为什么GLM-4.5是开发AI应用的首选
时间:2026-06-13 17:25
智谱AI推出的GLM-4 5采用混合专家架构,总参数3550亿、激活320亿,在12项基准测试中排名第三,推理、编码与智能代理能力均达第一梯队。仅需8块H20芯片即可运行,性能比肩专有方案而成本减半,支持多种微调与本地部署,为开发提供灵活透明的企业级选择。
智谱AI(Z.ai)的GLM-4.5一经推出,就在AI圈里掀起了不小的波澜——一个开源模型,直接对标专有解决方案,这背后的意义不言而喻。对于开发者来说,选择生产环境的AI模型越来越难:既要推理能力强,又要编码靠谱,还得有智能袋里功能。而GLM-4.5的出现,恰好把这几个需求都捏在了一起——开源、灵活、透明,同时还能输出企业级的性能。
GLM-4.5 架构解析
GLM-4.5在架构上的思路非常清晰:混合专家(MoE)设计,总参数3550亿,但每次只激活320亿。这意味着什么?计算效率上去了,性能也没落下,两者平衡得相当好。
更值得一提的是,它融合了先进的混合推理机制,在长上下文、多轮交互的场景中表现稳定。这种设计理念,说白了就是在追求顶尖性能的同时,也考虑到了实际怎么部署、怎么用,避免了一味堆参数导致落地困难的尴尬。相比传统Transformer架构,GLM-4.5通过创新的注意力机制和优化的参数分配策略,效率提升相当可观。
重新定义卓越的性能基准测试
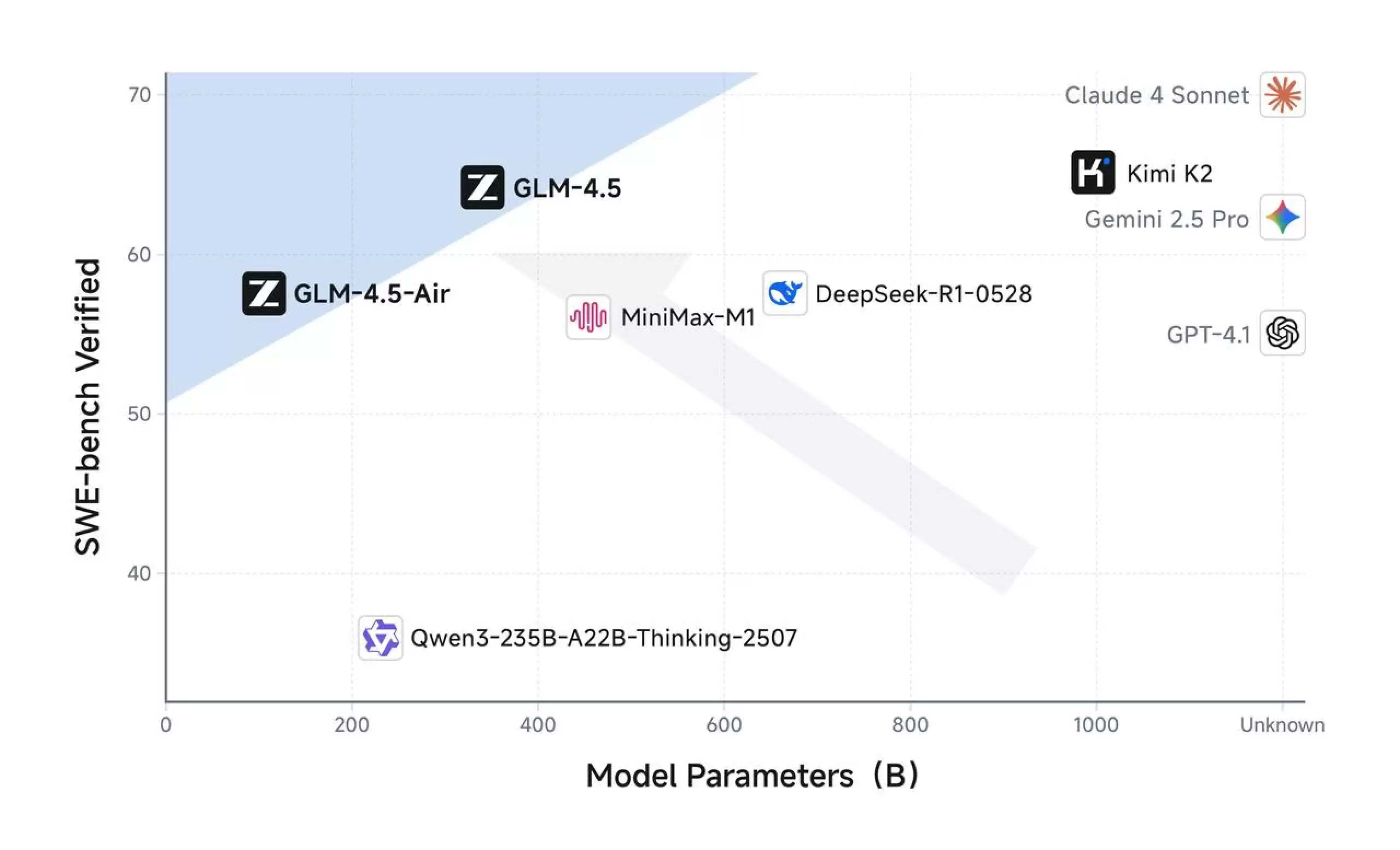
来看一组数据:GLM-4.5在12项行业标准基准测试中拿到了63.2分,把专有和开源模型都排了个序,它排在第三。这意味着在推理、编码、智能袋里这些关键领域,它已经站到了第一梯队。
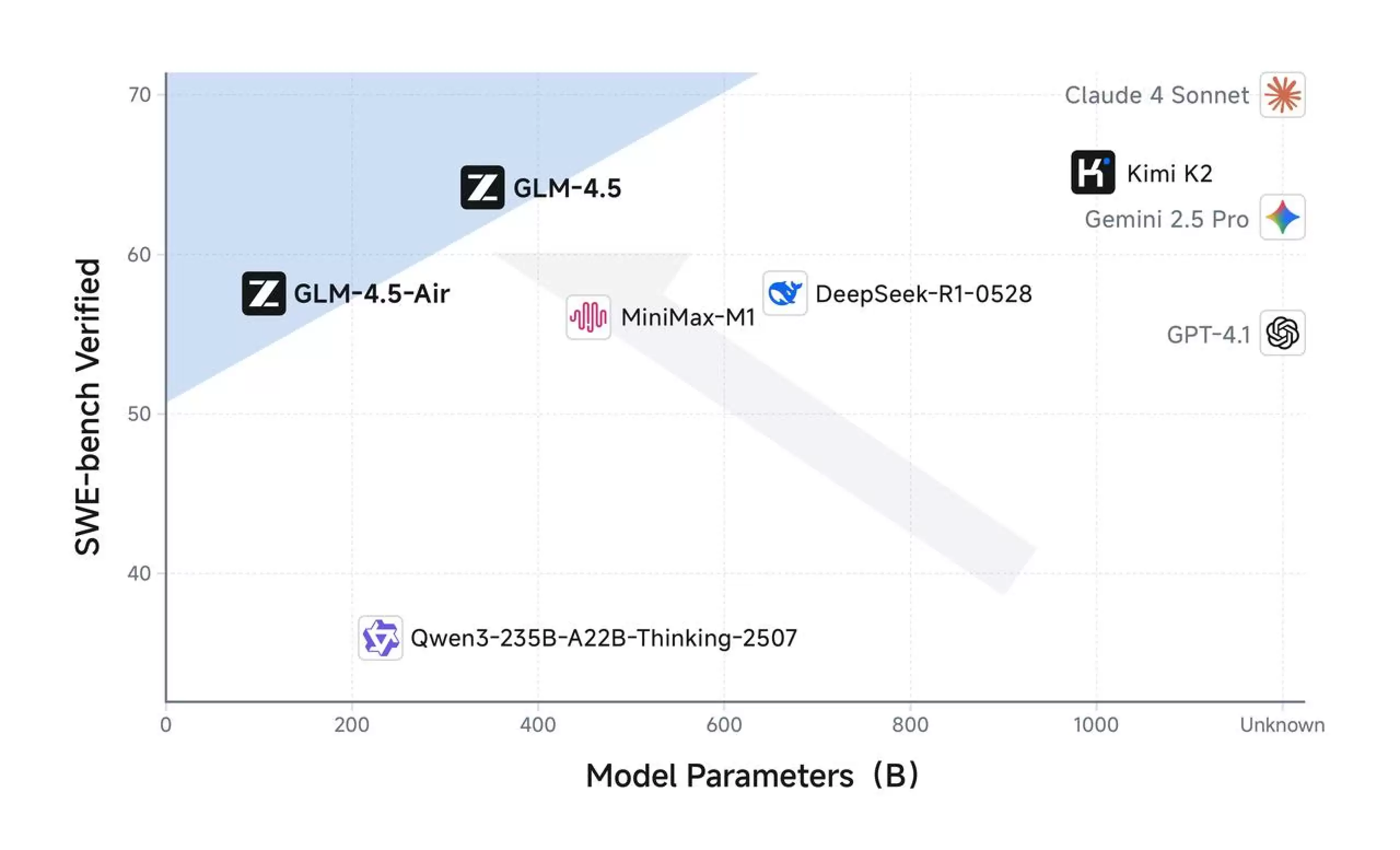
进一步拆解基准数据,GLM-4.5在特定技术领域的优势非常突出,尤其在数学推理和软件工程任务上,给开源模型立了个新标杆:
- TAU-Bench 中得分 70.1%
- AIME 24 中达 91.0%
- SWE-bench Verified 中为 64.2%

这种全面的评估方法,能确保性能指标真正反映实际应用场景,而不是单为了刷分。做架构决策时,开发者也就不用太担心“纸面数据好看,落地就翻车”的问题。
与行业领先者的对比分析
把GLM-4.5和其他主流模型摆在一起看,结论很清晰:性能上已经逼近专有方案,但透明度和定制灵活性,那可是专有模型给不了的。更关键的是,它只需要8块英伟达H20芯片就能跑——比DeepSeek的硬件需求少了一半。基础设施成本直接砍半,这对很多团队来说,吸引力太大了。这种“性能-成本比”的突破,彻底改变了企业部署AI的策略,让小型团队和企业也能触碰到以往只有大厂才敢用的高级AI能力。
适用于现代开发的高级编码能力
编码方面,GLM-4.5支持Python、Ja vaScript、Ja va、C++、Go、Rust等主流语言,覆盖面很广。但更关键的是,它不仅仅能写代码,还理解软件工程的那些套路——生成代码的时候,会自动遵循最佳实践和行业标准。内置的高级调试功能还能及时发现潜在问题并给出优化建议,一定程度上能缩短开发流程。
智能袋里编码功能可以说是AI辅助开发的一次升级——开发者可以借助它来完成复杂重构、架构设计决策、自动化测试等任务。这些任务本身就需要对代码关系和依赖有深度理解,GLM-4.5能做到这一点,确实值得关注。
与开发工作流的无缝集成
现代开发环境对AI模型的要求很直接:你能跟现有工具链无缝衔接吗?GLM-4.5的API兼容性和灵活部署选项,让它能轻松融入主流开发平台和持续集成系统。更重要的是,它懂得理解项目上下文,跨多个文件和模块保持一致性,这对大型软件项目来说尤其重要。上下文感知能力还延伸到编码规范、架构模式和特定领域需求的理解上。
当GLM-4.5与Apifox的全面API测试框架结合时,开发者能系统化地验证它在不同场景下的代码生成能力,确保整个开发生命周期中质量标准的一致性。
用户交互的智能袋里能力
GLM-4.5在智能袋里功能上下了功夫,包括袋里编码、深度搜索和通用工具使用,为自主任务执行和复杂工作流自动化打开了新空间。它能把复杂的请求拆解成可管理的子任务,系统化执行后再把结果整合为连贯的解决方案。
此外,模型在长交互过程中保持上下文的能力,使其能应对复杂的多步骤问题解决场景。在需要迭代优化、探索性分析和自适应响应生成的场景中,这一点格外实用——应用因此能提供更智能、更具响应性的用户体验,适应不断变化的需求和上下文。
工具集成与外部系统连接能力
GLM-4.5的工具使用能力,不只是调个API那么简单。它能理解工具文档、自动生成合适的参数配置,遇到错误还能优雅处理——这在复杂集成场景里,省了不少事。智能工具选择机制还能根据上下文、需求和可用资源,为特定任务选择最优工具,大大降低了构建需多系统集成的复杂AI应用的难度。强大的错误处理和恢复机制,也确保了生产环境中的稳定性——外部依赖出点小问题,模型不会跟着掉链子。
技术部署考量因素
成功部署GLM-4.5,需要仔细考虑基础设施需求、扩展策略和性能优化技术。这个模型每单位计算成本的性能,是同类能力稠密模型的8倍,能在多样化部署场景中实现高效的资源利用。混合MoE架构支持灵活的扩展策略,能适配不同的工作负载模式和资源约束。企业可以采用渐进式扩展方案,与使用量增长和预算需求保持一致。部署灵活性也体现在多种托管环境中——云平台、本地基础设施,或者平衡成本、性能和数据隐私需求的混合配置,都行得通。
内存与计算优化策略
有效部署GLM-4.5,需要复杂的内存管理和计算优化技术,才能最大化性能、最小化资源消耗。它的架构支持多种优化方式,包括量化、剪枝和动态批处理策略。智能缓存机制能显著提升频繁访问模式的响应速度,降低整体计算开销。当GLM-4.5与Apifox测试框架结合部署时,开发者能系统评估不同优化策略对模型性能的影响,为特定用例确定最优配置。
API 设计与集成模式
GLM-4.5的API设计遵循现代RESTful原则,同时融入了流式响应、批处理和有状态对话等高级功能。全面的API文档为各种集成模式的实现和边缘场景的处理提供了清晰指引。API的灵活性使其能适配不同的应用架构和使用模式,无需对现有系统做重大修改。向后兼容性则确保了当前使用其他语言模型的应用能平滑迁移。强大的认证和授权机制提供了企业级安全功能,能满足敏感应用和受监管行业的合规要求。
速率限制与性能优化
生产级API实现需要复杂的速率限制和性能优化策略,以确保可靠的服务交付和最优的资源利用。GLM-4.5的API包含可配置的速率限制机制,能适配不同的使用模式和订阅等级。智能负载均衡和请求排队系统,即使在峰值使用期也能保持稳定的响应时间,对流量模式不可预测或存在季节性变化的应用来说,这一点尤其重要。
微调与定制化能力
GLM-4.5支持多种微调方式:
- 用于高效训练的LoRA(低秩适配)
- 实现最大定制化的全参数微调
- 用于对齐的RLHF(基于人类反馈的强化学习)
这些选项让企业能根据特定领域和用例调整模型行为。全面的微调文档和示例脚本加速了定制过程,同时确保遵循最佳实践。模块化架构允许针对特定能力领域进行定向优化,而不影响模型整体性能。微调基础设施支持多种数据格式和训练方法,使企业能有效利用现有数据集和领域专业知识。
特定领域适配策略
成功定制GLM-4.5,需要战略性的领域适配方法,在专业化与通用能力保留之间取得平衡。它的架构支持增量学习,能在融入新知识的同时,避免对现有能力的灾难性遗忘。复杂的评估框架能系统评估微调在不同指标和用例中的有效性,这些工具对追求特定应用最优性能的企业来说不可或缺。协作式微调环境促进了团队级别的模型开发,使企业内部不同定制项目能共享知识。
安全与隐私考量
开源带来的好处是什么呢?安全审计可以全面展开,隐私需求也能定制。企业可以加安全层、改数据处理流程,确保合规。尤其是本地部署这个选项,让那些处理敏感数据或运营于受监管行业的企业,对数据控制权更有底——完全避免第三方数据访问或留存政策带来的顾虑。透明的架构也让安全团队能理解模型行为、识别潜在漏洞,并根据特定威胁模型和风险状况实施适当的缓解策略。
数据治理与合规性
在企业环境中部署GLM-4.5,需要仔细考虑数据治理需求和合规义务。模型的灵活性使其能实现复杂的数据处理政策,与企业需求和监管要求保持一致。全面的日志和审计功能,能清晰展示模型使用模式、数据访问模式和决策过程,为合规报告和安全监控提供了有力支持。
总结
总的来说,GLM-4.5在开源AI领域算是一次飞跃——性能出色,同时保持了开源模型该有的灵活和透明。在推理、编码和智能袋里任务中的全面能力,使其成为构建下一代智能应用的理想基础。
在实际开发中,如果把GLM-4.5和Apifox这样的全面API测试平台配合起来,效果会更明显:GLM-4.5生成API接口代码后,Apifox能自动导入接口规范,生成覆盖正向、异常场景的自动化测试用例;想快速验证模型生成的业务逻辑?Apifox的Mock服务能基于接口规范生成模拟响应,无需等待后端部署;Apifox还能监控GLM-4.5驱动的API接口性能,一旦响应延迟或错误率超标就告警,帮助团队快速定位问题根源。通过这种“生成-测试-监控”的闭环,GLM-4.5的开发价值得以最大化,助力团队更高效地交付智能应用。