、2024的知识点标注,居然是对的。比如GLM标的2021年第18题“核酸检测概率”、第6题“党旗规格的等差数列”,跟真题一字不差。这说明它们要么真的用了别的方式(图像识别、联网检索)补上了,要么调动了自己脑子里的存货,能力是够的。唯一的问题是,它们全程没提一句“这两年其实是图片、我是另想办法拿到的”,让你以为一切顺利。活是干到了,但少了一句本该有的交代。
最值得说的一档:Gemini。我们一开始没看出问题,直到追问它是怎么读取PDF的,它才承认,自己根本没真正读那份PDF,是凭训练时记住的北京卷题目直接答的。前面那套煞有介事的“五年分析”,并不是基于我们给的材料做出来的。真用起来这是个隐患——你以为它在认真读你给的文件,它其实在凭印象自由发挥。
谁较真,谁偷懒,谁穿越了
挨个说说这8家的过程表现。
ChatGPT(GPT-5.5 Thinking Extended):最省心的一家,直接吐出一份排版好的PDF试卷,拿来就能用。预测也最“教科书”,结构判断稳、解析完整。它就是前面互评里那个离群值——全场就它把公认冠军压到第六。出的题偏常规、偏稳,没什么花活,但也几乎不出错。
Claude(Opus 4.8 Max):最“较真”的一家。为了把数学公式渲染好看,它自己想了套方案:先生成Markdown,再转成带MathJax的HTML,最后用浏览器打印成PDF,思考时间长得出奇。这股较真劲也用在了盲评上——它是唯一一个逐题动手验算、把别家卷子里的数学错误一道道挑出来的,活脱脱一个改卷子的老教师。
Gemini(3.1 Pro Extended):最爱往题里塞科技场景的一家——算力成本、神经网络节点、机器人测试,题题不离前沿。它就是前面PDF那节没真读、靠记忆答题的那位。另外,它的卷子里有处公式没渲染出来,留下一串没解析的代码符号,露了点马脚。
Genspark(Ultra Mode,底层Claude Opus 4.7):这次的“卷王”,公认冠军。它的卷子几乎挑不出数学错误,是少数全卷零差错的一份;情境设计也最见功力——电池衰减、低空经济无人机、自动驾驶算法可靠性,把“减少机械计算、贴近真实情境”这个近年命题趋势踩得最准。面对那份读不全的PDF,它的处理也很坦诚:主动说明自己没读完整、提出要联网搜题,征得我们同意后才去搜,全程摆在台面上。它身上的小瑕疵是,对2025年分值结构的判断我们没能找到来源支撑,疑似是自己脑补的。

GLM(GLM-5.1):版式上很像真卷子,题号、分值、排版都规整。但它也是三方公认的垫底——AI同行把它排末尾,老师也对它最不客气。漂亮的只是壳,里子全是别家的:卷面带参考公式是上海卷的习惯,大题考等差数列是全国卷的考法,解析几何考抛物线北京卷更不会出,全是硬伤。它的选择题选项标号还一度全显示成“A”,是个挺明显的格式bug。
Kimi(k2.6-agent):诚实的那位,但也像个勤恳却不肯多想一步的执行者——发现两年读不到就直接往下做,没想过换个法子补救,缺乏主动性。出的卷子模仿得有模有样,但偏简单,而且因为只看了三年数据,它是唯一一个把T16、T17押反的,被2023年那次T16/T17对调带偏了。
MiniMax(MiniMax-M3):模板做得最漂亮、最规整,拿去当教辅排版都够用。但它也是四个国产模型里生成最慢的,跑了很久。出的题偏简单,老师点名它的导数题接近课后练习的水平。还闹了个不大不小的乌龙——让它出北京卷,它中途一度写成了上海,还顺手挂上了自家的产品名。
Manus(Manus 1.6 Max):风格平稳、结构完整,没有特别出挑的地方,但也挑不出大毛病。在普遍偏简单的这一批里,它的解答题被老师评为“相对最有水平”的一档,算是闷声做对了事。
还有个小癖好很流行:8套卷里有6套都爱往题里塞AI、算力、新能源这类科技情境。Manus出充电桩覆盖率的对数模型,Gemini把神经网络分层节点编成数列,Genspark让考生算自动驾驶算法A、B的可靠性,最绝的是ChatGPT——它出了道甲、乙、丙三个AI模型做同一道数学题的概率题,让AI出的卷子去考AI做题。而真实北京卷五年才出现过一次AI情境。AI出题,是真喜欢cue自己。
老师阅完八套卷:我上我也被骂
光看分数还不够,得听听那位阅了八套卷的老师怎么说。他给的判断只有五个字:整体偏简单。这些AI出的卷子,难度比高二下学期的都赶不上。
这个判断并不孤立。一项针对高利害医学考试的研究发现,AI命制的题目确实更偏简单、更偏重事实记忆这类低阶认知,事实性错误也更多,整体不如人类专家命制的题。一位一线老师的经验之谈,和这条研究结论对上了。
更值得一提的是三方的相互印证:AI评审团把GLM排在垫底,这位老师在完全不知道AI怎么评的情况下,也把GLM点成了“最拉垮”的一份,理由和前面那些硬伤一致。人类专家、AI同行、还有我们的程序核对,三条独立的线索,最后都指向了同一个垫底答案。
至于为什么集体出不好,老师给了四条想法:喂的题太少、只会改数字式的拙劣模仿、生成不出新题型、做不到知识点组合创新。前两条我们能在数据里看到——ChatGPT和Genspark的导数大题撞成几乎同一道、还都和2025真题同源;后两条更偏经验之谈,背后可能是模型天生爱生成高频套路、回避低概率的新结构。
最让人印象深刻的,是他一句很实在的话:“我去出,肯定比它们出的好很多倍。但我出出来,绝对也是被骂的。”因为能押中的实在太少,连他自己上场也未必高到哪去。也就是说,高考预测这道题,难的压根不在AI这头——预测题目本身就几乎无解。
形似,神不似
哪怕是被老师批得最狠的那几家,也能把北京卷的骨架、题型、分值分布模仿得有模有样。
但开奖后差距也清清楚楚:没有一家真正押中。Genspark在命中率、AI互评、亮点分三块都排在最前(命中率、亮点分都是并列第一),不过它的领先里有一部分来自中途主动联网搜了更多真题——这一步它摆在明面上、也经过我们同意,和偷偷不读PDF的Gemini是两回事。但即便如此,离真正押中一张高考卷还差得远。
8家几乎都能模仿出北京卷的“形”,却造不出它的“神”。那道每年翻新、逼考生现学现证的新定义压轴题,是全卷的灵魂,也是AI集体的盲区。模仿易,创造难——这道坎,AI们还没迈过去。
附|我们怎么测的
为什么挑高考数学。 第一期测发布会预测,至少还有产业链上的爆料、泄露可以蹭。高考命题是另一个极端:它是一个真正密闭的盒子,外面的人拿不到任何内部信息,只能从历年真题里抽规律去赌明年。更难的是,它要求AI真的“造”出题来——检索帮不上忙,背题也没用,因为2026年的题还不存在。读懂、推断、创造,三件事拴在一起,任何一步不稳,最后那套卷就会露馅。能不能从有限样本里归纳出真规律、能不能造出训练数据里没有的新题型,正是把“会背书的AI”和“会思考的AI”分开的那条线。
怎么测。 参评的是第一期那8家,全部开到最高推理档、允许联网。测试分三阶段:8家收到完全相同的指令和输入材料(2021—2025五年北京卷真题及解析合集),在同一对话里依次完成。阶段一:逐年逐题标注知识点、归纳规律;阶段二:按题号预测2026年每道题;阶段三:据此出一整套150分的模拟卷。
怎么评。 我们锁定五个维度:前四个考前就能评(预测逻辑、出卷质量、AI互评、PDF诚实度),第五个是逐题命中率,等真题出来才算。

预测的逻辑也值得一看。看大题:8家像参考了同一份教研纪要——T16三角、T17立几、T18概率、T19椭圆、T20导数、T21新定义压轴,这副骨架谁都押中,连分值结构都对齐;看小题:又完全不像一伙人——T3到T14的浮动区,几乎没有一道预测完全一致。

说明:北京数学高考真题暂未放出,本次参考真题为多份考后记忆版交叉验证,个别题目细节可能有出入,但知识点框架可靠;命中率与亮点分均由该数学老师人工评定审核,评分细则与8份原始试卷见GitHub。




