这个问题看似简单,实际上触及了AI产品体验的核心痛点。如果你的产品也曾遇到以下情况,那么今天的方案会非常实用:
- 用户网络波动导致流式输出中断。
- 浏览器标签页被误关闭,重新打开后对话记录还在,但刚生成的内容丢失了。
- 长任务生成到一半,服务端因负载触发自动扩容,连接被重置。
- 用户主动刷新页面想保存内容,数据却没了。
流式生成的核心价值在于“快速响应”,但如果“快”以不稳定为代价,用户体验就会从“惊艳”转向“崩溃”。因此,打造一套可靠的断点续传机制,是提升AI产品竞争力的关键举措。
接下来,我们将系统性地拆解这个问题,并提供一个专业、可落地的解决方案。
一个底层的背景:为什么流式生成天生脆弱?
要理解“中断恢复”的重要性,首先需要看清传统流式架构的几个固有弱点。
1. 纯内存状态:一旦中断全部丢失
在标准的SSE或WebSocket流式架构中,生成状态通常只存在于三个位置:客户端内存、服务端内存和网关连接。问题在于,这三层都是易失性存储,任何一层连接断裂,状态就会彻底消失。
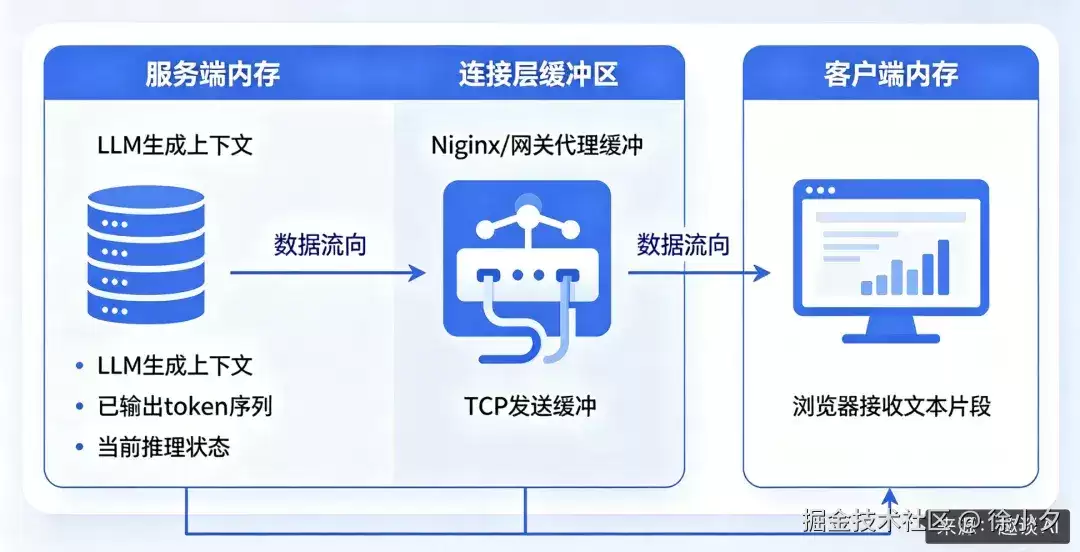
更棘手的是,大语言模型的生成具有强烈的顺序依赖性——第100个token的生成依赖于前99个token的上下文。这意味着它无法像下载文件那样“从断点开始”,一旦中断,几乎需要从头再来。
2. 大模型的“不可重入”性
这里有一个反直觉的事实:大多数AI生成请求不是幂等的。即使将用户的Prompt原封不动重新发送,由于模型的温度参数和随机采样,第二次生成的结果很可能与第一次完全不同。
这意味着“重新生成”不等于“恢复”,而是“替换”。对于长文本、代码生成等场景,用户往往对第一次生成的“中间状态”已经有了认知预期。如果中断后返回一个全新的结果,相当于否定了用户已经阅读并认可的那部分内容。
3. 业务成本的损耗
从商业角度看,一次中断的代价远不止糟糕的体验:
- 算力浪费:生成到90%中断,这90%的token消耗已经产生成本,但用户没能看到完整结果。
- 上下文窗口浪费:恢复时如果从头重传历史消息,会快速消耗宝贵的上下文长度。
- 用户流失:数据显示,经历过一次“长生成中断”的用户,其7日留存率可能会有显著下降。
综合来看,结论很清晰:流式生成必须像视频播放一样,支持“断点续传”。
第一问:宏观思路——如果让你一句话概括解决方案,你会怎么说?
一句话概括就是:让生成过程像视频播放一样支持断点续传。核心在于,在生成过程中持续“落盘”状态,而不是等到结束才保存。
具体来说,可以设计一个三层状态恢复模型:
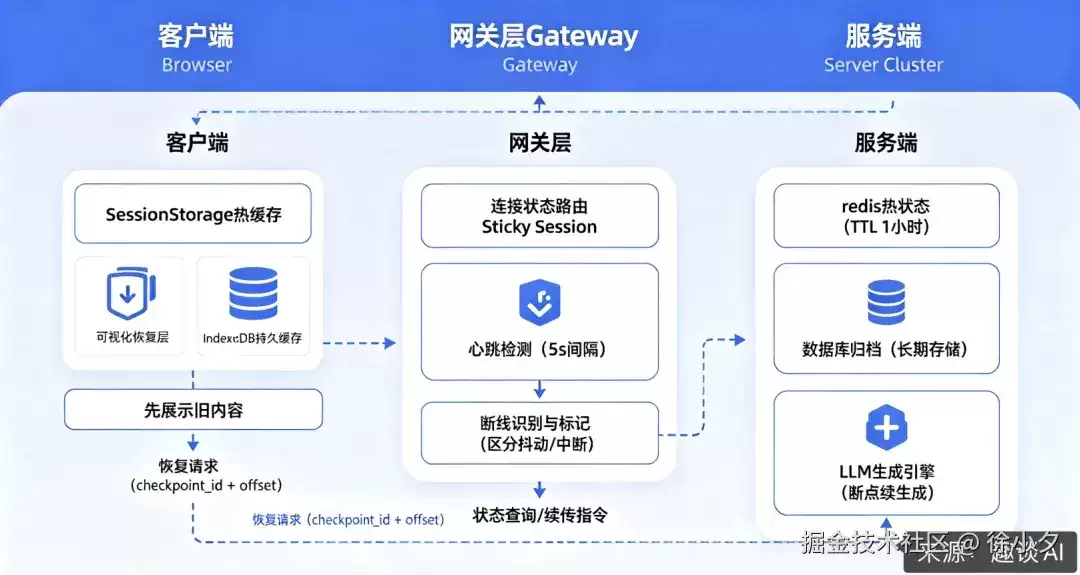
- 客户端缓存层:利用SessionStorage做热缓存,IndexedDB做持久缓存。页面刷新后,优先让用户直接看到已生成的内容。
- 网关缓冲层:负责连接状态路由、心跳检测,精准区分“网络抖动”和“真正中断”。
- 服务端持久层:用Redis保存热生成状态(包括KV Cache),再用数据库做长期归档。
三层之间通过 checkpoint_id、offset、hash 三元组串联,确保恢复时的幂等性和数据一致性。
在实现时,需要遵循几个关键原则:
1. 渐进式持久化
不要等到生成结束才保存。可以每生成一个“逻辑段落”(比如每512个token或每个自然段落结束),就触发一次状态快照。这样做的好处是,即使对话中断,丢失的也仅仅是最后一个段落,而非全部内容。
2. 客户端是第一恢复“数据源”
优先从客户端缓存中恢复已接收内容,实现“所见即所得”的视觉反馈。服务端只需补充“未接收的部分”。当然,服务端缓存层可以作为持久化兜底。
3. 幂等性设计
通过 request_id、checkpoint_id、offset 三元组,确保同一个恢复请求永远产生确定性的续传结果,这是保证系统可靠性的基石。
第二问:架构深挖——服务端怎么知道该从哪恢复呢?
关键在于断点标记协议。可以在SSE的每个数据包中都嵌入 checkpoint 元信息。

客户端每次收到数据块时,都会把这个 checkpoint 存到本地。当需要恢复时,在请求头中带上以下标识信息:
X-Checkpoint-ID: 本次生成的唯一标识X-Client-Offset: 客户端最后收到的token数量X-Content-Hash: 本地缓存内容的校验和
服务端收到这些信息后,会先去Redis查询对应的 checkpoint_id。如果存在且未过期,则进入续传流程。
如果客户端的缓存损坏,hash校验不通过怎么办?这时应该退回到上一个可靠的 checkpoint 重新发送数据。宁愿多传一点重复内容,也要确保恢复后的内容连贯、无误,绝不能出现断层或乱码。
第三问(状态机设计):AI生成到一半,突然断了,服务端的状态该怎么处理?
连接断开时,LLM可能还在推理。此时直接停止生成并非最佳选择。一个更优的方案是设计一个六状态生成状态机。

状态转换规则如下:
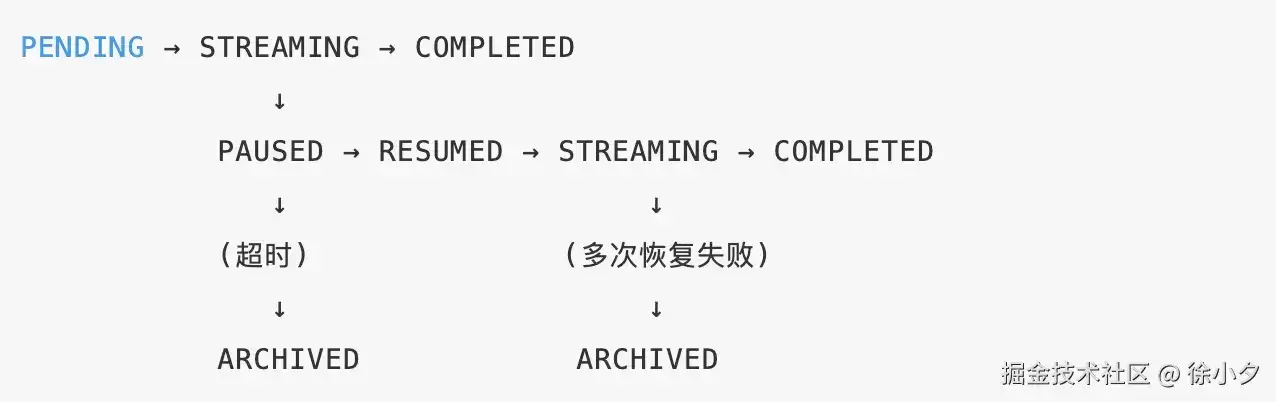
具体思路是:当网关层检测到连接中断(例如连续3次心跳丢失)时,不应立即销毁状态,而是将状态机切换到 PAUSED(暂停) 状态。此时需要做三件事:
- 冻结生成上下文:将当前的对话消息、KV Cache以及已输出的token序列进行序列化。
- 写入Redis:使用
SETEX generation:chk_xxx 3600命令,设置一个较短的有效期(如1小时)。 - 异步归档:同时将状态写入数据库,作为持久化备份保留数天,以防Redis数据被淘汰。
这个设计的核心价值在于:在“网络抖动”阶段(如心跳延迟大于2秒)就提前进入“预暂停”状态并冻结上下文。因为LLM推理一直在消耗算力,如果等到确认断连再冻结,可能已经有大量新生成的内容无法送达客户端,造成算力浪费。
如果Redis挂了怎么办?Redis是热存储,挂了就从数据库冷存储恢复。虽然延迟会高一些(几十到几百毫秒),但至少不会丢失状态。此外,可以对KV Cache进行INT8量化压缩,减少约70%的Redis内存占用,避免高峰期出现内存溢出。
第四问:客户端策略——页面刷新了,用户凭什么能看到旧内容?
答案是:客户端双保险缓存。

恢复时的优先级顺序是:内存 > IndexedDB > 服务端冷存储。
页面打开后,前端首先读取IndexedDB,立即将旧内容渲染到对话区域,同时向服务端发送恢复请求。用户看到的效果是:内容已经在了,光标在文本末尾闪烁,新的文字继续流出。用户根本感知不到这是一次恢复,只会觉得是“暂停了一下”。这种无缝体验对用户非常友好。
更健壮的实现可以参考以下伪代码:
# 伪代码示意
class StreamingCheckpointManager:
def __init__(self):
self.redis = RedisClient()
self.db = Database() async def freeze_generation(self, checkpoint_id: str, context: GenerationContext):
# 1. 序列化生成状态(包含KV Cache和token序列)
serialized = self.serialize_context(context) # 2. 写入Redis热存储(1小时TTL)
await self.redis.setex(
f"generation:{checkpoint_id}",
ttl=3600,
value=serialized
) # 3. 异步写入数据库冷存储(7天TTL)
asyncio.create_task(
self.db.archive_generation(checkpoint_id, serialized, retain_days=7)
) async def resume_generation(self, checkpoint_id: str, client_offset: int):
# 1. 先查Redis
state = await self.redis.get(f"generation:{checkpoint_id}") # 2. Redis未命中,查数据库
if not state:
state = await self.db.get_generation(checkpoint_id)
if not state:
raise CheckpointNotFound("生成记录已过期或不存在") # 3. 反序列化上下文
context = self.deserialize_context(state) # 4. 如果客户端offset小于服务端已生成量,先补发历史内容
if client_offset < context.output_length:
await self.replay_history(client_offset) # 5. 如果生成尚未完成,继续流式输出
if context.state != GenerationState.COMPLETED:
await self.continue_generation(context)
如果用户换了设备呢?比如手机端中断,在电脑上打开同一会话。这需要更业务化的设计,可以将 checkpoint 与用户账号绑定,而非设备。当电脑端检测到该会话存在 PAUSED 状态的 checkpoint 时,可以提示用户:“检测到您在手机端有未完成的生成,是否继续?” 这对跨设备协作场景非常有用。
第五问:极限边界场景探索
接下来探讨几个边界情况,考验方案的鲁棒性。
场景一:恢复时,已生成的内容过长,重新组装Prompt会导致上下文窗口溢出怎么办?
可以对已生成内容做智能摘要压缩,只保留关键结论作为上下文,而不是全文重传。可以在Prompt里区分 history_summary 和 continuing_context,明确告知模型“这是前文摘要,请基于它继续完成”。这是一个实用且高频的解决方案。
场景二:LLM有随机性,恢复后续写时,风格、人称前后不一致怎么办?
可以在恢复Prompt里注入风格锚点,明确告知模型“请保持前文的第一人称叙述风格”。同时,checkpoint里记录了生成时的 temperature 和 top_p 参数,恢复时严格复用这些参数,能在最大程度上保证一致性。
场景三:如果模型版本升级,旧版的KV Cache新版加载不了,如何解决?
可以在序列化时加入模型版本标识和序列化协议版本。恢复时严格校验兼容性。如果不兼容,则自动降级为“文本级恢复”——即从文本断点重新调用模型生成,而不是加载推理状态。虽然会多消耗一些算力,但保证了系统的健壮性,不会崩溃。
最后一问:如果让你给团队落地,优先级该怎么设计?
假设团队资源有限,可以分三步走,逐步推进:
第一步:实现客户端IndexedDB缓存 + 服务端文本级断点续传。先不涉及复杂的KV Cache序列化,只记录已生成的文本和offset。恢复时,从文本断点重新调用模型生成。这一步投入最小,但能解决80%的用户痛点,是性价比最高的选择。
第二步:引入Redis热状态存储,实现KV Cache的序列化与恢复。这是性能拐点,能将恢复后的首token延迟从秒级降低到毫秒级,用户体验有质的飞跃。
第三步:完善网关层的心跳检测、实现多端同步、制定分级TTL策略。这是稳定性拐点,能让方案真正扛住生产环境的高并发流量,成为一个企业级的高可用特性。
为什么先做客户端缓存,而不是先优化服务端?因为用户体验的即时提升永远是第一优先级。客户端方案成本低、见效快,能最快让用户感受到变化,比先做深度的服务端性能优化更直观。
总结与思考
“流式生成状态恢复”是一个能充分体现工程深度和产品思维的问题。在技术面试或方案评审中,一个清晰的回答框架是:场景痛点 → 架构分层 → 协议设计 → 边界兜底 → 落地优先级。
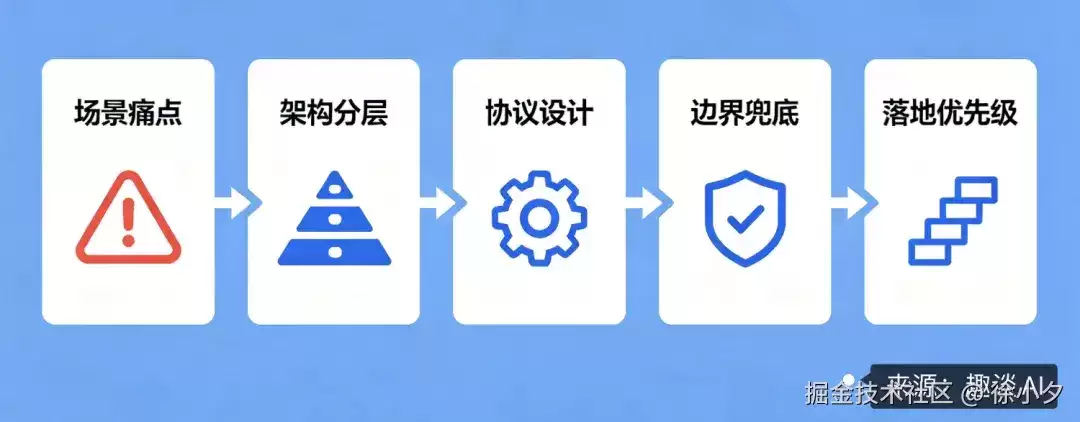
这个结构能帮助你将技术方案讲得既有广度,又有深度,从问题本质出发,最终落到可执行的路径上。希望这套思路能为你构建更稳定、更可靠的AI产品体验提供一些启发。




